正则表达式是一种字符串匹配利器,可以帮助我们搜索、获取、替代字符串。它是一种计算机科学的概念,不单单属于某种语言,正则表达式可以在Python、JavaScript、Java等语言中广泛使用。
目录
1.什么是正则表达式?
- 正则表达式(英语:Regular Expression,常常简写成RegExp),又称为正则表示式、正则表示法、规则表达式、常规表示法;
- 正则表达式使用单个字符串来描述,匹配一系列匹配某个句法规则的字符串;
- 很多程序设计语言都支持利用正则表达式进行字符串操作。
2.JavaScript中的正则表达式
在JavaScript中,正则表达式使用RegExp类来创建,但也有对应的字面量的方式:正则表达式主要由两部分组成:模式(patterns)也可以理解为匹配规则和修饰符(flags)
const re1 = new RegExp("hello", "i")
//使用RegExp类创建正则表达式 "hello"是模式 "i"是修饰符
const re2 = /hello/i
//使用字面量创建正则表达式 3.正则表达式的使用方法
有两种使用方法:
- 可以使用正则对象(RegExp)上的实例(exec和test)方法;
- 使用字符串(String)的(match、matchAll、replace、search、split)方法,传入一个正则表达式。
3.1.正则对象的实例方法
一个在字符串中执行查找匹配的 RegExp 方法,它返回一个数组(未匹配到则返回 null)。
let message = "hello ABC, abc ,ASbc, AABC"
const re1 = /abc/ig
console.log(re1.exec(message)) 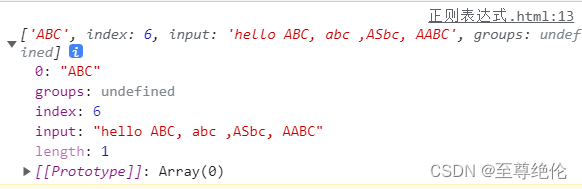
一个在字符串中测试是否匹配的 RegExp 方法,它返回 true 或 false。
let message = "hello ABC, abc ,ASbc, AABC"
const re1 = /abc/ig
console.log(re1.test(message)) //true3.2.字符串的方法
let message = "hello ABC abc ASbc AABC"
const re1 = /abc/ig
const result = message.match(re1)
console.log(result) 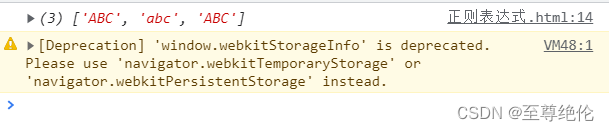
matchAll正则必须加g修饰符。
let message = "hello ABC abc ASbc AABC"
const re1 = /abc/ig
const result = message.matchAll(re1)
console.log(result)
返回的是一个迭代器,是可迭代的,使用for of循环遍历。
for (const item of result){
console.log(item)
}
4.修饰符flag的使用
常见的修饰符有三个:
const re1 = /abc/ig5. 规则
5.1.字符类
◼字符类(Character classes)是一个特殊的符号,匹配特定集中的任何符号。
let message = "hello123 ABC545 abc6546 AS56346bc AA6546BC"
const re1 = /\d/ig
const result = message.match(re1)
console.log(result) 
let message = "hello123 A BC545 abc6546 AS56346bc AA6546BC"
const re1 = /\s/ig
const result = message.match(re1)
console.log(result) ![]()
let message = "hello123 A BC545 abc6546 AS56346bc AA6546BC"
const re1 = /\w/ig
const result = message.match(re1)
console.log(result)
let message = "hello123 A BC545 abc6546 AS56346bc AA6546BC"
const re1 = /./ig
const result = message.match(re1)
console.log(result)
5.2.锚点
符号 ^匹配文本开头;
let message = "ABcder AbCdess abkkkiruj bAcurj"
const re1 = /^abc/ig
const result = re1.test(message)
console.log(result) //true符号 $匹配文本末尾;
let message = "ABcder AbCdess abkkkiruj bAcurj"
const re1 = /urj$/ig
const result = re1.test(message)
console.log(result) //truelet message = "ABCd ABC ABCDD ABCDF"
const re1 = /\bABC\b/ig
const result = message.match(re1)
console.log(result)![]()
只会匹配单独的ABC单词,其他的都不匹配。
5.3.转义字符
6.集合(Sets)和范围(Ranges)
◼ 有时候我们只要选择多个匹配字符的其中之一就可以:
- 在方括号[…]中的几个字符或者字符类意味着“搜索给定的字符中的任意一个”;
- 比如说,[eao] 意味着查找在 3 个字符 ‘a’、‘e’ 或者 `‘o’ 中的任意一个;
let message = "abc aac aec adc"
const re1 = /a[abed]c/ig
const result = message.match(re1)
console.log(result) ![]()
- 方括号也可以包含字符范围;
- 比如说,[a-z] 会匹配从 a 到 z 范围内的字母,[0-5] 表示从 0 到 5 的数字;
- [0-9A-F] 表示两个范围:它搜索一个字符,满足数字 0 到 9 或字母 A 到 F;
- \d —— 和 [0-9] 相同;
- \w —— 和 [a-zA-Z0-9_] 相同;
let message = "5a 4d 7b 1d"
const re1 = /[0-9][a-z]/ig
const result = message.match(re1)
console.log(result)![]()
7.量词(Quantifiers)
- 确切的位数:{5}
let message = "aaaajccccccaaajjcccccaaaaajccaa"
const re1 = /a{3}/ig
const result = message.match(re1)
console.log(result)![]()
- 某个范围的位数:{3,5}
let message = "aaaajccccccaaajjcccccaaaaajccaa"
const re1 = /a{3,5}/ig
const result = message.match(re1)
console.log(result)![]()
◼ 缩写:
- +:代表“一个或多个”,相当于 {1,}
let message = "aaaajccccccaaajjcccccaaaaajccaa"
const re1 = /a+/ig
const result = message.match(re1)
console.log(result)![]()
- ?:代表“零个或一个”,相当于 {0,1}。换句话说,它使得符号变得可选
- *:代表着“零个或多个”,相当于 {0,}。也就是说,这个字符可以多次出现或不出现
8. 贪婪(greedy)和懒惰(lazy)模式
有一个需求,想要匹配两本书,先看一下默认的情况下匹配到的。
let message = "两本书《一本书》和《两本书》"
const re1 = /《.+》/ig
const result = message.match(re1)
console.log(result)![]()
可见把第一本书的《到第二本书的》作为一个整体了,我们想要的是匹配两本书。
- 只要获取到对应的内容后,就不再继续向后匹配;
- 我们可以在量词后面再加一个问号 ‘?’来启用它;
- 所以匹配模式变为 *? 或 +?,甚至将 '?' 变为 ??
let message = "两本书《一本书》和《两本书》"
const re1 = /《.+?》/ig
const result = message.match(re1)
console.log(result)![]()
9.捕获组
模式的一部分可以用括号括起来 (...),这称为“捕获组(capturing group)”。
- 它允许将匹配的一部分作为结果数组中的单独项;
- 它将括号视为一个整体;
9.1.作为结果数组中的单独项
比如上面匹配书本的例子中,我们想要用《》匹配到书本并且取书名,我们就可以使用捕获组。
let message = "两本书《一本书》和《两本书》"
const re1 = /(《)(.+?)(》)/ig
const result = message.matchAll(re1)
for(const item of result){
console.log(item)
}我们将匹配项分成了三组,使用matchAll返回一个迭代器,并且迭代它。

for(const item of result){
console.log(item[2])
}![]()
9.2.将括号视为一个整体
如果想要获取两个以上的abc,没有加上括号的时候只会匹配两个以上的c,因为{2,}默认匹配最近的那个字符。
let message = "abcdddabcabcccccabcaaaa"
const re1 = /(abc){2,}/ig
const result = message.match(re1)
console.log(result)![]()
加上了括号之后,就把括号里面的内容当成了一个整体,上面的例子匹配的是有两个及以上的abc。
9.3. 捕获组的命名
在上面取书名的案例中,是使用数字来记录组的。
let message = "两本书《一本书》和《两本书》"
const re1 = /(?<name1>《)(?<name2>.+?)(?<name3>》)/ig
const result = message.matchAll(re1)
for(const item of result){
console.log(item)
}
这样在取元素的时候就会更加方便一些。
9.4.捕获组的排除
上面取书本的例子中,如果不想要取《》,就可以排除掉这个捕获组。
可以通过在开头添加?:来排除组。
let message = "两本书《一本书》和《两本书》"
const re1 = /(?:《)(?<name2>.+?)(?:》)/ig
const result = message.matchAll(re1)
for(const item of result){
console.log(item)
}
9.5.捕获组的或
◼ or是正则表达式中的一个术语,实际上是一个简单的“或”。
- 在正则表达式中,它用竖线|表示;
- 通常会和捕获组一起来使用,在其中表示多个值;
let message = "cbacbadddabcabccaccaabcaaaa"
const re1 = /(abc|cba){2,}/ig
const result = message.match(re1)
console.log(result)![]()