百面机器学习总结笔记(第五章 非监督学习)
百面机器学习总结笔记
第五章 非监督学习
第1节 K均值学习
场景描述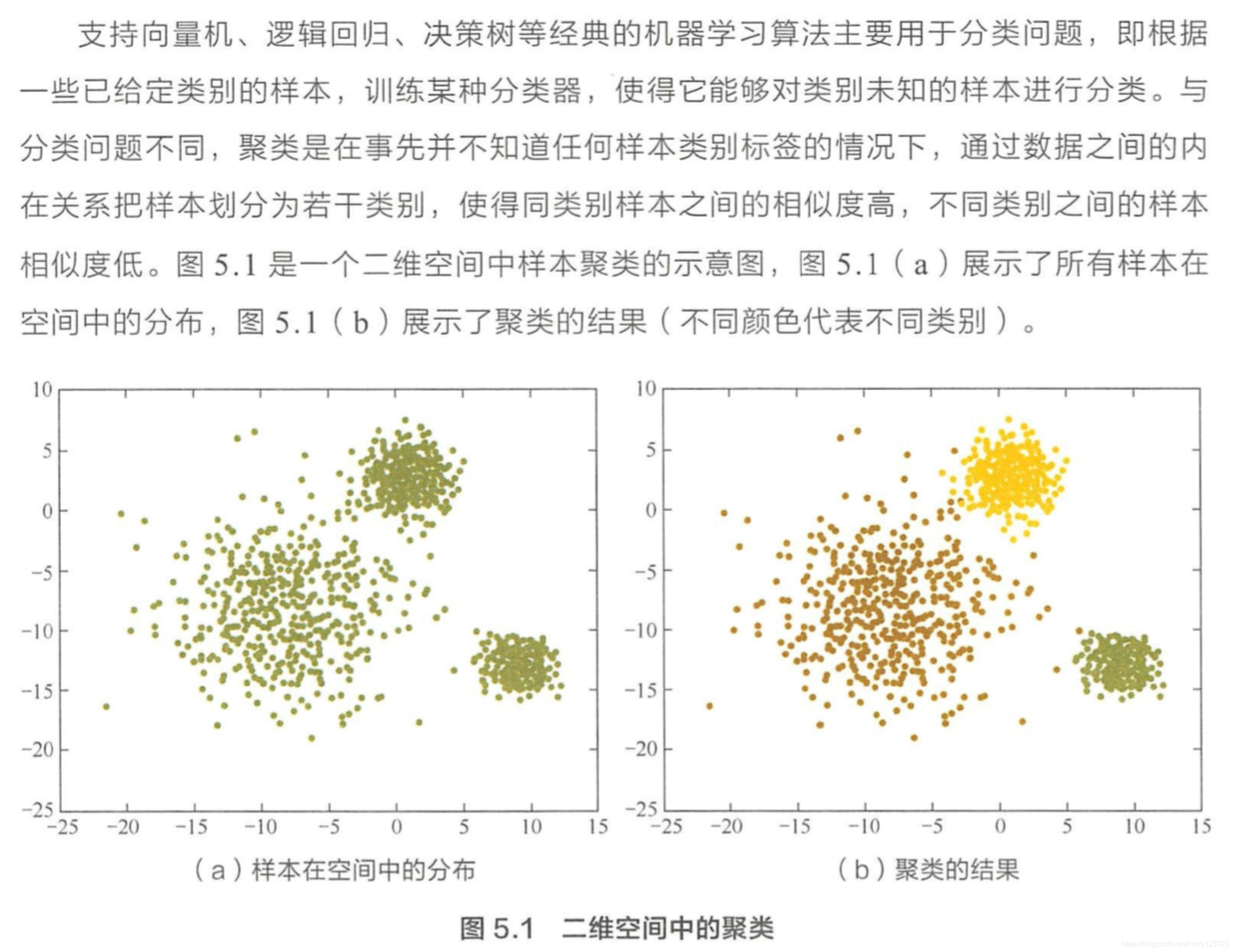

知识点
K 均值聚类算法,ISODATA 算法, EM 算法( Expectation-Maximization Algorithm ,最大期望算法)
问题:简述K均值算法的具体步骤
分析与解答
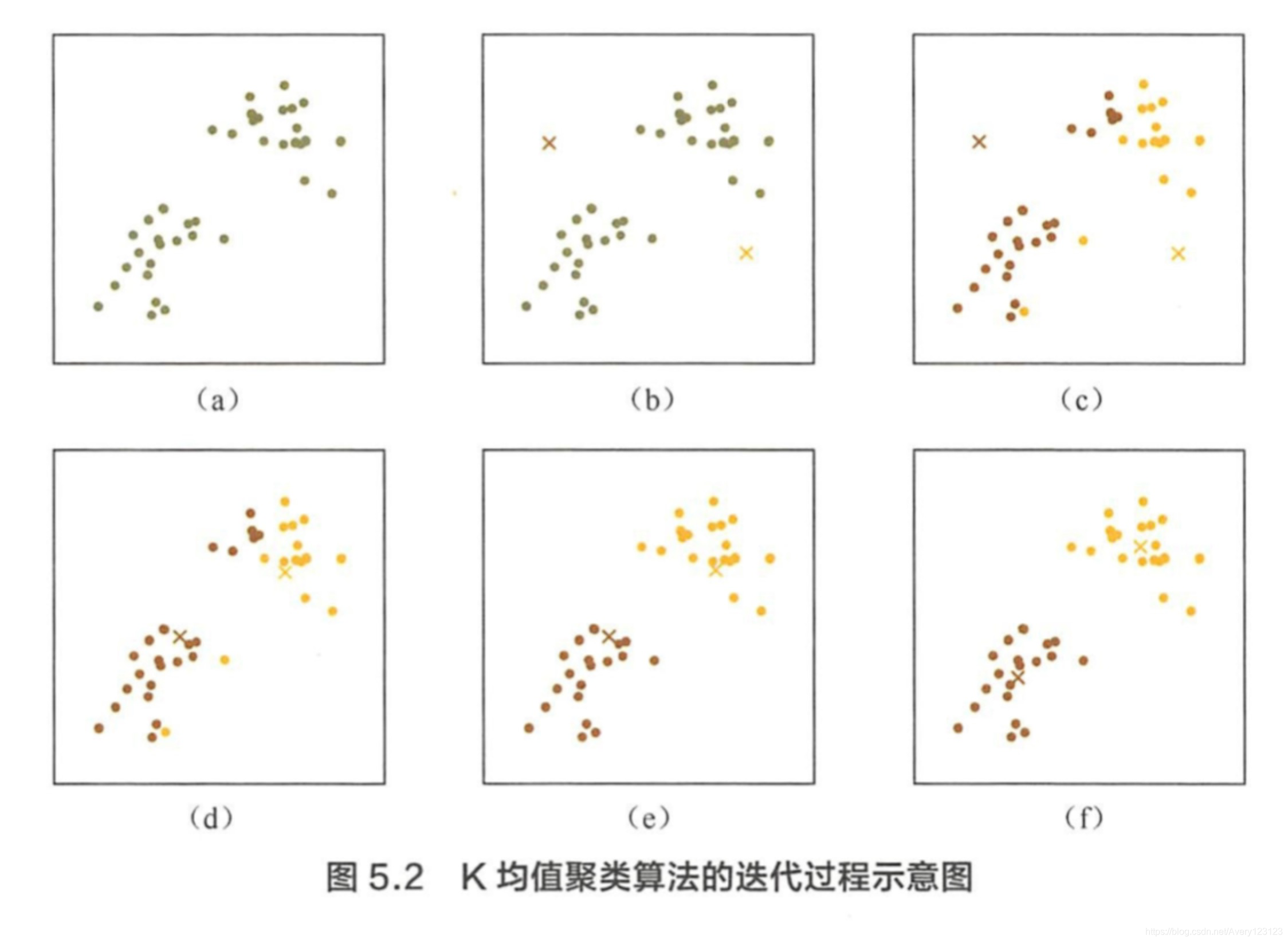
图 5.2 是 K-means 算法的一个迭代过程示意图 。 首先,给定二维空间上的一些样本点(见国 5.2 (a) ) , 直观上上这些点可以被分成两类, 接下来,初始化两个中心点(圄 5.2( b)的棕色和黄色叉子代表中心点), 并根据中心点的位置计算每个样本所属的簇(圄 5.2 ( c )用不同颜色表示),然后根据每个簇中的所有点的平均值计算新的中心点位置( 见圄 5.2(d )),图 5.2 (e)和图 5.2 (f) 展示了新轮的迭代结果, 在经过两轮的迭代之后,算法基本收敛 。
问题:K 均值算法的优缺点是什么?如何对其进行调优?
分析与解答
优缺点
算法调优

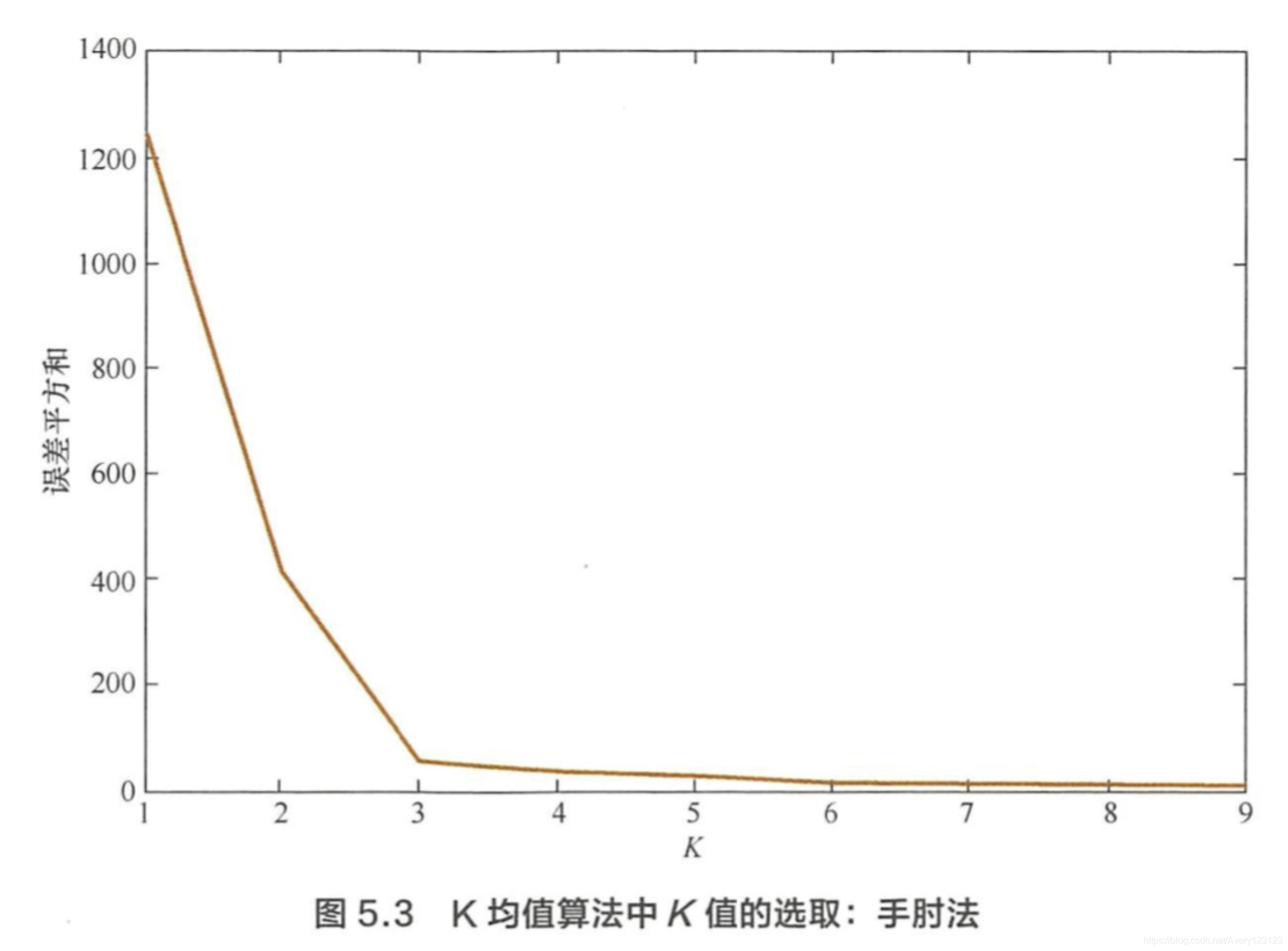

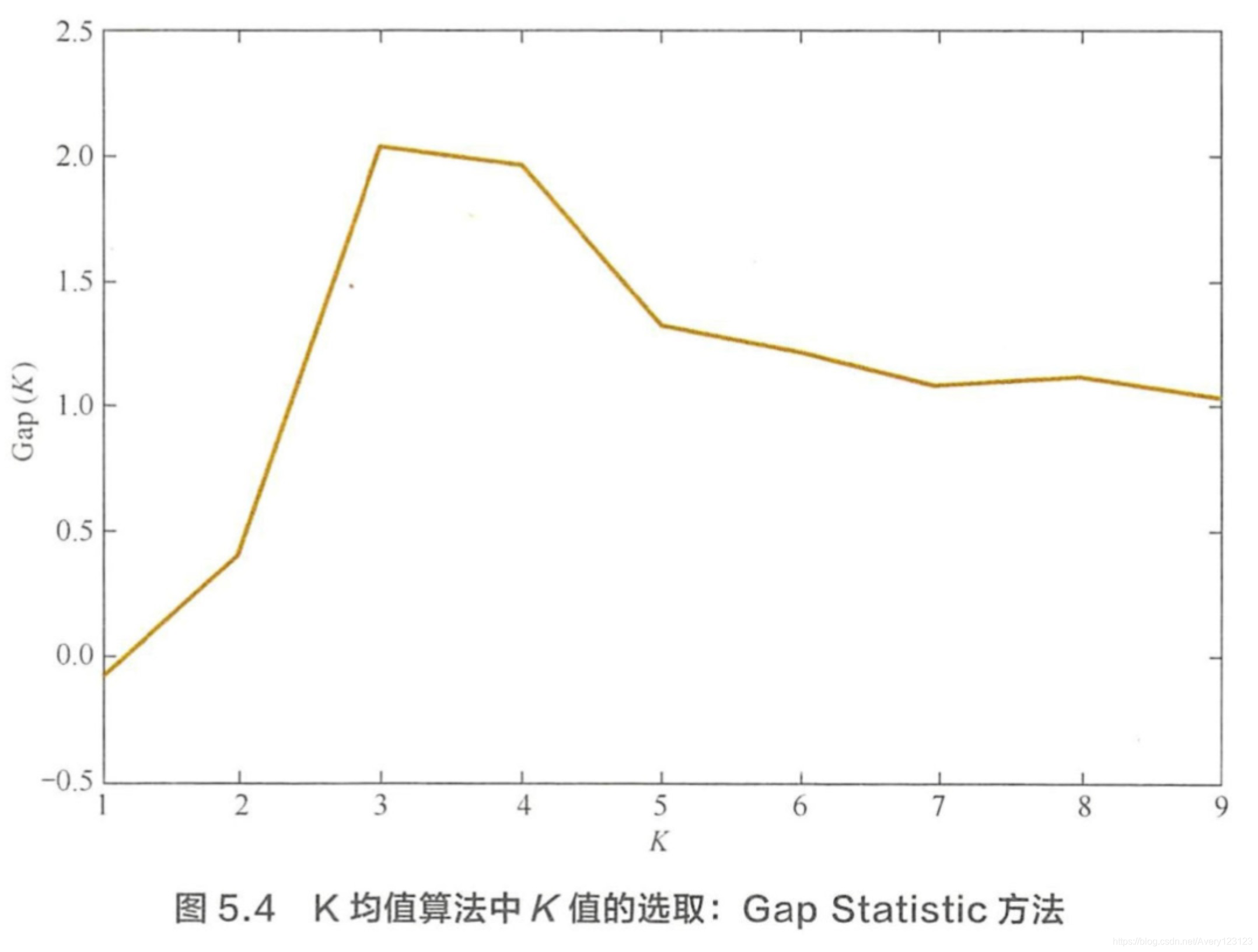

问题:针对K 均值算法的缺点有哪些改进模型?
分析与解答
K均值算法的主要缺点
K -means++算法

ISODATA算法

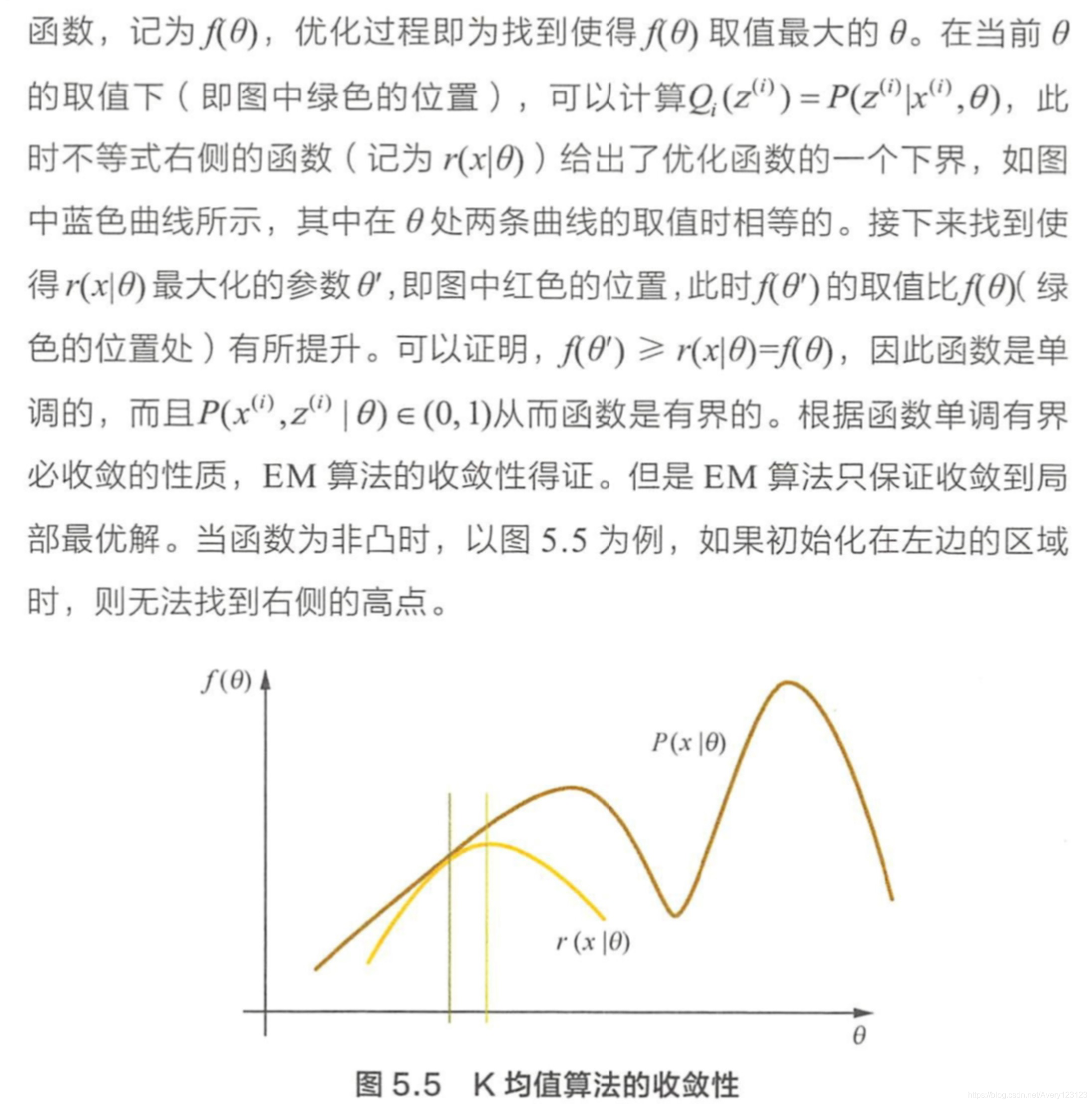
问题:证明K均值算法的收敛性
分析与解答



第2节 高斯混合模型
场景描述

知识点
高斯分布,高斯混合模型, EM 算法
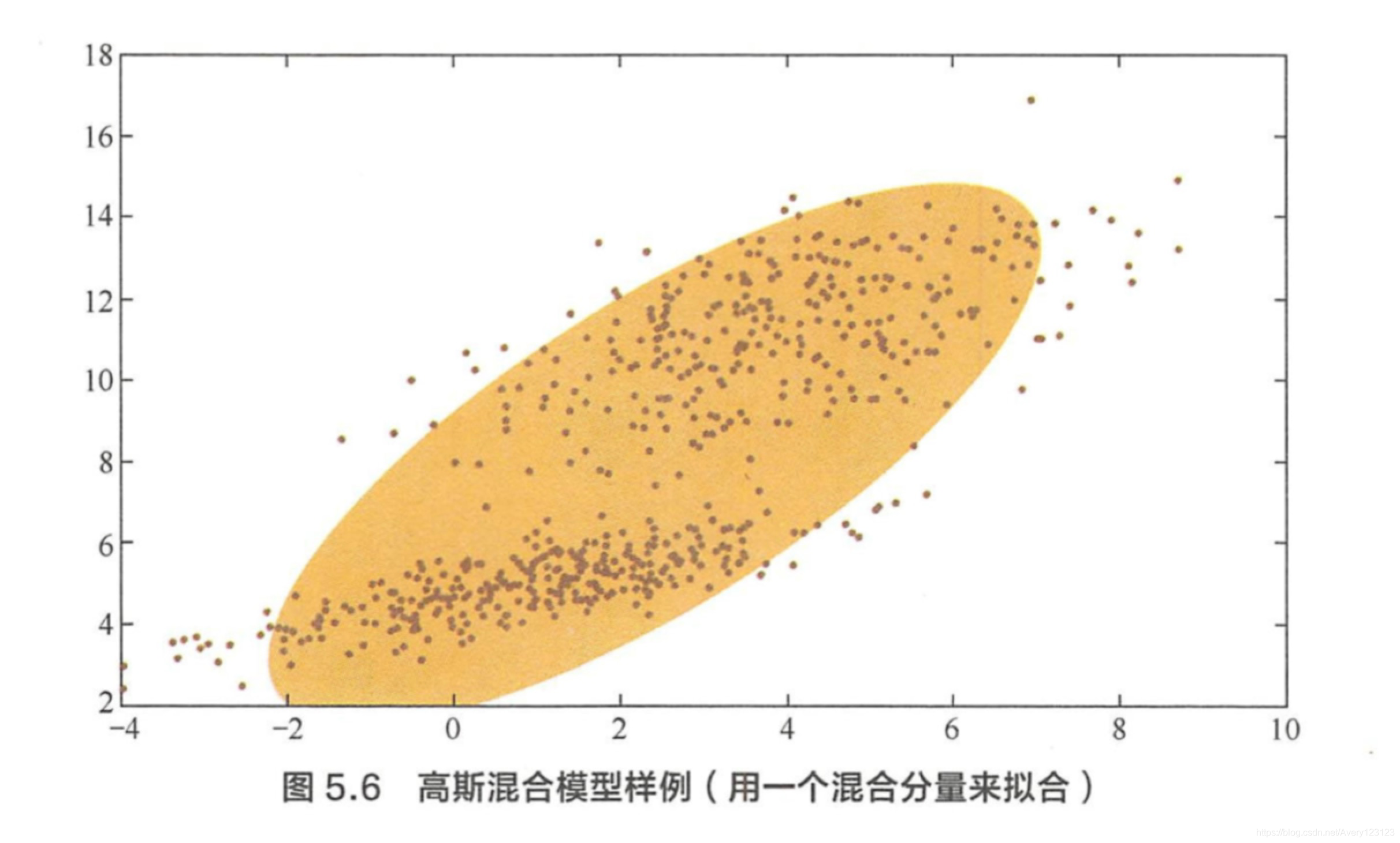
问题:高斯混合模型的核心思想是什么?它是如何迭代计算的?
说起高斯分布,大家都不陌生,通常身高、分数等都大致符合高斯分布 。因此,当我们研究各类数据时,设同 一类的数据符合高斯分布,也是很简单自然的假设,当数据事实上有多个类,或者我们希望将数据划分为 一些簇时,可以假设不同簇中的样本各自服从不同的高斯分布,由此得到的聚类算法称为高斯混合模型。






第3节 自组织映射神经网络
场景描述
自组织映射神经网络( Self-Organizing Map , SOM )是无监督学习方法中一类重要方法可以用作聚类、高维可视化、数据压缩、特征提取等多种用途 。 在深度神经网络大为流行的今天,谈及自组织映射神经网络依然是一件非常有意义的事情。这主要是由于自组织映射神经网络融入了大量人脑神经元的信号处理机制,有着独特的结构特点。该模型由芬兰赫尔辛基大学教授 Teuvo Kohonen 于 1981 ~手提出,因此也被称为 Kohonen 网络 。
问题
自组织神经网络是如何工作的?它与K均值算法有何区别?
分析与解答


流程


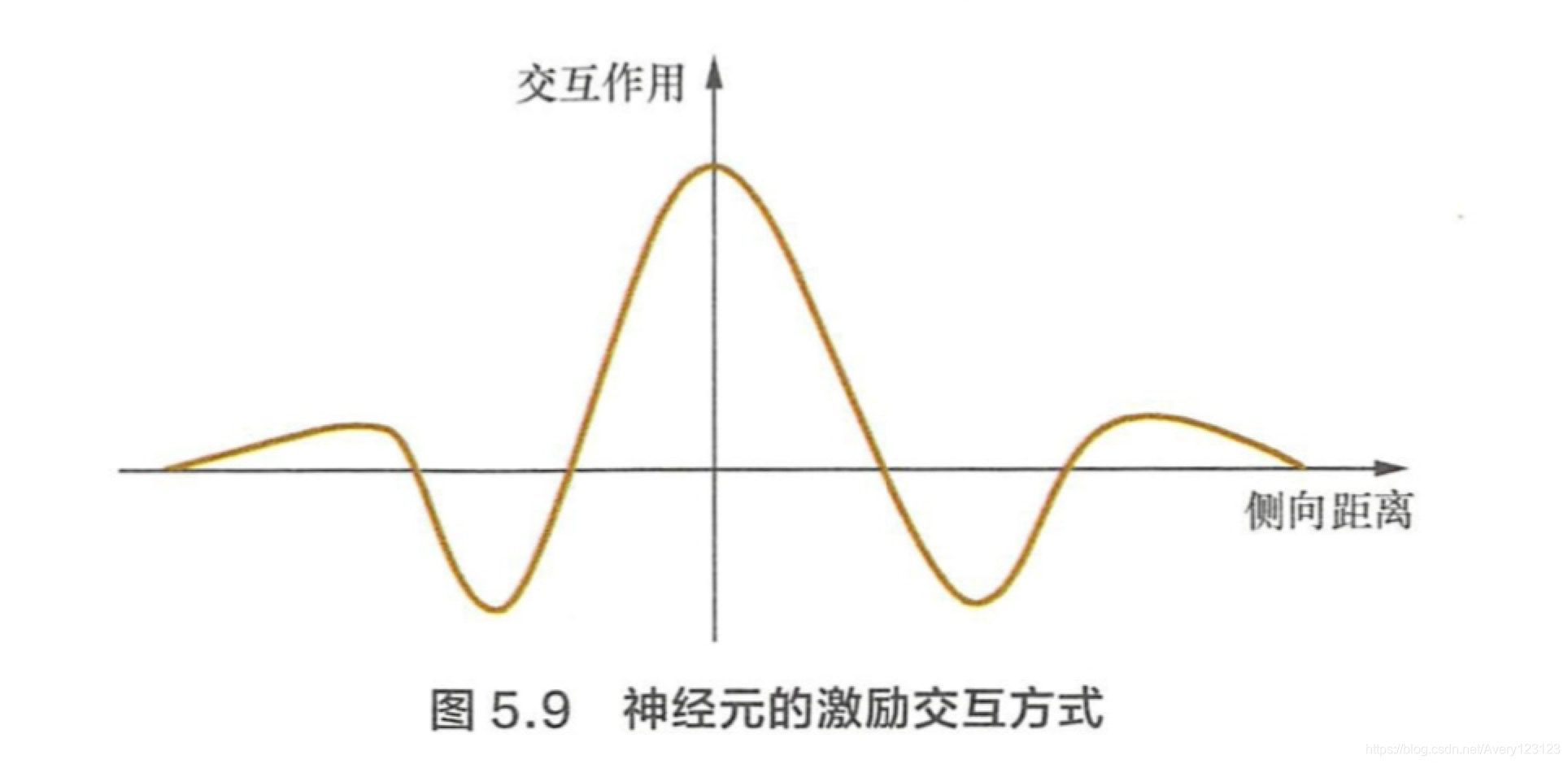
自组织映射神经网络与 K 均值算法的区别如下 :
问题
如何设计自组织神经网络并设定网络训练参数?
分析与解答




第4节 聚类算法的评估
场景描述
问题
以聚类问题为例,假设没有外部标签数据,如何评估两个聚类算法的优劣?
分析与解答
以中心定义的数据簇 这类数据集合倾向于球形分布,通常中心被定义为质心,即此数据簇中所高点的平均值。集合中的数据到中心的距离相比到真他簇中心的距离更近 。
以密度定义的数据簇 这类数据集合呈现和周围数据簇明显不同
的密度,或稠密或稀疏 。 当数据簇不规则或互相盘绕,并且奇噪
声和离群点时 , 常常使用基于密度的簇定义 。
以连通定义的数据簇 这类数据集合中的数据点和数据点之间再
连接关系,整个数据簇表现为图结构 。 该定义对不规则形状或者
缠绕的数据簇有效 。
以慨念定义的数据簇 这类数据集合中的所有数据点具有某种共
同性质 。
聚类评估的任务是估计在数据集上进行聚类的可行性,以及聚类方法产生结果的质量。 这一过程又分为三个子任务 。

