本题主要是以sk-learn中的红酒案例来说明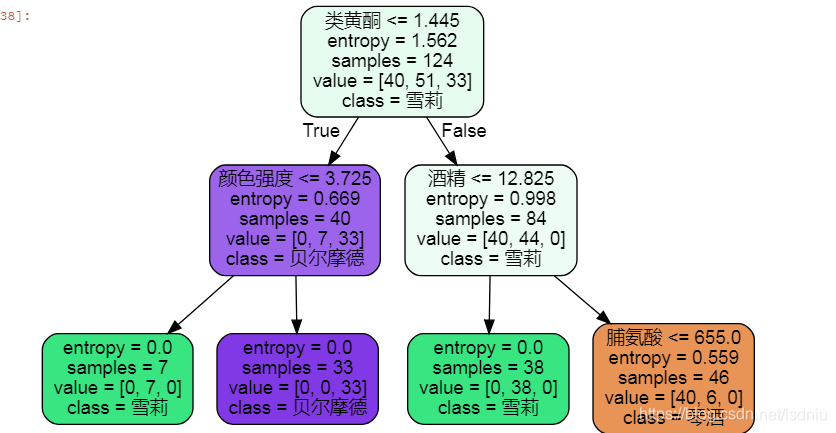
内部分支上第一个为分类点
entropy为信息熵即不纯度(不纯度越低越好)
samples为样本量
value为每样样本的样本容量
class主要显示出容量多的样本
版权声明:本文为lsdniu原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。
本题主要是以sk-learn中的红酒案例来说明
内部分支上第一个为分类点
entropy为信息熵即不纯度(不纯度越低越好)
samples为样本量
value为每样样本的样本容量
class主要显示出容量多的样本