

SQL Join用于根据两个或多个表中的列之间的关系,从这些表中查询数据。最常见的类型有SQL Inner Join、SQL Left Join、SQL Right Join、SQL Full Join 。那么,实现上述Join类型的算法都有哪些呢?本文重点介绍CirroData的nested loop join, sort-merge join,hash join三种Join算法。
Join场景举例
假设我们准备建立一个提供NBA比赛信息网站,用来提供对球队、球员、场馆、比赛等信息的查询,网站后台数据库中现有team和player两张表。Team表记录球队的信息,包括球队唯一编号(key)、球队名称(name)、主场所在地(homefield)。Player表记录球员信息,包括球员唯一编号(key)、姓名(name)、薪资(salary)、所属球队Id(teamId)。两张表数据信息如下。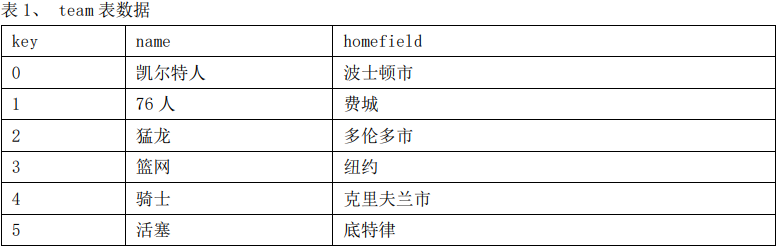
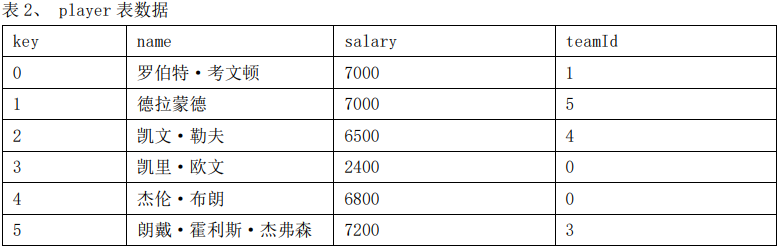 现要查询薪资大于等于7200球员的球队名称、球员名称、球员薪资,SQL语句如下: select team.name, player.name,player.salary from player join team on player.teamid = team.key and player.salary >= 7200 数据库中该语句大致执行流程如下:
现要查询薪资大于等于7200球员的球队名称、球员名称、球员薪资,SQL语句如下: select team.name, player.name,player.salary from player join team on player.teamid = team.key and player.salary >= 7200 数据库中该语句大致执行流程如下: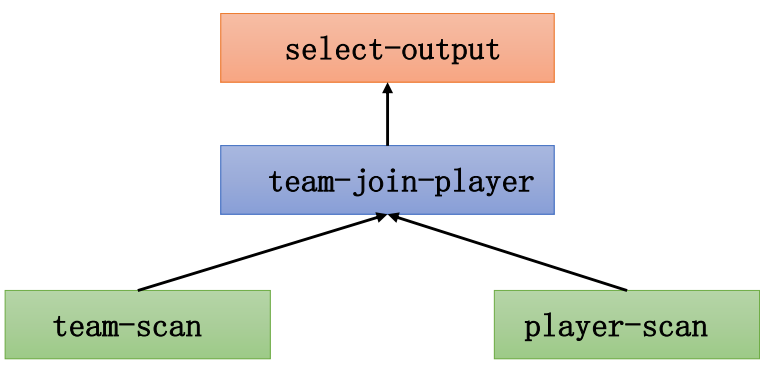 该查询语句由上而下进行抽取、分为4个执行单元。先执行team-scan, player-scan两个执行单元,然后执行team-join-player单元,最后是执行select-output单元。
该查询语句由上而下进行抽取、分为4个执行单元。先执行team-scan, player-scan两个执行单元,然后执行team-join-player单元,最后是执行select-output单元。team-scan表示将team表的数据表从硬盘读取到内存中来。
player-scan表示将player表的数据表从硬盘中读取到内存中来。
team-join-player会将内存中的team表和内存中的player表按照SQL中on连接条件进行JOIN匹配操作。
select-output会将team-join-player送来的结果按照select后要求的格式进行运算和输出。
三种Join算法介绍
为了便于描述算法、我们假设运行环境内存足够、不考虑分布式特殊处理。将team表和player表数据读取到内存以后,就可以开始join运算了。常见的Join算法有三种:nested loop join, sort-merge join, hash join。这三种join都可以等效的完成上面查询球员薪资的SQL语句的运算。 01Nested loop join算法
Nested loop join算法简述: 两层for循环,依次取出player表的每行数据,和team表逐行比较。 如果满足join的连接条件,就输出 ; 如 果不满足, 本轮不 做处理并 取下 一行 进行比较。 Nested loop join算法伪代码: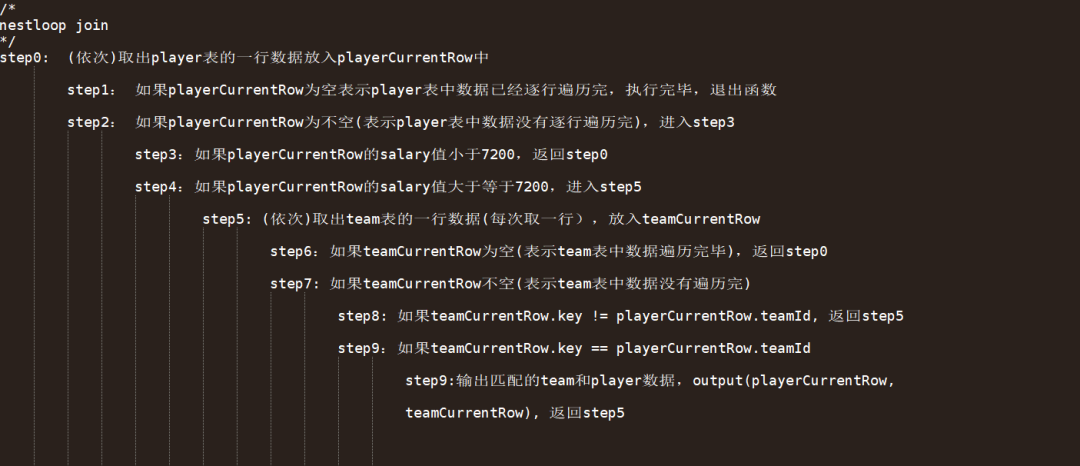 Nested loop join的算法优点: 算法简单、同时他对于join的连接条件没有特殊要求(特殊要求参见后续hash算法)、对于左表,右表的数据没有特殊要求(特殊要求参见sort-merge join算法)。 Nested loop join的算法缺点:时间复杂度是O(N*M)(其中N和M是两个表中数据的行数)。如果表比较大的话,判断匹配时的比较次数会很多,所以执行会比较慢。 02 Sort-merge join算法 Sort-merge join算法简述: Sort-merge join的算法是一种特殊的nested loop join算法。该算法前提条件是将参与join的两个表按照join key进行排序。 Sort-merge join算法执行步骤: 对team表和player表按照join key进行排序,排序字段分别为team.key和player.teamId。
Nested loop join的算法优点: 算法简单、同时他对于join的连接条件没有特殊要求(特殊要求参见后续hash算法)、对于左表,右表的数据没有特殊要求(特殊要求参见sort-merge join算法)。 Nested loop join的算法缺点:时间复杂度是O(N*M)(其中N和M是两个表中数据的行数)。如果表比较大的话,判断匹配时的比较次数会很多,所以执行会比较慢。 02 Sort-merge join算法 Sort-merge join算法简述: Sort-merge join的算法是一种特殊的nested loop join算法。该算法前提条件是将参与join的两个表按照join key进行排序。 Sort-merge join算法执行步骤: 对team表和player表按照join key进行排序,排序字段分别为team.key和player.teamId。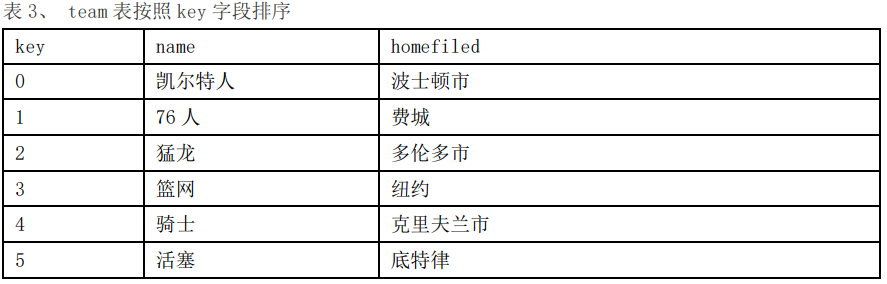
 将team表和player表排序完以后。我们执行如下步骤: Step0:我们首先取出player表中teamId为0的行。如下记为player-team0, 接下来把player-team0当作一个表和team表做nestloop操作。然后将nestloop的结果输出即可。
将team表和player表排序完以后。我们执行如下步骤: Step0:我们首先取出player表中teamId为0的行。如下记为player-team0, 接下来把player-team0当作一个表和team表做nestloop操作。然后将nestloop的结果输出即可。 Step1:然后我们继续取出player表中teamId为1的行,如下记为player-team1,接下来将player-team1当作一个表和team表做nested loop join操作。然后将nested loop的结果输出即可。
Step1:然后我们继续取出player表中teamId为1的行,如下记为player-team1,接下来将player-team1当作一个表和team表做nested loop join操作。然后将nested loop的结果输出即可。 Stepn:同理,最后提取player表中teamId=5的行,如下记为player-teamN,将player-teamN和team表做nested loop join。然后将nested loop join的结果输出即可。以上步骤执行完 毕,sort-merge join也就执 行完了。
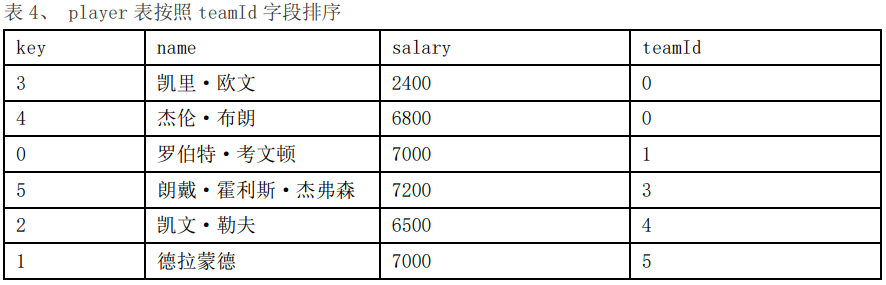
Stepn:同理,最后提取player表中teamId=5的行,如下记为player-teamN,将player-teamN和team表做nested loop join。然后将nested loop join的结果输出即可。以上步骤执行完 毕,sort-merge join也就执 行完了。 上述操作是将player表切割成几个小表,然后和team整个表做nested loop join。这是一个特殊的nested loop join。因为player表和team表做过排序,我们可以对执行过程做优化。 Sort-merge join优化方法: 在step0步骤的nested loop的实现中,我们可以记住team表中team.key=1的位置。 同时由于team表已经排序。当player-team0和team表的nested loop join操作执行到team.key=1的行时,我们可以肯定:team表的后续行都不会满足player.teamId=team.Key。所以我们可以提前结束这个Nested loop join的执行。 因此,此处的player-team0和team做Nested loop join的时间复杂度不再是N*M。其时间复杂度是小于等于N*M的 (其中Nplayer-team0的行数,M为team表的行数) 同样我们在step1的执行过程中,可以记录team表team.key=2的位置。方便我们在step3的步骤实现中跳过team表的一些不必要的行的比较。依此类推,我们可以看到,由于player表和team表排序。计算过程中的每个nestloop的时间复杂度都降低了。 Sort-merge join算法的优点: Sort-merge join算法,要求参与join的两张表是排序表。并且排序的列,是连接条件中包含的列。在有些情况下,sort-merge join的执行效率要比hash join要高(比如内存有限,team表又比较大,不能将team表中的数据一次性放入hash表中,需要反复建立hash表,这个操作就比较耗时。 对于事务型数据库,如果join的连接键上建有索引。Team-scan和player-scan执行模块获取排序数据比较方便,可以考虑使用sort-merge join。 对于分析型数据库,可以在向team表,player表insert数据的时候,先按照join的键值排序,然后insert存储在数据库中。这样在join查询的时候可以考虑使用sort-merge join。 Sort-merge join算法的限制条件: 如果join的on连接条件仅仅包含“不等”(!=)或者like条件。通常不走sort-merge join。 03 Hash join算法 Hash join算法简述: 顾名思义,我们需要先建立一个hash表,本文中我们使用team表来建立hash表,然后扫描另外一张表player表、查找hash表,比 较具有相同哈希码的元组的相等联接是否相等。 Hash join算法执行步骤: 1.建立team表的hash表 现在我们建立一个hash表(TeamHashTable),根据hash(team.key)指示的桶号(bucketId),依次将指向team表中各行数据的指针ptrTeam,存入TeamHashTable相应的bucket(桶)中。 2.遍历player表、查找hash表 当指向Team表各行数据的指针都存储在TeamHashTable中以后。依次取出player表中的每行数据,根据hash(ptrPlayer->teamId)生成的hash值(bucketId,即桶号)到TeamHashTable找到对应bucket(桶),从中找到先前存储在其中的指向team表某行的指针ptrTeam。比较两者的等值连接条件,如果相等将两个指针指向的数据拼在一起就可以作为join的结果输出了。例如:Output.push_back(*ptrPlayer, *ptrTeam); 这是hash join算法的核心部分。针对我们上文中的SQL,我们画出hash join的计算流程示意图:
上述操作是将player表切割成几个小表,然后和team整个表做nested loop join。这是一个特殊的nested loop join。因为player表和team表做过排序,我们可以对执行过程做优化。 Sort-merge join优化方法: 在step0步骤的nested loop的实现中,我们可以记住team表中team.key=1的位置。 同时由于team表已经排序。当player-team0和team表的nested loop join操作执行到team.key=1的行时,我们可以肯定:team表的后续行都不会满足player.teamId=team.Key。所以我们可以提前结束这个Nested loop join的执行。 因此,此处的player-team0和team做Nested loop join的时间复杂度不再是N*M。其时间复杂度是小于等于N*M的 (其中Nplayer-team0的行数,M为team表的行数) 同样我们在step1的执行过程中,可以记录team表team.key=2的位置。方便我们在step3的步骤实现中跳过team表的一些不必要的行的比较。依此类推,我们可以看到,由于player表和team表排序。计算过程中的每个nestloop的时间复杂度都降低了。 Sort-merge join算法的优点: Sort-merge join算法,要求参与join的两张表是排序表。并且排序的列,是连接条件中包含的列。在有些情况下,sort-merge join的执行效率要比hash join要高(比如内存有限,team表又比较大,不能将team表中的数据一次性放入hash表中,需要反复建立hash表,这个操作就比较耗时。 对于事务型数据库,如果join的连接键上建有索引。Team-scan和player-scan执行模块获取排序数据比较方便,可以考虑使用sort-merge join。 对于分析型数据库,可以在向team表,player表insert数据的时候,先按照join的键值排序,然后insert存储在数据库中。这样在join查询的时候可以考虑使用sort-merge join。 Sort-merge join算法的限制条件: 如果join的on连接条件仅仅包含“不等”(!=)或者like条件。通常不走sort-merge join。 03 Hash join算法 Hash join算法简述: 顾名思义,我们需要先建立一个hash表,本文中我们使用team表来建立hash表,然后扫描另外一张表player表、查找hash表,比 较具有相同哈希码的元组的相等联接是否相等。 Hash join算法执行步骤: 1.建立team表的hash表 现在我们建立一个hash表(TeamHashTable),根据hash(team.key)指示的桶号(bucketId),依次将指向team表中各行数据的指针ptrTeam,存入TeamHashTable相应的bucket(桶)中。 2.遍历player表、查找hash表 当指向Team表各行数据的指针都存储在TeamHashTable中以后。依次取出player表中的每行数据,根据hash(ptrPlayer->teamId)生成的hash值(bucketId,即桶号)到TeamHashTable找到对应bucket(桶),从中找到先前存储在其中的指向team表某行的指针ptrTeam。比较两者的等值连接条件,如果相等将两个指针指向的数据拼在一起就可以作为join的结果输出了。例如:Output.push_back(*ptrPlayer, *ptrTeam); 这是hash join算法的核心部分。针对我们上文中的SQL,我们画出hash join的计算流程示意图: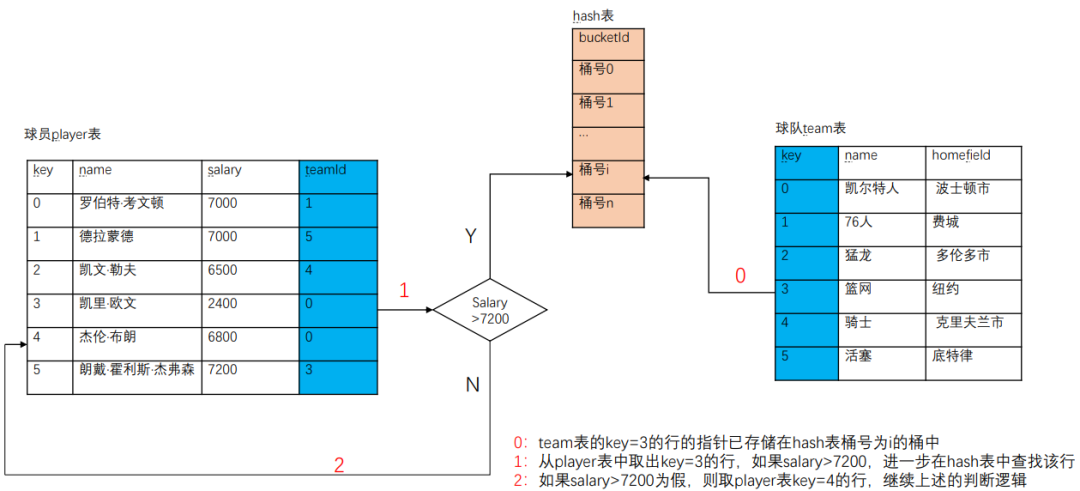 Hash join算法伪代码
Hash join算法伪代码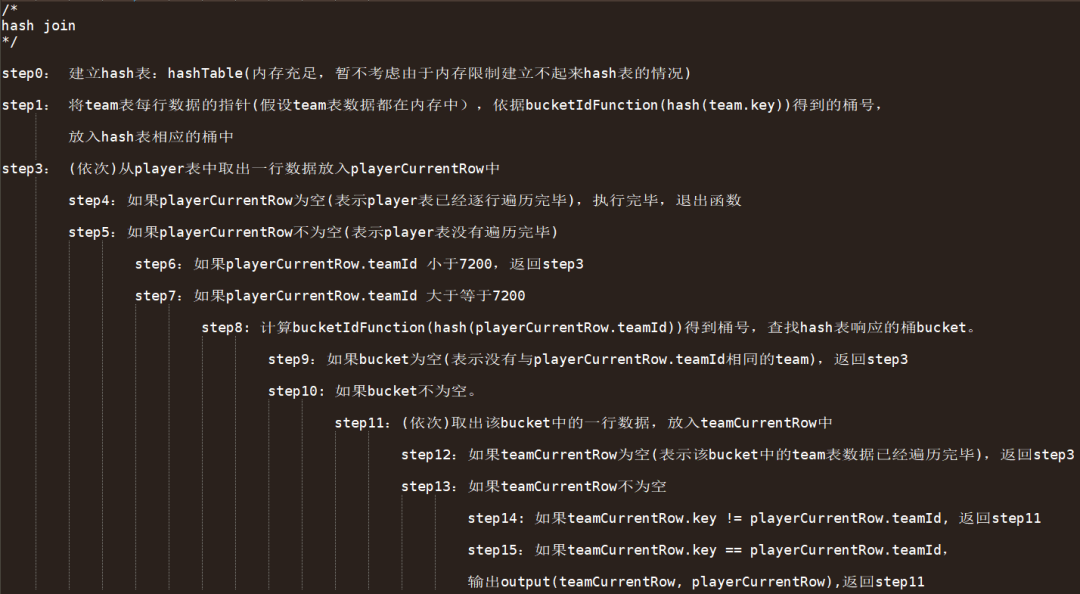 Hash join算法的优点: 执行player.teamId = team.key的时间复杂度是O(1),所以hash join的执行效率会比较高。 Hash join算法的限制条件: Join的on条件中必须有“等值连接条件“。
Hash join算法的优点: 执行player.teamId = team.key的时间复杂度是O(1),所以hash join的执行效率会比较高。 Hash join算法的限制条件: Join的on条件中必须有“等值连接条件“。总结
为了便于介绍基本算法,文中并未考虑服务器的内存限制因素。本文简单介绍了CirroData数据库的nested loop join, sort-merge join,hash join三种算法。在SQL具体的执行过程中,选择哪种Join算法更优,通常由执行计划来决定。三种算法在各自领域性能指标优异。

CirroData是北京东方国信科技股份有限公司自主研发的一款面向海量数据分析型应用领域的分布式云化数据库。采用了先进的计算和存储分离的技术架构,融合了分布式存储和MPP并行计算的各自优势,不但可以轻松实现云平台上的伸缩扩展能力,而且可以提供随需部署的能力,是新一代云数据仓库的典型代表。
CirroData能满足PB级海量数据的存储和分析,这些数据可以分布在数百台通用服务器上,能够被数千并发用户高速访问,可以满足数据密集型行业日益增大的海量数据存储、高性能加工,在线分析、即席查询和高并发访问的需求。
