列式存储与行式存储区别
目前大数据存储有两种方案可供选择:行存储(Row-Based)和列存储(Column-Based)。大数据时代大部分的查询模式决定了列式存储优于行式存储。两者的区别在于如何组织表:
Ø Row-based storage storesatable in a sequence of rows.
Ø Column-based storage storesatable in a sequence of columns.
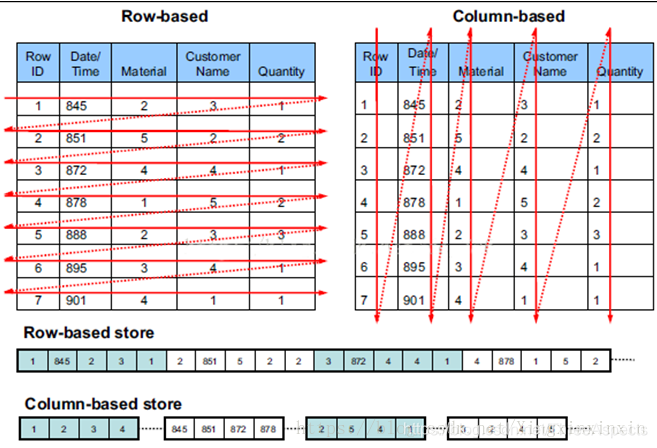
行式存储下一张表的数据都是放在一起的,列式存储下被分开保存。
优缺点对比:
数据写入
1)行存储的写入是一次完成。如果这种写入建立在操作系统的文件系统上,可以保证写入过程的成功或者失败,数据的完整性因此可以确定。
2)列存储由于需要把一行记录拆分成单列保存,写入次数明显比行存储多(意味着磁头调度次数多,而磁头调度是需要时间的,一般在1ms~10ms),再加上磁头需要在盘片上移动和定位花费的时间,实际时间消耗会更大。所以,行存储在写入上占有很大的优势。
3)数据修改,也算一次写入过程。不同的是,数据修改是对磁盘上的记录做删除标记。行存储是在指定位置写入一次,列存储是将磁盘定位到多个列上分别写入,这个过程仍是行存储的列数倍。所以,数据修改也是以行存储占优。
数据读取
1)数据读取时,行存储通常将一行数据完全读出,如果只需要其中几列数据的情况,就会存在冗余列,出于缩短处理时间的考量,消除冗余列的过程通常是在内存中进行的。
2)列存储每次读取的数据是集合的一段或者全部,不存在冗余性问题。
3) 两种存储的数据分布。由于列存储的每一列数据类型是同质的,不存在二义性问题。比如说某列数据类型为整型(int),那么它的数据集合一定是整型数据。这种情况使数据解析变得十分容易。相比之下,行存储则要复杂得多,因为在一行记录中保存了多种类型的数据,数据解析需要在多种数据类型之间频繁转换,这个操作很消耗CPU,增加了解析的时间。所以,列存储的解析过程更有利于分析大数据。
综上:
- 行存储的写入是一次性完成,消耗的时间比列存储少,并且能够保证数据的完整性,缺点是数据读取过程中会产生冗余数据。
- 列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据。数据即索引,只访问查询涉及的列,可以大量降低系统I/O。每一列由一个线程来处理,即查询的并发处理性能高。数据类型一致,数据特征相似,可以大幅度提高压缩比,有利于存储和网络输出数据带宽的消耗。
使用场景
列存储的适用场景
1)OLAP类型的查询需要访问几百万甚至几十亿个数据行,且该查询往往只关心少数几个数据列。例如,查询今年销量最高的前20个商品,只关心三个数据列:时间(date)、商品(item)以及销售量(sales amount)。商品的其他数据列,例如商品URL、商品描述等等,对这个查询都是没有意义的。而列式数据库只需要读取存储着“时间、商品、销量”的数据列,而行式数据库需要读取所有的数据列。因此,列式数据库大大地提高了OLAP大数据量查询的效率。
OLTP OnLine TransactionProcessor 在线联机事务处理系统(比如Mysql,Oracle等产品)
OLAP OnLine AnalaysierProcessor 在线联机分析处理系统(比如Hive Hbase等)
列存储主要适合于批量数据处理(OLAP)和即时查询,如果每次查询涉及的数据量较小或者大部分查询都需要整行的数据,列存储并不适用。行存储主要适合于小批量的数据处理,常用于联机事务型数据处理(OLTP)。
2)很多列式数据库还支持列族(column group,Bigtable系统中称为locality group),即将多个经常一起访问的数据列的各个值存放在一起。如果读取的数据列属于相同的列族,列式数据库可以从相同的地方一次性读取多个数据列的值,避免了多个数据列的合并。列族是一种行列混合存储模式,这种模式能够同时满足OLTP和OLAP的查询需求。
3)此外,由于同一个数据列的数据重复度很高,因此,列式数据库压缩时有很大的优势。还可以针对列式存储做专门的索引优化。比如,性别列只有两个值,“男”和“女”,可以对这一列建立位图索引:
- “男”对应的位图为100101,表示第1、4、6行值为“男”
- “女”对应的位图为011010,表示第2、3、5行值为“女”
如果需要查找男性或者女性的个数,只需要统计相应的位图中1出现的次数即可。另外,建立位图索引后0和1的重复度高,可以采用专门的编码方式对其进行压缩。
HBase 是列式数据库吗
首先明确HBase 不是列式存储数据库。
不管是存储在内存的 MemStore,还是存储在 HDFS 上的 HFile,其都是基于 LSM(Log-Structured Merge-Tree)结构存储的。假设有一张 HBase 表: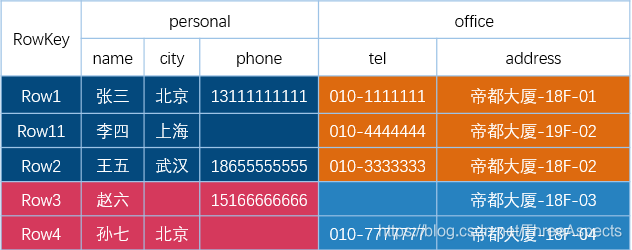
那么,HBase 底层的 KV 存储大概如下所示的: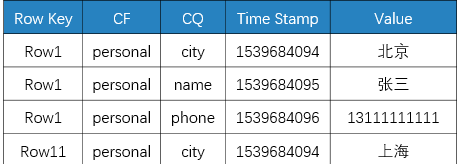
从上图可以看出:
- 整个数据是按照 Rowkey 进行字典排序的
- 每一列数据在底层 HFile 中是以 KV 形式存储的
- 相同的一行数据中,如果列族也一样,那么这些数据是顺序放在一起的
HBase 不是列式数据库,因为同一行数据,如果列族也一样,这些数据是存储在相邻位置的,与列式存储不太一样。因此,HBase 既不像行式存储,又不像列式存储。它其实更像是面向列族的存储数据库,因为不同行相同的列族数据是相邻存储的;而同一行不同列族的数据是存储在不同位置的。
补充
压缩
通过字典表压缩数据。下图中的表经过字典表进行数据压缩后,表中的字符串变为数字。正因为每个字符串在字典表里只出现一次了,所以达到了压缩的目的
在定义表的时候,每一列都是一种数据类型,这样就可以使用针对数据类型的压缩方法将数据压缩,压缩可以达到一个数量级的性能提升。当某一列被排序之后,可以达到更高的压缩比。压缩的意义不仅在于降低磁盘占用,毕竟磁盘越来越便宜,这个意义会越来越小。压缩的意义更多在于加速查询,如减少了磁盘IO或者直接操作压缩后的数据来降低 CPU 代价。
读取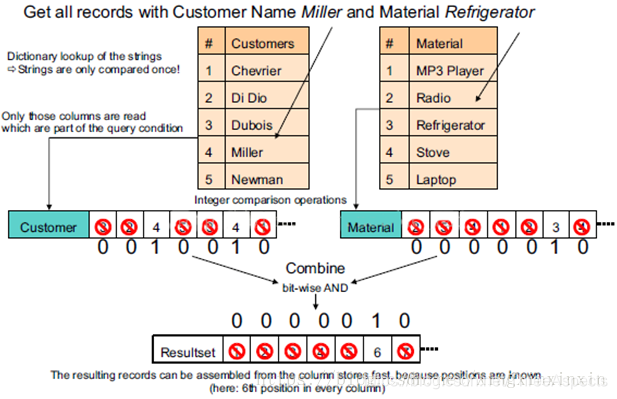
关键步骤如下:
- 去字典表里找到字符串对应数字(只进行一次字符串比较)。
- 用数字去列表里匹配,匹配上的位置设为1。
- 把不同列的匹配结果进行位运算得到符合所有条件的记录下标。
- 使用这个下标组装出最终的结果集。
拼接
将数据按列存储,一个数据项的多个属性被分开存放在不同地方了,一个查询也会同时访问多个属性,并且 JDBC 等接口还是以一行为单位返回结果的。因此,多列数据拼接在列式存储中是一个必不可少的操作。
怎么拼接?
一个数据项的各个属性分开存放,谁对应谁?是按顺序拼接的。比如,第一个数据项的三个属性在三个列的位置都是1,以此类推。读的时候可以根据下标将各属性拼接起来。
什么时候拼接?
延迟拼接是列式存储为了解决拼接问题而发掘出来的优势了。假如一个表里有100列,有一个查询 select c3 from table1 where c1>10 and c2>5;第一种方式是行式过滤的思想,先将c1,c2,c3 三列读出来,拼接成一个一个数据项,再对每行数据项的 c1,c2 的值进行 c1>10 and c2>5 的过滤。这个暂且叫预先拼接。第二种方式是延迟拼接,将谓词下推至各个列,先记录 c1 列中满足 c1>10 的所有数据下标 A,再记录 c2 列中满足 c2>5 的所有数据下标 B,将 A 和 B 合并成 C,并用 C 去读 c3 列。实践证明这种方式更能发挥列式存储的优势。