目录
2、CBoW(Continuous Bag-of-Words,给定上下文→中间词)
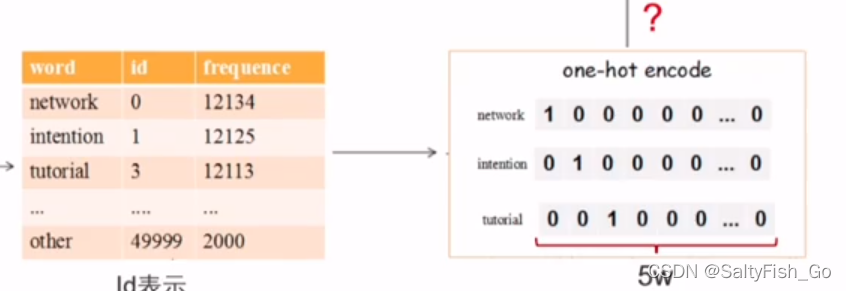
one-hot与embedding的区别
one-hot 独热编码:
特征稀疏
词之间相互独立,没有顺序关系
不能表征词与词之间的关系,one-hot 之间是正交的
Embedding :对每一个单词用一个低维且稠密的可学习向量表征
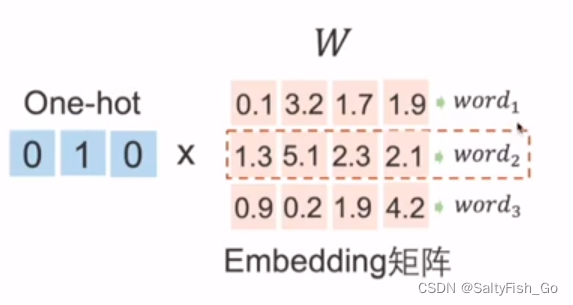
每一行代表一个词向量,可以做词与词之间的语义运算。
词向量模型Word2Vec(自监督学习)
分布式假设:具有相似上下文的词语应该是相近的,所以对上下文进行建模
包含两个自监督的学习任务(无标签自己学):
1、skip-gram(给定中间词→上下文)

计算上下文的过程,重要!!!
给定中间词,来预测上下文窗口中的词: 选定一个词,用one-hot向量乘Embedding矩阵,可以得到唯一不为0的 词向量(包含本词和其他词之间的关系);再乘一个分类矩阵W', 得到每个位置上每个词的权重,最后softmax概率映射函数,就得到每个位置上每个词的预测概率。
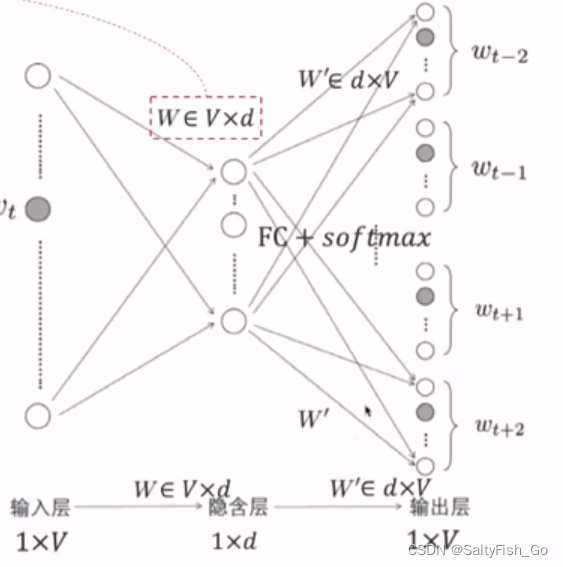
2、CBoW(Continuous Bag-of-Words,给定上下文→中间词)
过程与skip-gram相反
如何从C个上下文词得到最大概率的中间词:
窗口内C个上下文单词的one-hot乘Embedding矩阵,得到C个词向量,将这些词向量meanpooling,取得加和平均(包含上下文词的平均相关系数信息),再乘个分类矩阵W'然后softmax(得到每个词的概率)。取最大概率的中间词。
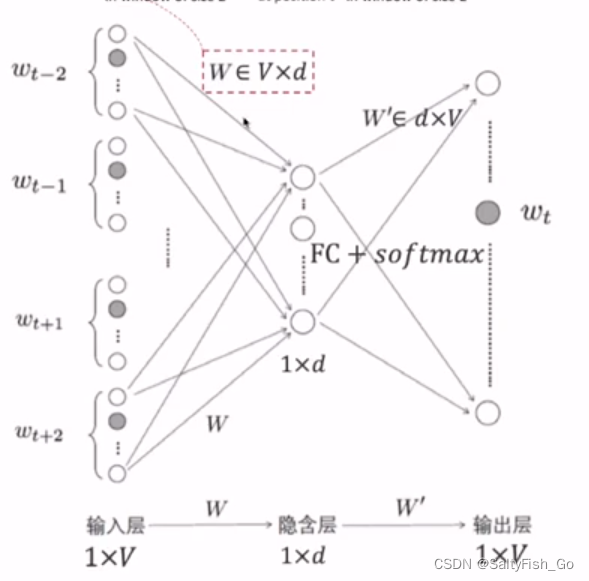
个人理解:embedding矩阵W中包含着词与词之间的关系系数,与某个词的one-hot编码相乘后得到这个词与其他词的关系系数;分类矩阵W'的作用是通过关系系数向量得到每个位置上每个词的概率。
CBoW和skip-gram的应用上的区别:
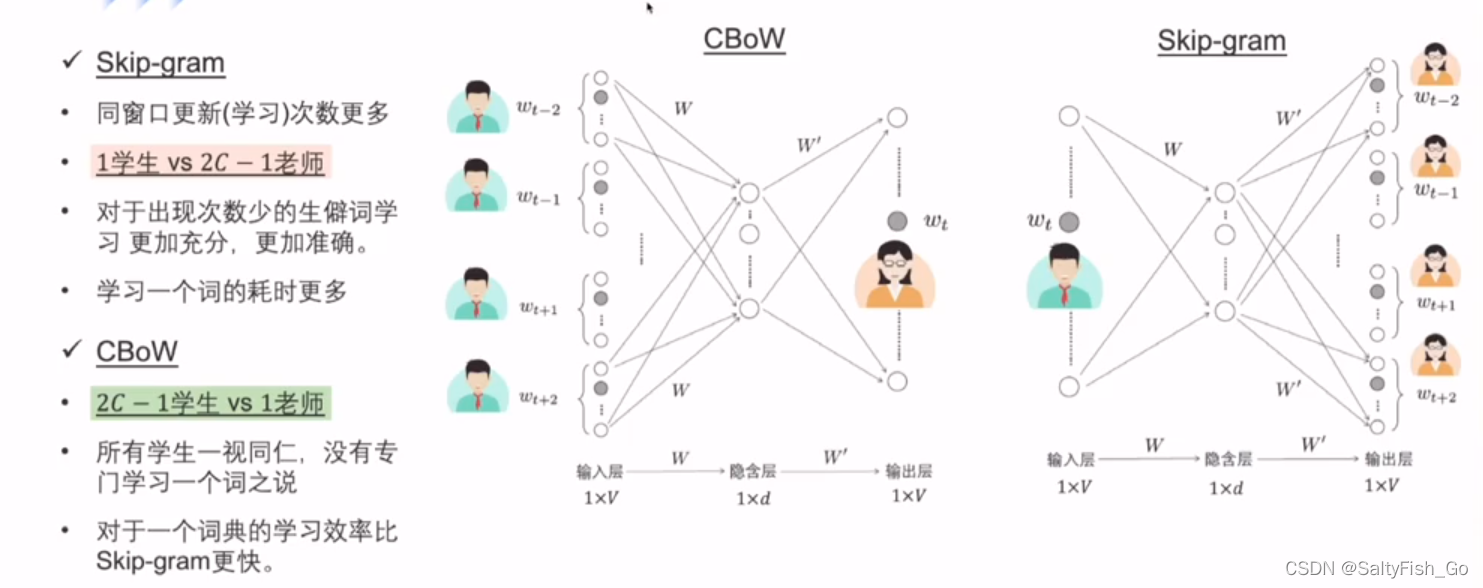
cbow是一个老师教2C-1个学生,效率更高,能更快的达到平均水平
skip-gram是一个学生被2C-1个老师轮流教,对于生僻词的学习更准确(每个上下文词都学习一遍)
版权声明:本文为weixin_45169380原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。