前言
在学习MySQL,到group by时, 始终不能理解分组查询是怎么查的, 为什么每个条件只返回一行结果, 百度到一片文章, 彻底理解
源地址: 理解sql中的group by和having , 写的特别详细,深入浅出,形象生动, 感谢!.
问题
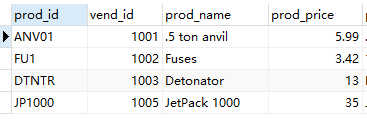
有这样一张表 products

根据vend_id 分组,使用group by:
SELECT * FROM products GROUP BY vend_id ;
结果却是如下:每个vend id只出现了一次, 商品名称和价格都只展示该vend id 的第一行内容.
原来从查询到结果的中间过程 ,可以理解为新建了一个表:

根据vend id 分组, 把vend id为1001 的其他字段合并在一行, 只展示第一行内容.
程序设计时并没有考虑您用分组查询做什么, 所以便没有报错.
group by需要配合聚合函数使用
group by 一般配合聚合函数使用,max min avg sum count ,
这些函数是在where 条件查询出数据之后操作, 所以不能在where后用
所以当不配合聚合函数使用时, 查询结果并不是想要的,正确使用如下:
查找每个供应商提供了多少个价格大于10的产品 ,查询语句为:
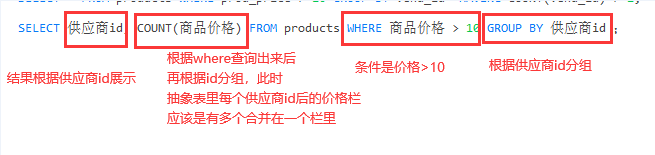
查询过程中的抽象表与聚合函数的作用域便是在这里:

HAVING 的使用:
理解了聚合函数在这里的作用后,便很容易理解having的使用,
就是对聚合函数的结果进行一个过滤, 与where不同,where是查询前条件, having是查询后再通过聚合函数处理后再过滤.
查找 供应商提供了2个及以上 价格大于10的商品

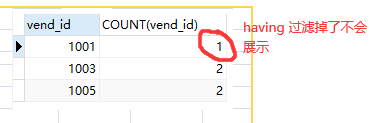
having使用的场景, 转自https://my.oschina.net/lscherish/blog/4268722:

吐槽:
2021年4月7日19:21:57
感觉国内博客内网站太多了, csdn,博客园 , os China, gitee等, 每个体量都很大,
所以感觉需要注册的地方太多了.若是有个专门的IT网站, 高度聚合博客,那么只需要管理或者发表在一个网站就好了, 需要搜索也只需要在一个网站搜索
而不是在百度搜索, 出来很多干扰性的网页.