PyTorch基础篇:
- PyTorch基础知识 | 安装 | 张量 | 自动求导
- PyTorch主要组成模块 | 数据读入 | 数据预处理 | 模型构建 | 模型初始化 | 损失函数 | 优化器 | 训练与评估
- PyTorch主要组成模块 | hook函数 | 正则化weight decay与Dropout | 标准化
- PyTorch模型定义 | 模型容器 | 模型块 | 修改模型 | 模型读取与保存
- PyTorch进阶技巧 | 自定义损失函数 | 动态调整学习率 | 模型微调 | 半精度训练 | 使用argparse进行调参
- PyTorch可视化 | 可视化网络结构 | 使用TensorBoard可视化训练过程
一、深度学习任务框架
回顾我们在完成一项机器学习任务时的步骤,首先需要对数据进行预处理,其中重要的步骤包括数据格式的统一和必要的数据变换,同时划分训练集和测试集。接下来选择模型,并设定损失函数和优化方法,以及对应的超参数(当然可以使用sklearn这样的机器学习库中模型自带的损失函数和优化器)。最后用模型去拟合训练集数据,并在验证集/测试集上计算模型表现。
深度学习和机器学习在流程上类似,但在代码实现上有较大的差异。首先,由于深度学习所需的样本量很大,一次加载全部数据运行可能会超出内存容量而无法实现;同时还有批(batch)训练等提高模型表现的策略,需要每次训练读取固定数量的样本送入模型中训练,因此深度学习在数据加载上需要有专门的设计。
在模型实现上,深度学习和机器学习也有很大差异。由于深度神经网络层数往往较多,同时会有一些用于实现特定功能的层(如卷积层、池化层、批正则化层、LSTM层等),因此深度神经网络往往需要“逐层”搭建,或者预先定义好可以实现特定功能的模块,再把这些模块组装起来。这种“定制化”的模型构建方式能够充分保证模型的灵活性,也对代码实现提出了新的要求。
接下来是损失函数和优化器的设定。这部分和经典机器学习的实现是类似的。但由于模型设定的灵活性,因此损失函数和优化器要能够保证反向传播能够在用户自行定义的模型结构上实现。
上述步骤完成后就可以开始训练了。我们前面介绍了GPU的概念和GPU用于并行计算加速的功能,不过程序默认是在CPU上运行的,因此在代码实现中,需要把模型和数据“放到”GPU上去做运算,同时还需要保证损失函数和优化器能够在GPU上工作。如果使用多张GPU进行训练,还需要考虑模型和数据分配、整合的问题。此外,后续计算一些指标还需要把数据“放回”CPU。这里涉及到了一系列有关于GPU的配置和操作。
深度学习中训练和验证过程最大的特点在于读入数据是按批的,每次读入一个批次的数据,放入GPU中训练,然后将损失函数反向传播回网络最前面的层,同时使用优化器调整网络参数。这里会涉及到各个模块配合的问题。训练/验证后还需要根据设定好的指标计算模型表现。
总结来说,打通深度学习流程需要搞懂以下几个部分:
- 数据读入
- 模型构建
- 模型初始化
- 损失函数
- 优化器
- 训练和评估
二、数据读入
PyTorch数据读取在Dataloader模块下,Dataloader又可以分为DataSet与Sampler。Sampler模块的功能是生成索引(样本序号);DataSet是依据索引读取Img、Lable。数据读入主要是通过Dataset+DataLoader的方式完成的,Dataset定义好数据的格式和数据变换形式,DataLoader用iterative的方式不断读入批次数据。
torch.utils.data.DataLoader():构建可迭代的数据装载器
DataLoader(dataset,
batch_size=1,shuffle=False,sampler=None,
batch_sampler=None,num_workers=0,
collate_fn=None,pin_memory=False,drop_last=False,timeout=0,
worker_init_fn=None,
multiprocessing_context=None)
dataset: Dataset类,决定数据从哪读取及如何读取batch_size:批大小num_works:是否多进程读取数据shuffle:每个epoch是否乱序drop_last:当样本数不能被batchsize整除时,是否舍弃最后一批数据
Epoch:所有训练样本都已输入到模型中,称为一个Epoch
Iteration:一批样本输入到模型中,称之为一个lteration
Batchsize:批大小,决定一个Epoch有多少个lteration
- 样本总数:80,Batchsize : 8
1 Epoch = 10 lteration- 样本总数:87, Batchsize: 8
1 Epoch = 10 lteration ? drop_last = True
1 Epoch = 11 lteration drop_last = False
torch.utils.data.Dataset():Dataset抽象类,所有自定义的Dataset需要继承它,并且复写__getitem__()
getitem:接收一个索引,返回一个样本
class Dataset(object):
def __getitem__(self,index):
raise NotImplementedError
def __add__(self, other) :
return ConcatDataset([self, other])
数据读取流程如下:
我们可以定义自己的Dataset类来实现灵活的数据读取,定义的类需要继承PyTorch自身的Dataset类。主要包含三个函数:
__init__: 用于向类中传入外部参数,同时定义样本集__getitem__: 用于逐个读取样本集合中的元素,可以进行一定的变换,并将返回训练/验证所需的数据__len__: 用于返回数据集的样本数
class RMBDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
rmb面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def __getitem__(self, index):
# 根据索引index获得数据与标签
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.data_info)
@staticmethod
def get_img_info(data_dir):
data_info = list()
# 遍历一个目录内,各个子目录与子文件
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
构建好Dataset后,就可以使用DataLoader来按批次读入数据了,实现代码如下:
from torch.utils.data import DataLoader
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, num_workers=4, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, num_workers=4, shuffle=False)
其中:
batch_size:样本是按“批”读入的,batch_size就是每次读入的样本数num_workers:有多少个进程用于读取数据shuffle:是否将读入的数据打乱drop_last:对于样本最后一部分没有达到批次数的样本,使其不再参与训练
数据整理器将数据由下面的形式:
转化为batch形式:
三、数据预处理模块—transforms
1.数据预处理transforms模块机制
torchvision.transforms模块包含了很多图像预处理方法:
- 数据中心化
- 数据标准化
- 缩放
- 裁剪
- 旋转
- 翻转
- 填充
- 噪声添加
- 灰度变换
- 线性变换
- 仿射变换
- 亮度、饱和度及对比度变换
这个模块可以进行数据增强与数据预处理,增强模型的泛化能力。数据预处理transforms在数据读取过程中,最后生成数据预处理完的batch data。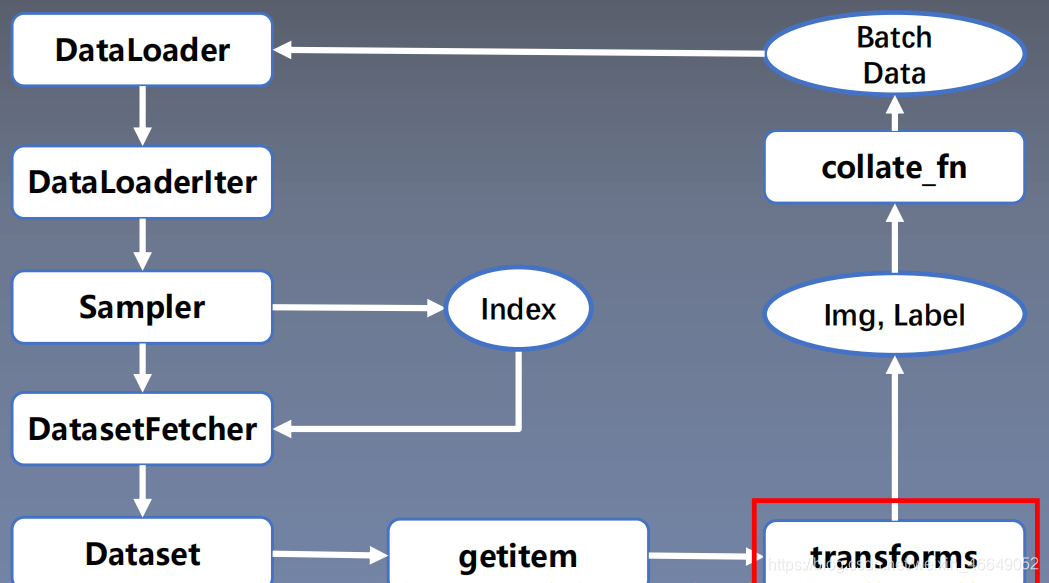
class RMBDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
rmb面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
# 在数据读取的这个节点开始调用transform,迭代使用多种tansform方法
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.data_info)
@staticmethod
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
2.二十二种transforms数据预处理方法
1.裁剪
transforms.CenterCrop:从图像中心裁剪图片。
size:所需裁剪图片尺寸
transforms.RandomCrop:从图片中随机裁剪出尺寸为size的图片。
transforms.RandomCrop(size,
padding=None,
pad_if_needed=False,fill=6,
padding_mode= 'constant ' )
size:所需裁剪图片尺寸padding:设置填充大小
当为a时,上下左右均填充a个像素
当为(a, b)时,上下填充b个像素,左右填充a个像素
当为(a,b,c,d)时,左,上,右,下分别填充a, b,c, dpad_if_need:若图像小于设定size,则填充padding_mode:填充模式,有4种模式
1、constant:像素值由fill设定
2、edge:像素值由图像边缘像素决定
3、reflect:镜像填充,最后一个像素不镜像,eg:[1,2,3.4] →[3,2,1,2,3,4,3,2]
4、symmetric:镜像填充,最后一个像素镜像,eg:[1,2,3,4]→[2,1,1,2,3,4,4,3]fill:constant时,设置填充的像素值
transforms.RandomResizedCrop:随机大小、长宽比裁剪图片。
RandomResizedCrop(size,
scale=(0.08,1.0),
ratio=(3/4,4/3),interpolation)
size:所需裁剪图片尺寸scale:随机裁剪面积比例,默认(0.08,1)ratio:随机长宽比,默认(3/4,4/3)interpolation:插值方法PIL.lmage.NEARESTPIL.lmage.BILINEARPIL.lmage.BICUBIC
transforms.FiveCrop:在图像的上下左右以及中心裁剪出尺寸为size的5张图片。
transforms .FiveCrop(size)
# 将tuple格式转换为Tensor格式
transforms.FiveCrop(112),
transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops]))
transforms.TenCrop:TenCrop对这5张图片进行水平或者垂直镜像获得10张图片
size:所需裁剪图片尺寸vertical_flip:是否垂直翻转
transforms.TenCrop(112, vertical_flip=False),
transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops]))
2. 翻转与旋转
transforms.RandomHorizontalFlip:依概率水平(左右)翻转图片
transforms.RandomHorizontalFlip(p=0.5)
p:翻转概率
transforms.RandomVerticalFlip:依概率垂直(上下)翻转图片
transforms.RandomVerticalFlip(p=0.5)
p:翻转概率
transforms.RandomRotation:随机旋转图片
RandomRotation(degrees,
resample=False,expand=False,
center=None)
degrees:旋转角度
当为a时,在(-a,a)之间选择旋转角度
当为(a,b)时,在(a,b)之间选择旋转角度resample:重采样方法expand:是否扩大图片,以保持原图信息
3.图像变换
transforms.Pad:对图片边缘进行填充。
transforms.Pad(padding,
fill=0,
padding_mode= ' constant ' )
padding:设置填充大小
当为a时,上下左右均填充a个像素
当为(a, b)时,上下填充b个像素,左右填充a个像素
当为(a,b,c,d)时,左,上,右,下分别填充a,b,c,dpadding_mode:填充模式,有4种模式,
constant、edge、reflect和symmetricfill:constant时,设置填充的像素值,(R,G,B)or(Gray)
transforms.colorjitter:调整亮度、对比度、饱和度和色相。
transforms.colorJitter(brightness=0,
contrast=0,
saturation=0,
hue=0)
brightness:亮度调整因子
当为a时,从[max(0,1-a),1+a]中随机选择
当为(a,b)时,从[a,b]中随机选择contrast:对比度参数,同brightnesssaturation:饱和度参数,同brightnesshue:色相参数,
当为a时,从[-a,a]中选择参数,
注:0<= a <= 0.5
当为(a,b)时:,从[a,b]中选择参数
注:-0.5<=a<=b<=0.5
transforms.Grayscale:将图片转换为灰度图
Grayscale(num_output_channels)
num_ouput_channels:输出通道数 只能设1或3
transforms.RandomGrayscale:依概率将图片转换为灰度图
num_ouput_channels:输出通道数 只能设1或3p︰概率值,图像被转换为灰度图的概率
transforms.RandomAffine:对图像进行仿射变换,仿射变换是二维的线性变换,由五种基本原子变换构成,分别是旋转、平移、缩放、错切和翻转
transforms.RandomAffine(degrees,
translate=None,scale=None,
shear=None ,resample=False,fillcolor=)
degrees:旋转角度设置translate:平移区间设置
如(a,b),a设置宽(width),b设置高(height)图像在宽维度平移的区间为
-img_width * a < dx < img_width * ascale:缩放比例(以面积为单位)fill_color:填充颜色设置shear:错切角度设置,有水平错切和垂直错切
若为a,则仅在x轴错切,错切角度在(-a, a)之间
若为(a, b),则a设置x轴角度,b设置y的角度
若为(a, b,c,d),则a, b设置x轴角度,c,d设置y轴角度resample:重采样方式,有NEAREST 、BILINEAR、BICUBIC
transforms.RandomErasing:对图像进行随机遮挡。
transforms.RandomErasing(p=0.5,
scale=(0.02,0.33),
ratio=(0.3,3.3),value=0,
inplace=False)
p:概率值,执行该操作的概率scale:遮挡区域的面积ratio:遮挡区域长宽比value:设置遮挡区域的像素值,(R,G,B) or (Gray)
transforms.Lambda(lambda):用户自定义lambda方法。
lambd: lambda匿名函数
lambda [arg1 [,arg2, … , argn]] : expression
eg:
transforms. Lambda(lambda crops: torch.stack([transforms. Totensor()(crop) for crop in crops]))
4.transforms方法的选择操作
transforms.RandomChoice:从一系列transforms方法中随机挑选一个
transforms. RandomChoice([transforms1,transforms2,transforms3])
transforms.RandomApply:依据概率执行一组transforms操作
transforms.RandomApply([transforms1,transforms2,transforms3], p=0.5)
transforms.RandomOrder::对一组transforms操作打乱顺序
transforms. Randomorder([transforms1,transforms2,transforms3])
transforms.Resize:调整图片的大小
transforms.Totensor:将之前的数据结构转换为张量
transforms.Normalize:逐channel的对图像进行标准化(变换后的数据均值为0,标准差为1),标准化的优点是加快模型的收敛。
transforms.Normalize(mean,
std,
inplace=False)
o u t p u t = ( i n p u t − m e a n ) / s t d output = (input - mean) / stdoutput=(input−mean)/std
mean:各通道的均值std:各通道的标准差inplace:是否原地操作
源码如下:
def normalize(tensor, mean, std, inplace=False):
"""Normalize a tensor image with mean and standard deviation.
.. note::
This transform acts out of place by default, i.e., it does not mutates the input tensor.
See :class:`~torchvision.transforms.Normalize` for more details.
Args:
tensor (Tensor): Tensor image of size (C, H, W) to be normalized.
mean (sequence): Sequence of means for each channel.
std (sequence): Sequence of standard deviations for each channel.
inplace(bool,optional): Bool to make this operation inplace.
Returns:
Tensor: Normalized Tensor image.
"""
# 输入的合法性判断-是否为Tensor
if not _is_tensor_image(tensor):
raise TypeError('tensor is not a torch image.')
# 是否原地操作,如果不是原地操作,需要将张量克隆一份
if not inplace:
tensor = tensor.clone()
dtype = tensor.dtype
# 将均值与方差转化为张量
mean = torch.as_tensor(mean, dtype=dtype, device=tensor.device)
std = torch.as_tensor(std, dtype=dtype, device=tensor.device)
# sub_:下划线表示原地操作;(input - mean) / std
tensor.sub_(mean[:, None, None]).div_(std[:, None, None])
# 返回变换后的张量
return tensor
5.自定义transfroms方法
transforms方法是在Compose类中通过__call__方法调用的。
class Compose(object):
"""Composes several transforms together.
Args:
transforms (list of ``Transform`` objects): list of transforms to compose.
Example:
>>> transforms.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.ToTensor(),
>>> ])
"""
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, img):
# 循环执行transforms方法
for t in self.transforms:
img = t(img)
return img
def __repr__(self):
format_string = self.__class__.__name__ + '('
for t in self.transforms:
format_string += '\n'
format_string += ' {0}'.format(t)
format_string += '\n)'
return format_string
我们可以发现调用transforms时有如下特点:
- 仅接收一个参数,返回一个参数
- 注意上下游的输出与输入
下面我们自定义transforms,它的基本结构为:
class YourTransforms(object) :
def __init_(self, ...):
...
def __cal1__(self, img):
...
return img
椒盐噪声又称为脉冲噪声,是一种随机出现的白点或者黑点,白点称为盐噪声,黑色为椒噪声。信噪比(Signal-Noise Rate,SNR)是衡量噪声的比例,图像中为图像像素的占比。我们以椒盐噪声为例来自定义transforms方法。
class AddPepperNoise(object):
"""增加椒盐噪声
Args:
snr (float): Signal Noise Rate
p (float): 概率值,依概率执行该操作
"""
def __init__(self, snr, p=0.9):
assert isinstance(snr, float) and (isinstance(p, float)) # 2020 07 26 or --> and
# 信号百分比
self.snr = snr
# 概率
self.p = p
def __call__(self, img):
"""
Args:
img (PIL Image): PIL Image
Returns:
PIL Image: PIL image.
"""
# 概率的判断
if random.uniform(0, 1) < self.p:
# 数据格式转换到ndarray
img_ = np.array(img).copy()
# 高,宽,通道数
h, w, c = img_.shape
# 获取信号百分比
signal_pct = self.snr
# 噪声百分比
noise_pct = (1 - self.snr)
# 依概率选取3个mask
mask = np.random.choice((0, 1, 2), size=(h, w, 1), p=[signal_pct, noise_pct/2., noise_pct/2.])
mask = np.repeat(mask, c, axis=2)
img_[mask == 1] = 255 # 盐噪声
img_[mask == 2] = 0 # 椒噪声
return Image.fromarray(img_.astype('uint8')).convert('RGB')
else:
return img
四、模型构建
1.神经网络构造
Module 类是 nn 模块里提供的一个模型构造类,是所有神经网络模块的基类。
模型构建有两个要素:
下面我们以LeNet模型为例,展示其模型创建过程
class LeNet(nn.Module):
# 初始化构建子模块
def __init__(self, classes):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, classes)
# 拼接子模块
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.max_pool2d(out, 2)
out = F.relu(self.conv2(out))
out = F.max_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
# 权值的初始化
def initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data, 0, 0.1)
m.bias.data.zero_()
但是我们什么时候实现模型的拼接与前向传播呢?LeNet模型继承于Module,Module类中有__call__函数,__call__函数表明这一实例是可以像函数一样被调用的,__call__函数中会调用上面定义好的forword前向传播函数。
# Module类
def __call__(self, *input, **kwargs):
for hook in self._forward_pre_hooks.values():
result = hook(self, input)
if result is not None:
if not isinstance(result, tuple):
result = (result,)
input = result
if torch._C._get_tracing_state():
result = self._slow_forward(*input, **kwargs)
else:
# 前向传播
result = self.forward(*input, **kwargs)
for hook in self._forward_hooks.values():
hook_result = hook(self, input, result)
if hook_result is not None:
result = hook_result
if len(self._backward_hooks) > 0:
var = result
while not isinstance(var, torch.Tensor):
if isinstance(var, dict):
var = next((v for v in var.values() if isinstance(v, torch.Tensor)))
else:
var = var[0]
grad_fn = var.grad_fn
if grad_fn is not None:
for hook in self._backward_hooks.values():
wrapper = functools.partial(hook, self)
functools.update_wrapper(wrapper, hook)
grad_fn.register_hook(wrapper)
return result
net = LeNet(4)
print(net)
LeNet(
(conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=4, bias=True)
)
net(X)
net(X) 会调用LeNet 继承⾃自 Module 类的__call__函数,这个函数将调⽤用 LeNet 类定义的forward 函数来完成前向计算。
2.神经网络中常见的层
深度学习的一个魅力在于神经网络中各式各样的层,例如全连接层、卷积层、池化层与循环层等等。
2.1 卷积层
下面介绍几个概念:
- 卷积运算:卷积核在输入信号(图像)上滑动,相应位置上进行乘加。
- 卷积核:又称为滤波器,过滤器,可认为是某种模式,某种特征。

- 卷积维度:一般情况下,卷积核在几个维度上滑动,就是几维卷积。
PyTorch中提供了1d、2d、3d的卷积。
1d conv:
2d conv:
3d conv:



上述都是一个卷积核在一个信号上的卷积。如果涉及多个卷积核多个信号的操作,那么应该怎么判断卷积的维度?下面我们以一个三维卷积核实现二维卷积为例
每个卷积核分别在各自的通道进行卷积操作得到输出值,然后相加再加上偏置才会得到特征图的一个像素值。一个卷积核只在一个二维图像上进行滑动,所以这是二维卷积。为什么它是三维卷积核?正是因为它有多个通道,在多个通道上分别进行卷积。
nn.Conv2d:对多个二维信号进行二维卷积nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode= ' zeros ' )主要参数:
in_channels:输入通道数out_channels:输出通道数,等价于卷积核个数kernel_size:卷积核尺寸stride:步长padding:填充个数,用于保持输入与输出图像的尺寸是匹配的dilation:空洞卷积大小groups:分组卷积设置bias:偏置
尺寸计算公式为:
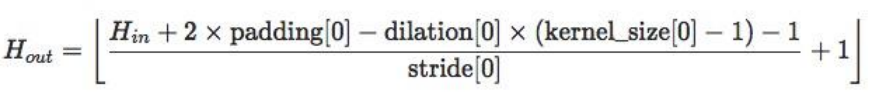
nn.ConvTranspose2d
nn.ConvTranspose2d是转置卷积。转置卷积用于对图像进行上采样(UpSample),经常用于图像分割任务。那么,什么是转置卷积?它与正常卷积有什么区别?如图是正常2d卷积。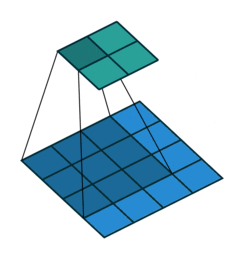
假设图像尺寸为4 ∗ 4 4*44∗4,卷积核为3 ∗ 3 3*33∗3,padding=0,stride=1
图像:? ? ∗ ? ??∗?16∗1, 卷积核: ? ∗ ? ? ?∗??4∗16 ,输出:? ∗ ? ?∗?4∗1 = ( ? ∗ ? ? ) ∗ ( ? ? ∗ ? ) (?∗??) ∗ (??∗?)(4∗16)∗(16∗1)
如图是转置卷积:
假设图像尺寸为2 ∗ 2 ,卷积核为 3 ∗ 3 2*2,卷积核为3*32∗2,卷积核为3∗3,padding=0,stride=1
图像:?∗? ,卷积核: ? ? ∗ ? ??∗?16∗4, 输出:? ? ∗ ? = ( ? ? ∗ ? ) ∗ ( ? ∗ 1 ) ??∗? = (??∗?) ∗ (?∗1)16∗1=(16∗4)∗(4∗1)
与正常卷积相比。转置卷积的卷积核在形状上与正常卷积是转置关系,虽然形状上转置,但是在权值上是完全不相同的,所以,正常卷积与转置卷积是完全不可逆的。
nn.ConvTranspose2d:转置卷积实现上采样。nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1, padding_mode='zeros')主要参数:
in_channels:输入通道数out_channels:输出通道数kernel_size:卷积核尺寸stride:步长padding:填充个数dilation:空洞卷积大小groups:分组卷积设置bias:偏置
转置卷积的尺寸计算:

转置卷积容易出现棋盘效应,解决办法推荐:《 Deconvolution and Checkerboard Artifacts》
2.2 池化层
池化运算就是对信号进行“收集”并“总结”。常见的池化方法有最大池化与平均池化。根据Boureau理论可以得出结论:在进行特征提取的过程中,均值池化可以减少邻域大小受限造成的估计值方差,但更多保留的是图像背景信息;而最大值池化能减少卷积层参数误差造成估计均值误差的偏移,能更多的保留纹理信息。随机池化虽然可以保留均值池化的信息,但是随机概率值确是人为添加的,随机概率的设置对结果影响较大,不可估计。

nn.MaxPool2d:对二维信号(图像)进行最大值池化nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)主要参数:
kernel_size:池化核尺寸stride:步长padding:填充个数dilation:池化核间隔大小ceil_mode:尺寸向上取整return_indices:记录池化像素索引
用于最大值反池化的过程中,将最大值放到对应的位置中
nn.AvgPool2d:对二维信号(图像)进行平均值池化nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, divisor_override=None)主要参数:
kernel_size:池化核尺寸stride:步长padding:填充个数ceil_mode:尺寸向上取整count_include_pad:填充值用于计算divisor_override:除法因子(可以根据任务需要,不是设置除以像素个数,而是除以除法因子)
nn.MaxUnpool2d:对二维信号(图像)进行最大值池化上采样
前面两个池化操作均是下采样的过程。这里我们介绍上采样池化操作。nn.MaxUnpool2d(kernel_size, stride=None, padding=0) forward(self, input, indices, output_size=None)主要参数:
kernel_size:池化核尺寸stride:步长padding:填充个数
# 初始化图片 img_tensor = torch.randint(high=5, size=(1, 1, 4, 4), dtype=torch.float) # 最大值池化 maxpool_layer = nn.MaxPool2d((2, 2), stride=(2, 2), return_indices=True) img_pool, indices = maxpool_layer(img_tensor) # unpooling # 反池化的输入 img_reconstruct = torch.randn_like(img_pool, dtype=torch.float) # 最大值反池化 maxunpool_layer = nn.MaxUnpool2d((2, 2), stride=(2, 2)) img_unpool = maxunpool_layer(img_reconstruct, indices) print("raw_img:\n{}\nimg_pool:\n{}".format(img_tensor, img_pool)) print("img_reconstruct:\n{}\nimg_unpool:\n{}".format(img_reconstruct, img_unpool))raw_img: tensor([[[[0., 4., 4., 3.], [3., 3., 1., 1.], [4., 2., 3., 4.], [1., 3., 3., 0.]]]]) img_pool: tensor([[[[4., 4.], [4., 4.]]]]) img_reconstruct: tensor([[[[-1.0276, -0.5631], [-0.8923, -0.0583]]]]) img_unpool: tensor([[[[ 0.0000, -1.0276, -0.5631, 0.0000], [ 0.0000, 0.0000, 0.0000, 0.0000], [-0.8923, 0.0000, 0.0000, -0.0583], [ 0.0000, 0.0000, 0.0000, 0.0000]]]])
2.3 线性层
线性层又称全连接层,其每个神经元与上一层所有神经元相连实现对前一层的线性组合,线性变换。
nn.Linear:对一维信号(向量)进行线性组合nn.Linear(in_features, out_features, bias=True)主要参数:
in_features:输入结点数out_features:输出结点数bias:是否需要偏置
计算公式:y = ? ? ? + ? ? ? ? y = ??^? + ????y=xWT+bias
下面,我们通过代码构建3个输入节点,4个隐藏节点的模型inputs = torch.tensor([[1., 2, 3]]) linear_layer = nn.Linear(3, 4) # 权值矩阵进行初始化 linear_layer.weight.data = torch.tensor([[1., 1., 1.], [2., 2., 2.], [3., 3., 3.], [4., 4., 4.]]) # 增加偏置 linear_layer.bias.data.fill_(0.5) # 输出 output = linear_layer(inputs) print(inputs, inputs.shape) print(linear_layer.weight.data, linear_layer.weight.data.shape) print(output, output.shape)tensor([[1., 2., 3.]]) torch.Size([1, 3]) tensor([[1., 1., 1.], [2., 2., 2.], [3., 3., 3.], [4., 4., 4.]]) torch.Size([4, 3]) tensor([[ 6.5000, 12.5000, 18.5000, 24.5000]], grad_fn=<AddmmBackward>) torch.Size([1, 4])
2.4 激活函数层
激活函数对特征进行非线性变换,赋予多层神经网络具有深度的意义。如果不用非线性激励函数,每一层都是上一层的线性函数,无论神经网络多少层,输出都是输入的线性组合,所以引入非线性激励函数,深层网络就变得有意义了,可以逼近任意函数。
nn.Sigmoid
计算公式:? = ? ? + ? − x ? = \frac{?} {?+?^{−x}}y=1+e−x1
梯度公式:? ′ = ? ∗ ( ? − ? ) ?′ = ? ∗ (? − ?)y′=y∗(1−y)
特性:
- 输出值在(0,1),符合概率
- 导数范围是[0, 0.25],易导致梯度消失
- 输出为非0均值,破坏数据分布
nn.tanh
计算公式:
? = s i n ? ? ? ? ? = ? ? − ? − ? ? x + ? − ? = ? ? + ? − ? ? + ? ? =\frac{ s in?} {????} = \frac{?^?−?^{−?}} {?^x +?^{−?}} = \frac{?} {?+?^{−??}} + ?y=cosxsinx=ex+e−xex−e−x=1+e−2x2+1
梯度公式:? ′ = ? − y ? ?′ = ? − y^?y′=1−y2
特性:
- 输出值在(-1,1),数据符合0均值
- 导数范围是(0, 1),易导致梯度消失
nn.ReLU
计算公式:? = m a x ( ? , ? ) ? = max(?, ?)y=max(0,x)
特性:
- 输出值均为正数,负半轴导致死神经元
- 导数是1,缓解梯度消失,但易引发梯度爆
炸
由于负半轴容易导致神经元死亡,所以,出现了许多ReLU变体,
4. nn.LeakyReLU
- negative_slope: 负半轴斜率
nn.PReLU
- init: 可学习斜率
nn.RReLU
- lower: 均匀分布下限
- upper:均匀分布上限
其图像对比如下: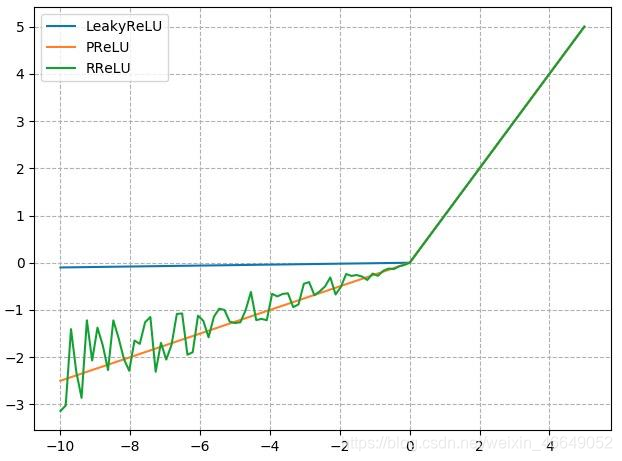
2.5 自定义层
虽然PyTorch提供了⼤量常用的层,但有时候我们依然希望⾃定义层。这里我们会介绍如何使用 Module 来自定义层,从而可以被反复调用。
不含模型参数的层
如何定义一个不含模型参数的自定义层。下⾯构造的MyLayer类通过继承Module类自定义了一个将输入减掉均值后输出的层,并将层的计算定义在了forward函数里。这个层里不含模型参数。import torch from torch import nn class MyLayer(nn.Module): def __init__(self, **kwargs): super(MyLayer, self).__init__(**kwargs) def forward(self, x): return x - x.mean()测试,实例化该层,然后做前向计算
layer = MyLayer() layer(torch.tensor([1, 2, 3, 4, 5], dtype=torch.float))tensor([-2., -1., 0., 1., 2.])含模型参数的层
自定义含模型参数的自定义层。其中的模型参数可以通过训练学出。Parameter类其实是Tensor的子类,如果一 个Tensor是Parameter,那么它会⾃动被添加到模型的参数列表里。所以在⾃定义含模型参数的层时,我们应该将参数定义成Parameter,除了直接定义成Parameter类外,还可以使⽤ParameterList和ParameterDict分别定义参数的列表和字典。class MyListDense(nn.Module): def __init__(self): super(MyListDense, self).__init__() self.params = nn.ParameterList([nn.Parameter(torch.randn(4, 4)) for i in range(3)]) self.params.append(nn.Parameter(torch.randn(4, 1))) def forward(self, x): for i in range(len(self.params)): x = torch.mm(x, self.params[i]) return x net = MyListDense() print(net)MyListDense( (params): ParameterList( (0): Parameter containing: [torch.FloatTensor of size 4x4] (1): Parameter containing: [torch.FloatTensor of size 4x4] (2): Parameter containing: [torch.FloatTensor of size 4x4] (3): Parameter containing: [torch.FloatTensor of size 4x1] ) )class MyDictDense(nn.Module): def __init__(self): super(MyDictDense, self).__init__() self.params = nn.ParameterDict({ 'linear1': nn.Parameter(torch.randn(4, 4)), 'linear2': nn.Parameter(torch.randn(4, 1)) }) self.params.update({'linear3': nn.Parameter(torch.randn(4, 2))}) # 新增 def forward(self, x, choice='linear1'): return torch.mm(x, self.params[choice]) net = MyDictDense() print(net)MyDictDense( (params): ParameterDict( (linear1): Parameter containing: [torch.FloatTensor of size 4x4] (linear2): Parameter containing: [torch.FloatTensor of size 4x1] (linear3): Parameter containing: [torch.FloatTensor of size 4x2] ) )二维卷积层
二维卷积层将输入和卷积核做互相关运算,并加上一个标量偏差来得到输出。卷积层的模型参数包括了卷积核和标量偏差。在训练模型的时候,通常我们先对卷积核随机初始化,然后不断迭代卷积核和偏差。import torch from torch import nn # 卷积运算(二维互相关) def corr2d(X, K): h, w = K.shape X, K = X.float(), K.float() Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1)) for i in range(Y.shape[0]): for j in range(Y.shape[1]): Y[i, j] = (X[i: i + h, j: j + w] * K).sum() return Y # 二维卷积层 class Conv2D(nn.Module): def __init__(self, kernel_size): super(Conv2D, self).__init__() self.weight = nn.Parameter(torch.randn(kernel_size)) self.bias = nn.Parameter(torch.randn(1)) def forward(self, x): return corr2d(x, self.weight) + self.bias池化层
池化层每次对输入数据的一个固定形状窗口(⼜称池化窗口)中的元素计算输出。不同于卷积层里计算输⼊和核的互相关性,池化层直接计算池化窗口内元素的最大值或者平均值。该运算也分别叫做最大池化或平均池化。在二维最⼤池化中,池化窗口从输入数组的最左上方开始,按从左往右、从上往下的顺序,依次在输⼊数组上滑动。当池化窗口滑动到某⼀位置时,窗口中的输入子数组的最大值即输出数组中相应位置的元素。下面把池化层的前向计算实现在pool2d函数里。import torch from torch import nn def pool2d(X, pool_size, mode='max'): p_h, p_w = pool_size Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1)) for i in range(Y.shape[0]): for j in range(Y.shape[1]): if mode == 'max': Y[i, j] = X[i: i + p_h, j: j + p_w].max() elif mode == 'avg': Y[i, j] = X[i: i + p_h, j: j + p_w].mean() return Y
3.nn.Module
在模型模块有一个非常重要的概念是nn.Module,所有的模型、所有的网络层都是继承于nn.Module类的。下面我们先介绍一下torch.nn。
这一节我们的重点是nn.Module,nn.Module的属性如下:
parameters:存储管理nn.Parameter类
比如:权值、偏置等这些参数modules:存储管理nn.Module类
比如:在LeNet模型中的卷积层、池化层buffers:存储管理缓冲属性,如BN层中的running_mean_hooks:存储管理钩子函数self._parameters = OrderedDict() self._buffers = OrderedDict() self._backward_hooks = OrderedDict() self._forward_hooks = OrderedDict() self._forward_pre_hooks = OrderedDict() self._state_dict_hooks = OrderedDict() self._load_state_dict_pre_hooks = OrderedDict() self._modules = OrderedDict()
注:在Module模块中有一个机制:拦截所有类属性赋值语句,会跳转到Module中的__setattr__函数
def __setattr__(self, name, value):
def remove_from(*dicts):
for d in dicts:
if name in d:
del d[name]
params = self.__dict__.get('_parameters')
if isinstance(value, Parameter):
if params is None:
raise AttributeError(
"cannot assign parameters before Module.__init__() call")
remove_from(self.__dict__, self._buffers, self._modules)
self.register_parameter(name, value)
elif params is not None and name in params:
if value is not None:
raise TypeError("cannot assign '{}' as parameter '{}' "
"(torch.nn.Parameter or None expected)"
.format(torch.typename(value), name))
self.register_parameter(name, value)
else:
modules = self.__dict__.get('_modules')
if isinstance(value, Module):
if modules is None:
raise AttributeError(
"cannot assign module before Module.__init__() call")
remove_from(self.__dict__, self._parameters, self._buffers)
modules[name] = value
elif modules is not None and name in modules:
if value is not None:
raise TypeError("cannot assign '{}' as child module '{}' "
"(torch.nn.Module or None expected)"
.format(torch.typename(value), name))
modules[name] = value
else:
buffers = self.__dict__.get('_buffers')
if buffers is not None and name in buffers:
if value is not None and not isinstance(value, torch.Tensor):
raise TypeError("cannot assign '{}' as buffer '{}' "
"(torch.Tensor or None expected)"
.format(torch.typename(value), name))
buffers[name] = value
else:
object.__setattr__(self, name, value)
这个函数的主要作用是:对value的数据类型进行判断,
- 判断是否为
Parameters属性,如果是的话,就存储到register_parameter字典中 - 判断是否为
Module属性,如果是的话,就存储到modules字典中
nn.Module总结:
- 一个
module可以包含多个子module - 一个
module相当于一个运算,必须实现forward()函数 - 每个
module都有8个字典管理它的属性
五、模型初始化
在深度学习模型的训练中,权重的初始值极为重要。一个好的权重值,会使模型收敛速度提高,使模型准确率更精确。为了利于训练和减少收敛时间,我们需要对模型进行合理的初始化。PyTorch在torch.nn.init中为我们提供了常用的初始化方法。我们通常会根据实际模型来使用torch.nn.init进行初始化,通常使用isinstance来进行判断模块属于什么类型。对于不同的类型层,我们就可以设置不同的权值初始化的方法。
1.梯度消失与爆炸
恰当的权值初始化可以加速收敛,不当的权值初始化会导致梯度爆炸或梯度消失,最终导致模型无法训练。下面我们了解不恰当的权值初始化是如何导致梯度消失与爆炸的?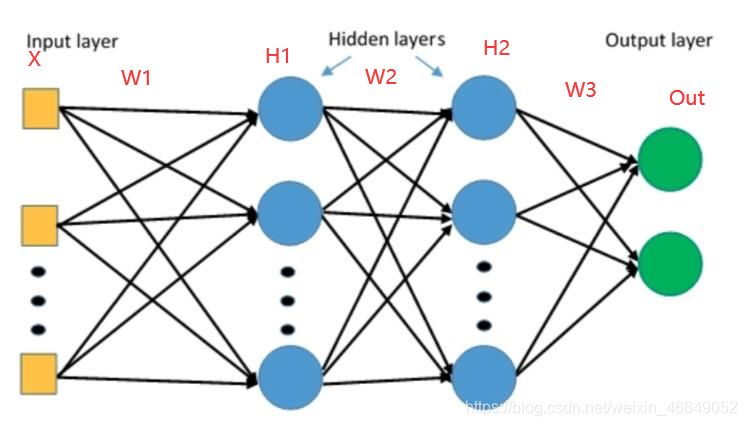

我们可以知道要避免梯度消失与爆炸,要严格控制网络输出层的输出值的尺度范围,使得每一层的输出值不能太大也不能太小。
class MLP(nn.Module):
def __init__(self, neural_num, layers):
super(MLP, self).__init__()
self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
self.neural_num = neural_num
def forward(self, x):
for (i, linear) in enumerate(self.linears):
x = linear(x)
# x = torch.relu(x)
print("layer:{}, std:{}".format(i, x.std()))
if torch.isnan(x.std()):
print("output is nan in {} layers".format(i))
break
return x
def initialize(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data) # normal: mean=0, std=1
layer_nums = 100
neural_nums = 256
batch_size = 16
net = MLP(neural_nums, layer_nums)
net.initialize()
inputs = torch.randn((batch_size, neural_nums)) # normal: mean=0, std=1
output = net(inputs)
print(output)
layer:0, std:16.27458381652832
layer:1, std:258.77801513671875
layer:2, std:4141.2744140625
layer:3, std:65769.9140625
layer:4, std:1037747.625
layer:5, std:16792116.0
layer:6, std:270513248.0
layer:7, std:4271523072.0
layer:8, std:69773983744.0
layer:9, std:1135388917760.0
layer:10, std:17972382924800.0
layer:11, std:290361566035968.0
layer:12, std:4646467956375552.0
layer:13, std:7.375517986167194e+16
layer:14, std:1.191924480578945e+18
layer:15, std:1.9444053896660517e+19
layer:16, std:3.0528445240940115e+20
layer:17, std:4.825792774212115e+21
layer:18, std:7.649714347139797e+22
layer:19, std:1.2594570721248546e+24
layer:20, std:2.009953775506879e+25
layer:21, std:3.221620181771679e+26
layer:22, std:5.130724860334453e+27
layer:23, std:8.456056429939108e+28
layer:24, std:1.337131496090396e+30
layer:25, std:2.1005011162403366e+31
layer:26, std:3.2537079800422226e+32
layer:27, std:5.275016630929896e+33
layer:28, std:8.364601398774255e+34
layer:29, std:1.3522442523642847e+36
layer:30, std:2.1151457613842935e+37
layer:31, std:nan
output is nan in 31 layers
tensor([[ -inf, -inf, -inf, ..., -inf,
1.1685e+38, 1.4362e+38],
[-2.9867e+38, 2.6396e+35, 1.1949e+38, ..., 8.2088e+37,
1.9041e+38, -5.0897e+37],
[-1.4351e+38, 9.9710e+37, -1.4595e+37, ..., 4.2070e+36,
-inf, -1.2583e+38],
...,
[ inf, inf, inf, ..., 1.6265e+38,
1.3557e+38, -inf],
[-1.2538e+38, -1.9771e+38, -inf, ..., -1.8160e+38,
1.0576e+38, inf],
[ inf, 5.5094e+37, -4.4087e+36, ..., -inf,
-2.4495e+38, 7.9425e+37]], grad_fn=<MmBackward>)
下面我们通过方差公式推导来观察网络层输出的标准差为什么会越来越大?最终会超出我们要表示的范围。
E ( ? ∗ ? ) = ? ( ? ) ∗ ? ( ? ) D ( ? ) = ? ( X ? ) − [ ? ( ? ) ] ? D ( ? + ? ) = ? ( ? ) + ? ( ? ) D ( X ∗ Y ) = D ( X ) ∗ D ( Y ) + D ( X ) ∗ [ ? ( ? ) ] ? + D ( Y ) ∗ [ ? ( ? ) ] ? E(? ∗ ?) = ?(?) ∗ ?(?)\\D(?) = ?(X^?) − [?(?)]^?\\D(? + ?) = ?(?) + ?(?)\\D(X*Y) = D(X)*D(Y) + D(X)* [?(?)]^? + D(Y)* [?(?)]^?E(X∗Y)=E(X)∗E(Y)D(X)=E(X2)−[E(X)]2D(X+Y)=D(X)+D(Y)D(X∗Y)=D(X)∗D(Y)+D(X)∗[E(Y)]2+D(Y)∗[E(X)]2
若E ( X ) = 0 , E ( Y ) = 0 E(X)=0, E(Y)=0E(X)=0,E(Y)=0,
D ( X ∗ Y ) = D ( X ) ∗ D ( Y ) D(X*Y) = D(X)*D(Y)D(X∗Y)=D(X)∗D(Y)
H ? ? = ∑ ? = ? ? ? ? ∗ ? 1 i ? ( H ? ? ) = ∑ ? = ? ? ? ( ? ? ) ∗ ? ( ? ? ? ) = n ∗ ( 1 ∗ 1 ) = n H_{??} = \sum_{?=?}^? ?_? ∗ ?_{1i}\\?(H_{??}) = \sum_{?=?}^??(?_?) ∗ ?(?_{??})\\= n * (1 * 1)= nH11=i=0∑nXi∗W1iD(H11)=i=0∑nD(Xi)∗D(W1i)=n∗(1∗1)=n
s t d ( H ? ? ) = D ( H 11 ) = ? std(H_{??}) =\sqrt{D(H_{11})}= \sqrt{?}std(H11)=D(H11)=n
为了保持尺度不变,我们需要使得方差等于1。
? ( H ? ) = ? ∗ ? ( ? ) ∗ ? ( ? ) = ? ?(H_?) = ? ∗ ?(?) ∗ ?(?) = ?D(H1)=n∗D(X)∗D(W)=1
? ( ? ) = ? ? ⇒ s t d ( W ) = 1 n ?(?) = \frac{?}{?} ⇒ std(W) =\sqrt{\frac{1}{n}}D(W)=n1⇒std(W)=n1
当我们权值的标准差设置为1 n \sqrt{\frac{1}{n}}n1时,我们每一个网络层输出的标准差都为1。
class MLP(nn.Module):
def __init__(self, neural_num, layers):
super(MLP, self).__init__()
self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
self.neural_num = neural_num
def forward(self, x):
for (i, linear) in enumerate(self.linears):
x = linear(x)
# x = torch.relu(x)
print("layer:{}, std:{}".format(i, x.std()))
if torch.isnan(x.std()):
print("output is nan in {} layers".format(i))
break
return x
def initialize(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data, std=np.sqrt(1/self.neural_num)) # normal: mean=0, std=1
layer_nums = 100
neural_nums = 256
batch_size = 16
net = MLP(neural_nums, layer_nums)
net.initialize()
inputs = torch.randn((batch_size, neural_nums)) # normal: mean=0, std=1
output = net(inputs)
print(output)
layer:0, std:1.01716148853302
layer:1, std:1.0108516216278076
layer:2, std:1.0110533237457275
layer:3, std:1.00356924533844
layer:4, std:0.9896732568740845
layer:5, std:1.0008881092071533
layer:6, std:1.0077403783798218
layer:7, std:0.9945414662361145
layer:8, std:1.0153450965881348
layer:9, std:1.032630205154419
layer:10, std:1.0216116905212402
layer:11, std:1.0315715074539185
layer:12, std:1.031723141670227
layer:13, std:1.0235587358474731
layer:14, std:1.033829689025879
layer:15, std:1.0540642738342285
layer:16, std:1.034343957901001
layer:17, std:1.0219013690948486
layer:18, std:1.012431263923645
layer:19, std:1.04179847240448
layer:20, std:1.0391217470169067
layer:21, std:1.0409616231918335
layer:22, std:1.0361416339874268
layer:23, std:1.0673043727874756
layer:24, std:1.0548107624053955
layer:25, std:1.035627007484436
layer:26, std:1.0026261806488037
layer:27, std:1.015931248664856
layer:28, std:1.0068522691726685
layer:29, std:1.0173155069351196
layer:30, std:0.9945367574691772
layer:31, std:1.0197739601135254
layer:32, std:1.0098663568496704
layer:33, std:1.0061081647872925
layer:34, std:1.0183264017105103
layer:35, std:1.027289628982544
layer:36, std:1.0039222240447998
layer:37, std:0.9884308576583862
layer:38, std:0.9733569025993347
layer:39, std:0.9643504619598389
layer:40, std:0.9961804151535034
layer:41, std:0.9727191925048828
layer:42, std:0.9612295031547546
layer:43, std:0.9077887535095215
layer:44, std:0.9031966924667358
layer:45, std:0.9317508339881897
layer:46, std:0.9114648699760437
layer:47, std:0.9325807690620422
layer:48, std:0.9167572259902954
layer:49, std:0.9143604636192322
layer:50, std:0.917384684085846
layer:51, std:0.9133910536766052
layer:52, std:0.8762374520301819
layer:53, std:0.8490192294120789
layer:54, std:0.8705357909202576
layer:55, std:0.8841084241867065
layer:56, std:0.8875617384910583
layer:57, std:0.8947452306747437
layer:58, std:0.87960284948349
layer:59, std:0.9139573574066162
layer:60, std:0.876527726650238
layer:61, std:0.8890507817268372
layer:62, std:0.8742848634719849
layer:63, std:0.8995197415351868
layer:64, std:0.9074675440788269
layer:65, std:0.9094378352165222
layer:66, std:0.8995903730392456
layer:67, std:0.935014009475708
layer:68, std:0.9270139336585999
layer:69, std:0.9080401062965393
layer:70, std:0.8906367421150208
layer:71, std:0.8921653032302856
layer:72, std:0.8771474957466125
layer:73, std:0.8739159107208252
layer:74, std:0.8812178373336792
layer:75, std:0.8809882998466492
layer:76, std:0.9242010712623596
layer:77, std:0.9175798296928406
layer:78, std:0.9541298747062683
layer:79, std:1.0111076831817627
layer:80, std:1.0219817161560059
layer:81, std:0.9918409585952759
layer:82, std:0.9796289801597595
layer:83, std:1.0197941064834595
layer:84, std:1.0080797672271729
layer:85, std:1.0413453578948975
layer:86, std:1.0896474123001099
layer:87, std:1.0899057388305664
layer:88, std:1.0252294540405273
layer:89, std:1.0135066509246826
layer:90, std:0.9950422048568726
layer:91, std:1.0702030658721924
layer:92, std:1.057084560394287
layer:93, std:1.0474439859390259
layer:94, std:1.029062271118164
layer:95, std:1.080614686012268
layer:96, std:1.1043109893798828
layer:97, std:1.1484302282333374
layer:98, std:1.0932420492172241
layer:99, std:1.1118167638778687
tensor([[ 0.0911, 0.4247, -0.5326, ..., -0.6535, -0.9329, -0.0994],
[-1.4039, -1.9454, -1.1041, ..., -1.2143, 0.3651, 1.6811],
[-0.2120, -1.5315, -0.3237, ..., 1.8603, 1.4694, 0.4126],
...,
[-0.3822, 1.4348, 0.0490, ..., -0.2949, -0.4052, 0.1516],
[-1.0262, -1.3941, -0.7352, ..., 1.1347, 0.4708, 3.3663],
[-0.1224, 1.3998, -0.6474, ..., -0.5669, -2.4370, 2.2353]],
grad_fn=<MmBackward>)
通过代码的实践,我们验证了公式推导的正确。我们使用恰当的权值初始化方法,可以实现多层的全连接网络的输出值的尺度维持在一定的范围之内。
上述过程我们并没有考虑到激活函数的存在,下面我们讨论带激活函数的权值初始化。
class MLP(nn.Module):
def __init__(self, neural_num, layers):
super(MLP, self).__init__()
self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
self.neural_num = neural_num
def forward(self, x):
for (i, linear) in enumerate(self.linears):
x = linear(x)
x = torch.relu(x)
print("layer:{}, std:{}".format(i, x.std()))
if torch.isnan(x.std()):
print("output is nan in {} layers".format(i))
break
return x
def initialize(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data, std=np.sqrt(1/self.neural_num)) # normal: mean=0, std=1
layer_nums = 100
neural_nums = 256
batch_size = 16
net = MLP(neural_nums, layer_nums)
net.initialize()
inputs = torch.randn((batch_size, neural_nums)) # normal: mean=0, std=1
output = net(inputs)
print(output)
layer:0, std:0.5899198651313782
layer:1, std:0.41571885347366333
layer:2, std:0.3136396110057831
layer:3, std:0.22328709065914154
layer:4, std:0.16081058979034424
layer:5, std:0.11673301458358765
layer:6, std:0.08193019032478333
layer:7, std:0.05659937858581543
...
layer:96, std:1.0717714345889555e-15
layer:97, std:8.317196503591267e-16
layer:98, std:5.498295736721781e-16
layer:99, std:3.884194516994314e-16
tensor([[0.0000e+00, 5.0063e-16, 0.0000e+00, ..., 0.0000e+00, 0.0000e+00,
6.6322e-16],
[0.0000e+00, 2.8290e-16, 0.0000e+00, ..., 0.0000e+00, 0.0000e+00,
3.9667e-16],
[0.0000e+00, 3.7964e-16, 0.0000e+00, ..., 0.0000e+00, 0.0000e+00,
5.0887e-16],
...,
[0.0000e+00, 2.9831e-16, 0.0000e+00, ..., 0.0000e+00, 0.0000e+00,
4.0538e-16],
[0.0000e+00, 2.5206e-16, 0.0000e+00, ..., 0.0000e+00, 0.0000e+00,
3.3738e-16],
[0.0000e+00, 3.0986e-16, 0.0000e+00, ..., 0.0000e+00, 0.0000e+00,
4.1061e-16]], grad_fn=<ReluBackward0>)
我们发现:随着网络层的前向传播,网络层的标准差越来越小,从而会导致梯度消失。
2.Xavier方法与Kaiming方法
针对带激活函数的权值初始化问题讨论
2.1 Xavier方法
这个方法涉及方差一致性原则:保持数据尺度维持在恰当范围,通常方差为1。针对激活函数:饱和函数,如Sigmoid,Tanh来进行分析。考虑前向传播与反向传播的尺度问题并结合方差一致性准则得到如下等式:
? ? ∗ ? ( ? ) = ? ? ? + ? ∗ ? ( ? ) = ? ⇒ ? ( ? ) = ? ? ? + ? ? + 1 ?_? ∗ ?(?) = ?\\ ?_{?+?} ∗ ?(?) = ?\\⇒ ?(?) = \frac{?}{?_?+?_{?+1}}ni∗D(W)=1ni+1∗D(W)=1⇒D(W)=ni+ni+12
n i n_ini为输入层神经元个数;n i + 1 n_{i+1}ni+1为输出层神经元个数,通常w ww采用均匀分布,下面我们推导均匀分布的上界与下界。
? ∽ ? [ − ? , ? ] ? ( ? ) = ( − ? − ? ) ? ? ? = ( ? ? ) ? ? ? = ? ? ? ? ? ? + ? ? + ? = ? ? ? ⇒ ? = ? ? ? + ? ? + ? ⇒ ? ∽ ? [ − ? ? ? + ? ? + ? , ? ? ? + ? ? + ? ] ? ∽ ?[ −?, ?]\\?(?) = \frac{(−?−?)^?}{??}= \frac{(??)?}{??}= \frac{?^?}{?}\\\frac{?}{?_?+?_{?+?}} = \frac{?^?}{?} ⇒ ? = \frac{?}{?_?+?_{?+?}} ⇒ ? ∽ ?[\frac{− ?}{?_?+?_{?+?}} , \frac{ ?}{?_?+?_{?+?}}]W∽U[−a,a]D(W)=12(−a−a)2=12(2a)2=3a2ni+ni+12=3a2⇒a=ni+ni+16⇒W∽U[ni+ni+1−6,ni+ni+16]
下面通过代码来进行理解
class MLP(nn.Module):
def __init__(self, neural_num, layers):
super(MLP, self).__init__()
self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
self.neural_num = neural_num
def forward(self, x):
for (i, linear) in enumerate(self.linears):
x = linear(x)
x = torch.tanh(x)
print("layer:{}, std:{}".format(i, x.std()))
if torch.isnan(x.std()):
print("output is nan in {} layers".format(i))
break
return x
def initialize(self):
for m in self.modules():
if isinstance(m, nn.Linear):
# 上下限尺度
a = np.sqrt(6 / (self.neural_num + self.neural_num))
# 计算激活函数的增益:数据输入到激活函数后标准差的变化
tanh_gain = nn.init.calculate_gain('tanh')
# 得到最终的均匀分布的尺度
a *= tanh_gain
# 均匀分布权值初始化,上限是a,下限是-a
nn.init.uniform_(m.weight.data, -a, a)
# pytorch自带Xavier方法
# nn.init.xavier_uniform_(m.weight.data, gain=tanh_gain)
layer_nums = 100
neural_nums = 256
batch_size = 16
net = MLP(neural_nums, layer_nums)
net.initialize()
inputs = torch.randn((batch_size, neural_nums)) # normal: mean=0, std=1
output = net(inputs)
print(output)
layer:0, std:0.765204131603241
layer:1, std:0.6946892142295837
layer:2, std:0.6673060655593872
layer:3, std:0.6655793190002441
layer:4, std:0.6548998355865479
layer:5, std:0.6439622044563293
layer:6, std:0.6522637009620667
layer:7, std:0.6470122337341309
layer:8, std:0.6478358507156372
layer:9, std:0.653320848941803
layer:10, std:0.6542279720306396
...
layer:88, std:0.6447835564613342
layer:89, std:0.65509033203125
layer:90, std:0.6524420976638794
layer:91, std:0.6497730612754822
layer:92, std:0.6551639437675476
layer:93, std:0.6409233212471008
layer:94, std:0.6488484144210815
layer:95, std:0.6518734693527222
layer:96, std:0.6608843803405762
layer:97, std:0.6564308404922485
layer:98, std:0.6543230414390564
layer:99, std:0.6533558964729309
tensor([[ 0.3646, 0.9605, 0.3257, ..., 0.3060, 0.8221, 0.2992],
[-0.9779, -0.3418, -0.0221, ..., -0.9697, 0.3601, 0.8525],
[ 0.7034, -0.9712, 0.4783, ..., 0.5189, 0.5874, 0.8694],
...,
[-0.8404, -0.3793, -0.9862, ..., 0.6260, 0.3465, -0.4905],
[-0.6254, -0.5310, 0.8628, ..., 0.4114, -0.9523, -0.4161],
[ 0.9216, -0.0474, -0.9073, ..., 0.5973, -0.8822, -0.8055]],
grad_fn=<TanhBackward>)
我们发现使用Xavier方法后,标准差都能够维持在0.65左右,即每个网络的输出值比较稳定。非饱和激活函数已经广泛使用,由于非饱和激活函数的性质,Xavier方法不在适用。Kaiming初始化可以解决这个问题。
nn.init.calculate_gain
nn.init.calculate_gain(nonlinearity, param=None)
主要功能:计算激活函数的方差变化尺度,即输入数据的方差除以输出数据的方差
主要参数
- nonlinearity: 激活函数名称
- param: 激活函数的参数,如Leaky ReLU的negative_slop
2.2 Kaiming初始化
这个方法基于方差一致性准则:保持数据尺度维持在恰当范围,通常方差为1。针对激活函数:ReLU及其变种。 根据公式推导,可以得到权值的方差为:
D ( ? ) = ? ? ? R e L U 的变种 ( 负半轴会有一定的斜率 ) : D ( ? ) = ? ( ? + a ? ) ∗ ? ? s t d ( ? ) = ? ( ? + a ? ) ∗ ? ? D(?) = \frac{?}{?_?}\\ReLU的变种(负半轴会有一定的斜率):D(?) = \frac{?}{(?+a^?) ∗ ?_?}\\std(?) = \sqrt{\frac{?}{(?+a^?) ∗ ?_?}}D(W)=ni2ReLU的变种(负半轴会有一定的斜率):D(W)=(1+a2)∗ni2std(W)=(1+a2)∗ni2
n i n_ini为输入层的神经元个数,a aa为负半轴的斜率
class MLP(nn.Module):
def __init__(self, neural_num, layers):
super(MLP, self).__init__()
self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
self.neural_num = neural_num
def forward(self, x):
for (i, linear) in enumerate(self.linears):
x = linear(x)
x = torch.relu(x)
print("layer:{}, std:{}".format(i, x.std()))
if torch.isnan(x.std()):
print("output is nan in {} layers".format(i))
break
return x
def initialize(self):
for m in self.modules():
if isinstance(m, nn.Linear):
# 自定义Kaiming方法
nn.init.normal_(m.weight.data, std=np.sqrt(2 / self.neural_num))
# pytorch方法
# nn.init.kaiming_normal_(m.weight.data)
layer_nums = 100
neural_nums = 256
batch_size = 16
net = MLP(neural_nums, layer_nums)
net.initialize()
inputs = torch.randn((batch_size, neural_nums)) # normal: mean=0, std=1
output = net(inputs)
print(output)
layer:0, std:0.8342726230621338
layer:1, std:0.8314377069473267
layer:2, std:0.8871067762374878
layer:3, std:0.8931483030319214
layer:4, std:0.9096819758415222
layer:5, std:0.9338640570640564
layer:6, std:0.9269343018531799
layer:7, std:0.9055899381637573
layer:8, std:0.926615297794342
layer:9, std:0.8867263793945312
layer:10, std:0.7347306609153748
...
layer:91, std:0.6690114140510559
layer:92, std:0.6205857396125793
layer:93, std:0.5972729325294495
layer:94, std:0.5790647268295288
layer:95, std:0.513373851776123
layer:96, std:0.42663493752479553
layer:97, std:0.4682159423828125
layer:98, std:0.4377360939979553
layer:99, std:0.43732091784477234
tensor([[0.0000, 0.5637, 0.0000, ..., 0.0000, 0.0000, 0.7467],
[0.0000, 0.3185, 0.0000, ..., 0.0000, 0.0000, 0.4466],
[0.0000, 0.4274, 0.0000, ..., 0.0000, 0.0000, 0.5729],
...,
[0.0000, 0.3359, 0.0000, ..., 0.0000, 0.0000, 0.4564],
[0.0000, 0.2838, 0.0000, ..., 0.0000, 0.0000, 0.3799],
[0.0000, 0.3489, 0.0000, ..., 0.0000, 0.0000, 0.4623]],
grad_fn=<ReluBackward0>)
3.初始化函数的封装
人们常常将各种初始化方法定义为一个initialize_weights()的函数并在模型初始后进行使用。该函数就是遍历当前模型的每一层,然后判断各层属于什么类型,然后根据不同类型层,设定不同的权值初始化方法。
# 模型的定义
class MLP(nn.Module):
# 声明带有模型参数的层,这里声明了两个全连接层
def __init__(self, **kwargs):
# 调用MLP父类Block的构造函数来进行必要的初始化。这样在构造实例时还可以指定其他函数
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Conv2d(1,1,3)
self.act = nn.ReLU()
self.output = nn.Linear(10,1)
# 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出
def forward(self, x):
o = self.act(self.hidden(x))
return self.output(o)
def initialize_weights(self):
for m in self.modules():
# 判断是否属于Conv2d
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal_(m.weight.data)
# 判断是否有偏置
if m.bias is not None:
torch.nn.init.constant_(m.bias.data,0.3)
elif isinstance(m, nn.Linear):
torch.nn.init.normal_(m.weight.data, 0.1)
if m.bias is not None:
torch.nn.init.zeros_(m.bias.data)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zeros_()
mlp = MLP()
print(list(mlp.parameters()))
print("-------初始化-------")
mlp.initialize_weights()
print(list(mlp.parameters()))
[Parameter containing:
tensor([[[[ 0.0968, -0.0723, -0.2772],
[ 0.3266, -0.3268, 0.3195],
[ 0.1263, 0.1855, 0.2337]]]], requires_grad=True),
Parameter containing:
tensor([-0.2880], requires_grad=True),
Parameter containing:
tensor([[ 0.0453, 0.2581, 0.1014, 0.1765, 0.2864, -0.1894, -0.0127, 0.3000,
-0.1067, -0.0829]], requires_grad=True),
Parameter containing:
tensor([-0.0189], requires_grad=True)]
-------初始化-------
[Parameter containing:
tensor([[[[-0.3306, -0.0131, 0.2998],
[ 0.2294, -0.2523, 0.2135],
[-0.3122, -0.4325, -0.0451]]]], requires_grad=True),
Parameter containing:
tensor([0.3000], requires_grad=True),
Parameter containing:
tensor([[-0.0098, -1.2688, 0.5434, -0.6100, -0.9181, 1.4148, 0.9048, -0.2659,
-1.3219, 0.3193]], requires_grad=True),
Parameter containing:
tensor([0.], requires_grad=True)]
六、损失函数
在PyTorch中,损失函数是必不可少的。它是数据输入到模型当中,产生的结果与真实标签的评价指标,我们的模型可以按照损失函数的目标来做出改进。
1.损失函数的概念
损失函数:衡量模型输出与真实标签的差异。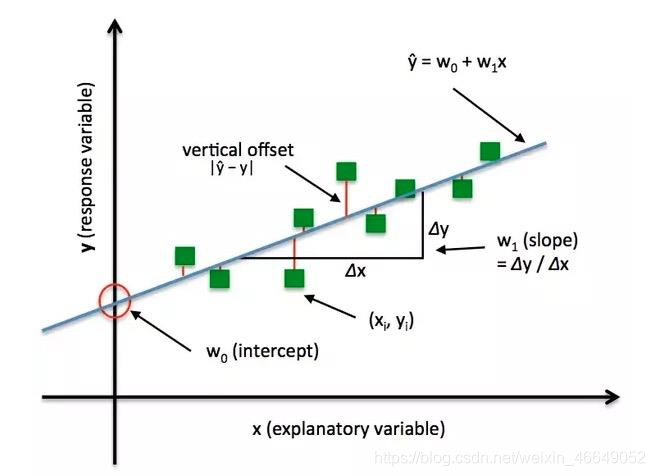
损失函数(Loss Function):
L o s s = ? ( ? ^ , ? ) Loss = ?(\hat? , ?)Loss=f(y^,y)
注:损失函数是计算一个样本。
代价函数(Cost Function):
C o s t = 1 N ∑ i n f ( y i ^ , y i ) Cost = \frac{1}{N}\sum_i^nf(\hat{y_i},y_i)Cost=N1i∑nf(yi^,yi)
注:针对样本集,然后求平均值。
目标函数(Objective Function):
O b j = C o s t + R e g u l a r i z a t i o n Obj= Cost + RegularizationObj=Cost+Regularization
注:代价函数并不是越小越好,越小容易导致模型过拟合;所以需要正则项来控制模型的复杂度。
2.十六种损失函数
nn.CrossEntropyLoss– 交叉熵损失函数nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction=‘mean’)功能:
nn.LogSoftmax ()与nn.NLLLoss ()结合,进行交叉熵计算nn.LogSoftmax ()用于将输出值归一化到0-1之间,然后通过nn.NLLLoss ()来计算交叉熵主要参数:
weight:各类别的loss设置权值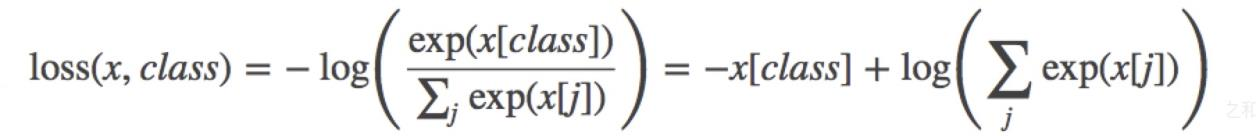
ignore _index:忽略某个类别reduction:计算模式,可为none/sum/mean
none- 逐个元素计算
sum- 所有元素求和,返回标量
mean- 加权平均,返回标量
交叉熵 = 信息熵 + 相对熵
H ( ? , ? ) = H ( ? ) + ? ? ? ( ? , ? ) H(?, ?) = H(?) + ?_{??}(?, ?)H(P,Q)=H(P)+DKL(P,Q)
交叉熵:
H ( ? , ? ) = − ∑ ? = ? ? ? ( ? ? ) ? ? ? ? ( ? i ) H(?, ?) = − \sum_{?=?}^? ?(?_?)????(?_i)H(P,Q)=−i=1∑NP(xi)logQ(xi)
P PP是真实的概率分布,Q QQ是模型输出的概率分布。由于H ( P ) H(P)H(P)是一个常数,所以在机器学习中,我们优化最小化交叉熵等价于优化相对熵。import torch import torch.nn as nn import torch.nn.functional as F import numpy as np # fake data inputs = torch.tensor([[1, 2], [1, 3], [1, 3]], dtype=torch.float) target = torch.tensor([0, 1, 1], dtype=torch.long) # def loss function loss_f_none = nn.CrossEntropyLoss(weight=None, reduction='none') loss_f_sum = nn.CrossEntropyLoss(weight=None, reduction='sum') loss_f_mean = nn.CrossEntropyLoss(weight=None, reduction='mean') # forward loss_none = loss_f_none(inputs, target) loss_sum = loss_f_sum(inputs, target) loss_mean = loss_f_mean(inputs, target) # view print("Cross Entropy Loss:\n ", loss_none, loss_sum, loss_mean)Cross Entropy Loss: tensor([1.3133, 0.1269, 0.1269]) tensor(1.5671) tensor(0.5224)使用
weight参数后:import torch import torch.nn as nn import torch.nn.functional as F import numpy as np # fake data inputs = torch.tensor([[1, 2], [1, 3], [1, 3]], dtype=torch.float) target = torch.tensor([0, 1, 1], dtype=torch.long) # def loss function weights = torch.tensor([1, 2], dtype=torch.float) # weights = torch.tensor([0.7, 0.3], dtype=torch.float) loss_f_none_w = nn.CrossEntropyLoss(weight=weights, reduction='none') loss_f_sum = nn.CrossEntropyLoss(weight=weights, reduction='sum') loss_f_mean = nn.CrossEntropyLoss(weight=weights, reduction='mean') # forward loss_none_w = loss_f_none_w(inputs, target) loss_sum = loss_f_sum(inputs, target) loss_mean = loss_f_mean(inputs, target) # view print("\nweights: ", weights) print(loss_none_w, loss_sum, loss_mean)# 基于带权重公式,第二个数据与第三个数据乘以2 weights: tensor([1., 2.]) tensor([1.3133, 0.2539, 0.2539]) tensor(1.8210) tensor(0.3642)nn.NLLLoss– 取反nn.NLLLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')功能:实现负对数似然函数中的负号功能
主要参数:weight:各类别的l o s s lossloss设置权值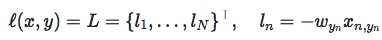
ignore_index:忽略某个类别reduction:计算模式,可为none/sum /mean
none-逐个元素计算
sum-所有元素求和,返回标量
mean-加权平均,返回标量
import torch import torch.nn as nn import torch.nn.functional as F import numpy as np # fake data inputs = torch.tensor([[1, 2], [1, 3], [1, 3]], dtype=torch.float) target = torch.tensor([0, 1, 1], dtype=torch.long) # 权重 weights = torch.tensor([1, 1], dtype=torch.float) loss_f_none_w = nn.NLLLoss(weight=weights, reduction='none') loss_f_sum = nn.NLLLoss(weight=weights, reduction='sum') loss_f_mean = nn.NLLLoss(weight=weights, reduction='mean') # forward loss_none_w = loss_f_none_w(inputs, target) loss_sum = loss_f_sum(inputs, target) loss_mean = loss_f_mean(inputs, target) # view print("\nweights: ", weights) print("NLL Loss", loss_none_w, loss_sum, loss_mean)NLL Loss tensor([-1., -3., -3.]) tensor(-7.) tensor(-2.3333)nn.BCELoss– 二分类交叉熵损失函数nn.BCELoss(weight=None, size_average=None, reduce=None, reduction='mean’)功能:计算二分类任务时的交叉熵(Cross Entropy)函数。在二分类中,label是{0,1}。对于进入交叉熵函数的input为概率分布的形式。一般来说,input为sigmoid激活层的输出,或者softmax的输出。
主要参数:weight:各类别的loss设置权值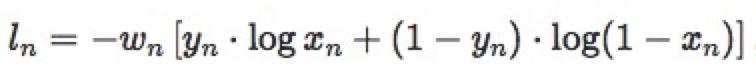
ignore_index:忽略某个类别reduction:计算模式,可为none/sum /mean
none-逐个元素计算
sum-所有元素求和,返回标量
mean-加权平均,返回标量
import torch import torch.nn as nn import torch.nn.functional as F import numpy as np inputs = torch.tensor([[1, 2], [2, 2], [3, 4], [4, 5]], dtype=torch.float) target = torch.tensor([[1, 0], [1, 0], [0, 1], [0, 1]], dtype=torch.float) target_bce = target # 数据尺度压缩到0-1之间 inputs = torch.sigmoid(inputs) weights = torch.tensor([1, 1], dtype=torch.float) loss_f_none_w = nn.BCELoss(weight=weights, reduction='none') loss_f_sum = nn.BCELoss(weight=weights, reduction='sum') loss_f_mean = nn.BCELoss(weight=weights, reduction='mean') # forward loss_none_w = loss_f_none_w(inputs, target_bce) loss_sum = loss_f_sum(inputs, target_bce) loss_mean = loss_f_mean(inputs, target_bce) # view print("\nweights: ", weights) print("BCE Loss", loss_none_w, loss_sum, loss_mean)weights: tensor([1., 1.]) BCE Loss tensor([[0.3133, 2.1269], [0.1269, 2.1269], [3.0486, 0.0181], [4.0181, 0.0067]]) tensor(11.7856) tensor(1.4732)nn.L1Loss– L1损失函数nn.L1Loss(size_average=None, reduce=None, reduction='mean')功能: 计算inputs与target之差的绝对值
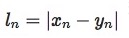
主要参数:reduction:计算模式,可为none/sum/mean
none- 逐个元素计算
sum- 所有元素求和,返回标量
mean- 加权平均,返回标量
import torch import random import torch.nn as nn import torch.nn.functional as F import matplotlib.pyplot as plt import numpy as np def set_seed(seed=1): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) set_seed(1) # 设置随机种子 inputs = torch.ones((2, 2)) target = torch.ones((2, 2)) * 3 loss_f = nn.L1Loss(reduction='none') loss = loss_f(inputs, target) print("input:{}\ntarget:{}\nL1 loss:{}".format(inputs, target, loss))input:tensor([[1., 1.], [1., 1.]]) target:tensor([[3., 3.], [3., 3.]]) L1 loss:tensor([[2., 2.], [2., 2.]])nn.MSELoss– MSE损失函数nn.MSELoss(size_average=None, reduce=None, reduction='mean')功能: 计算
inputs与target之差的平方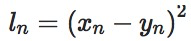
主要参数:reduction:计算模式,可为none/sum/mean
none- 逐个元素计算
sum- 所有元素求和,返回标量
mean- 加权平均,返回标量
import torch import random import torch.nn as nn import torch.nn.functional as F import matplotlib.pyplot as plt import numpy as np def set_seed(seed=1): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) set_seed(1) # 设置随机种子 inputs = torch.ones((2, 2)) target = torch.ones((2, 2)) * 3 loss_f_mse = nn.MSELoss(reduction='none') loss_mse = loss_f_mse(inputs, target) print("MSE loss:{}".format(loss_mse))MSE loss:tensor([[4., 4.], [4., 4.]])SmoothL1Loss– 平滑L1 (Smooth L1)损失函数nn.SmoothL1Loss(size_average=None, reduce=None, reduction='mean')功能:平滑的L1损失,相比于L1Loss,处处可导
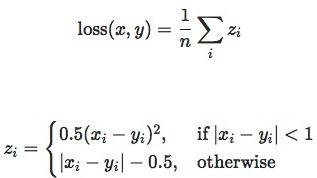
import torch import random import torch.nn as nn import torch.nn.functional as F import matplotlib.pyplot as plt import numpy as np def set_seed(seed=1): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) set_seed(1) # 设置随机种子 inputs = torch.linspace(-3, 3, steps=500) target = torch.zeros_like(inputs) loss_f = nn.SmoothL1Loss(reduction='none') loss_smooth = loss_f(inputs, target) loss_l1 = np.abs(inputs.numpy()) plt.plot(inputs.numpy(), loss_smooth.numpy(), label='Smooth L1 Loss') plt.plot(inputs.numpy(), loss_l1, label='L1 loss') plt.xlabel('x_i - y_i') plt.ylabel('loss value')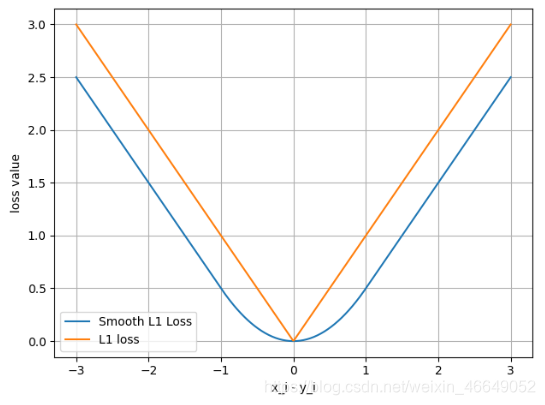
PoissonNLLLoss– 目标泊松分布的负对数似然损失nn.PoissonNLLLoss(log_input=True, full=False, size_average=None, eps=1e-08, reduce=None, reduction='mean')功能:泊松分布的负对数似然损失函数
主要参数:log_input:输入是否为对数形式,决定计算公式
log_input = True,
l o s s ( i n p u t , t a r g e t ) = e x p ( i n p u t ) − t a r g e t ∗ i n p u t loss(input, target) = exp(input) - target * inputloss(input,target)=exp(input)−target∗input
log_input = False,
l o s s ( i n p u t , t a r g e t ) = i n p u t − t a r g e t ∗ l o g ( i n p u t + e p s ) loss(input, target) = input - target * log(input+eps)loss(input,target)=input−target∗log(input+eps)full:计算所有loss,默认为Falseeps:修正项,避免log(input)为nan
import torch import random import torch.nn as nn import torch.nn.functional as F import matplotlib.pyplot as plt import numpy as np def set_seed(seed=1): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) set_seed(1) # 设置随机种子 inputs = torch.randn((2, 2)) target = torch.randn((2, 2)) loss_f = nn.PoissonNLLLoss(log_input=True, full=False, reduction='none') loss = loss_f(inputs, target) print("input:{}\ntarget:{}\nPoisson NLL loss:{}".format(inputs, target, loss))input:tensor([[0.6614, 0.2669], [0.0617, 0.6213]]) target:tensor([[-0.4519, -0.1661], [-1.5228, 0.3817]]) Poisson NLL loss:tensor([[2.2363, 1.3503], [1.1575, 1.6242]])KLDivLoss– KL散度nn.KLDivLoss(size_average=None, reduce=None, reduction='mean')功能:计算KLD(divergence),KL散度,相对熵
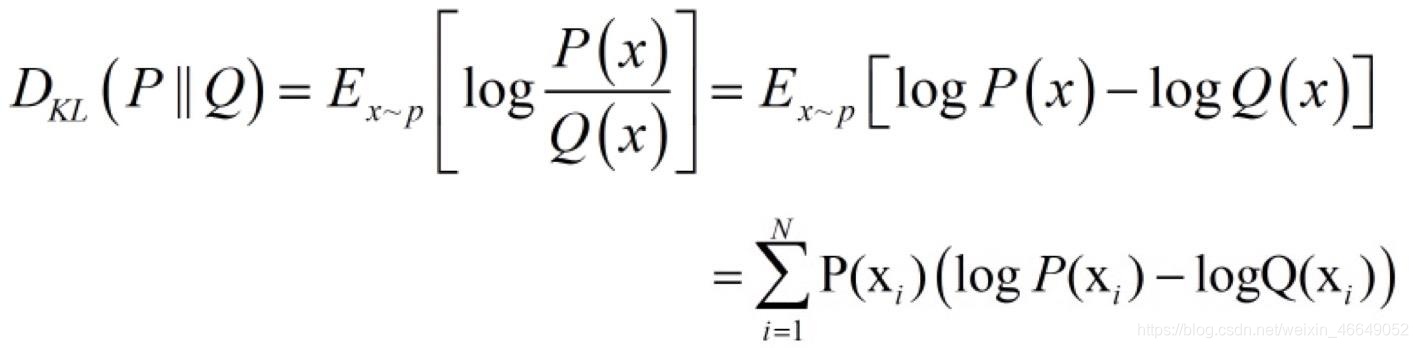
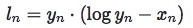
注意事项:需提前将输入计算
log-probabilities,如通过nn.logsoftmax()
主要参数:reduction:none/sum/mean/batchmean
batchmean- batchsize维度求平均值(除数不是元素个数而是batchsize的大小)
none- 逐个元素计算
sum- 所有元素求和,返回标量
mean- 加权平均,返回标量
import torch import random import torch.nn as nn import torch.nn.functional as F import matplotlib.pyplot as plt import numpy as np def set_seed(seed=1): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) set_seed(1) # 设置随机种子 inputs = torch.tensor([[0.5, 0.3, 0.2], [0.2, 0.3, 0.5]]) # pytorch函数计算公式不是原始定义公式,其对输入默认已经取log了,在损失函数计算中比公式定义少了一个log(input)的操作 # 因此公式定义里有一个log(y_i / x_i),在pytorch变为了 log(y_i) - x_i, inputs = F.log_softmax(inputs, 1) target = torch.tensor([[0.9, 0.05, 0.05], [0.1, 0.7, 0.2]], dtype=torch.float) loss_f_none = nn.KLDivLoss(reduction='none') loss_f_mean = nn.KLDivLoss(reduction='mean') loss_f_bs_mean = nn.KLDivLoss(reduction='batchmean') loss_none = loss_f_none(inputs, target) loss_mean = loss_f_mean(inputs, target) loss_bs_mean = loss_f_bs_mean(inputs, target) print("loss_none:\n{}\nloss_mean:\n{}\nloss_bs_mean:\n{}".format(loss_none, loss_mean, loss_bs_mean))loss_none: tensor([[ 0.7510, -0.0928, -0.0878], [-0.1063, 0.5482, -0.1339]]) loss_mean: 0.1464076191186905 loss_bs_mean: 0.43922287225723267MarginRankingLossnn.MarginRankingLoss(margin=0.0, size_average=None, reduce=None, reduction='mean')功能:计算两个向量之间的相似度,用于排序任务。该方法用于计算两组数据之间的差异。
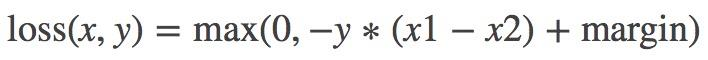
特别说明:该方法计算两组数据之间的差异,返回一个n ∗ n n*nn∗n的 loss 矩阵
主要参数:margin:边界值,x1与x2之间的差异值reduction:计算模式,可为none/sum/mean
y = 1时, 希望x1比x2大,当x1>x2时,不产生loss
y = -1时,希望x2比x1大,当x2>x1时,不产生loss
import torch import random import torch.nn as nn import torch.nn.functional as F import matplotlib.pyplot as plt import numpy as np def set_seed(seed=1): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) set_seed(1) # 设置随机种子 x1 = torch.tensor([[1], [2], [3]], dtype=torch.float) x2 = torch.tensor([[2], [2], [2]], dtype=torch.float) target = torch.tensor([1, 1, -1], dtype=torch.float) loss_f_none = nn.MarginRankingLoss(margin=0, reduction='none') loss = loss_f_none(x1, x2, target) print(loss)tensor([[1., 1., 0.], [0., 0., 0.], [0., 0., 1.]])MultiLabelMarginLoss– 多标签边界损失函数nn.MultiLabelMarginLoss(size_average=None, reduce=None, reduction='mean')功能:多标签边界损失函数(多标签分类与多分类是不同的,多标签分类指的是一个样本对应多个标签)
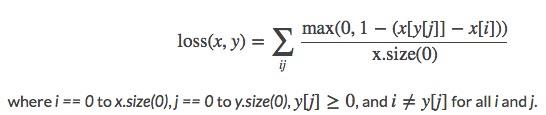
举例:四分类任务,样本x属于0类和3类,
标签:[0, 3, -1, -1] , 不是[1, 0, 0, 1]
主要参数:reduction:计算模式,可为none/sum/mean
import torch import random import torch.nn as nn import torch.nn.functional as F import matplotlib.pyplot as plt import numpy as np def set_seed(seed=1): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) set_seed(1) # 设置随机种子 x = torch.tensor([[0.1, 0.2, 0.4, 0.8]]) y = torch.tensor([[0, 3, -1, -1]], dtype=torch.long) loss_f = nn.MultiLabelMarginLoss(reduction='none') loss = loss_f(x, y) print(loss)tensor([0.8500])SoftMarginLoss– 二分类损失函数nn.SoftMarginLoss(size_average=None, reduce=None, reduction='mean')功能:计算二分类的
logistic损失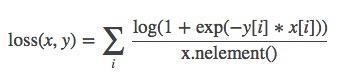
主要参数:
reduction:计算模式,可为none/sum/mean
import torch import random import torch.nn as nn import torch.nn.functional as F import matplotlib.pyplot as plt import numpy as np def set_seed(seed=1): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) set_seed(1) # 设置随机种子 inputs = torch.tensor([[0.3, 0.7], [0.5, 0.5]]) target = torch.tensor([[-1, 1], [1, -1]], dtype=torch.float) loss_f = nn.SoftMarginLoss(reduction='none') loss = loss_f(inputs, target) print("SoftMargin: ", loss)SoftMargin: tensor([[0.8544, 0.4032], [0.4741, 0.9741]])MultiMarginLoss– 多分类的折页损失nn.MultiMarginLoss(p=1, margin=1.0, weight=None, size_average=None, reduce=None, reduction='mean')功能:计算多分类的折页损失
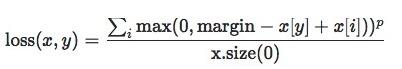
主要参数:
p:可选1或2weight:各类别的loss设置权值margin:边界值reduction:计算模式,可为none/sum/mean
import torch import random import torch.nn as nn import torch.nn.functional as F import matplotlib.pyplot as plt import numpy as np def set_seed(seed=1): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) set_seed(1) # 设置随机种子 x = torch.tensor([[0.1, 0.2, 0.7], [0.2, 0.5, 0.3]]) y = torch.tensor([1, 2], dtype=torch.long) loss_f = nn.MultiMarginLoss(reduction='none') loss = loss_f(x, y) print("Multi Margin Loss: ", loss)Multi Margin Loss: tensor([0.8000, 0.7000])TripletMarginLoss– 三元组损失nn.TripletMarginLoss(margin=1.0, p=2.0, eps=1e-06, swap=False, size_average=None, reduce=None, reduction='mean')功能:计算三元组损失,人脸验证中常用
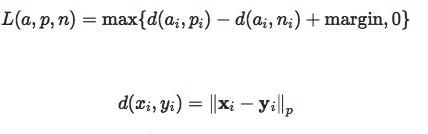
主要参数:p:范数的阶,默认为2margin:边界值reduction:计算模式,可为none/sum/mean
import torch import random import torch.nn as nn import torch.nn.functional as F import matplotlib.pyplot as plt import numpy as np def set_seed(seed=1): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) set_seed(1) # 设置随机种子 anchor = torch.tensor([[1.]]) pos = torch.tensor([[2.]]) neg = torch.tensor([[0.5]]) loss_f = nn.TripletMarginLoss(margin=1.0, p=1) loss = loss_f(anchor, pos, neg) print("Triplet Margin Loss", loss)Triplet Margin Loss tensor(1.5000)HingeEmbeddingLossnn.HingeEmbeddingLoss(margin=1.0, size_average=None, reduce=None, reduction='mean')功能:计算两个输入的相似性,常用于非线性embedding和半监督学习
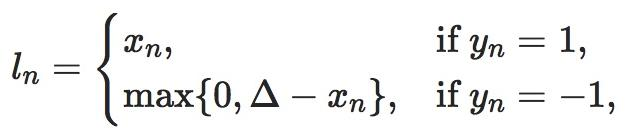
- ▲是margin=1.0
特别注意:输入x xx应为两个输入之差的绝对值,需要手动计算
主要参数:margin:边界值reduction:计算模式,可为none/sum/mean
import torch import random import torch.nn as nn import torch.nn.functional as F import matplotlib.pyplot as plt import numpy as np def set_seed(seed=1): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) set_seed(1) # 设置随机种子 inputs = torch.tensor([[1., 0.8, 0.5]]) target = torch.tensor([[1, 1, -1]]) loss_f = nn.HingeEmbeddingLoss(margin=1, reduction='none') loss = loss_f(inputs, target) print("Hinge Embedding Loss", loss)Hinge Embedding Loss tensor([[1.0000, 0.8000, 0.5000]])CosineEmbeddingLoss– 余弦相似度nn.CosineEmbeddingLoss(margin=0.0, size_average=None, reduce=None, reduction='mean')功能:采用余弦相似度计算两个输入的相似性
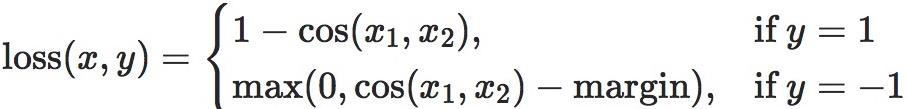
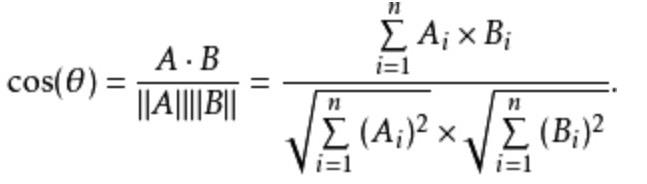
主要参数:
•margin:可取值[-1, 1] , 推荐为[0, 0.5]
•reduction:计算模式,可为none/sum/meanimport torch import random import torch.nn as nn import torch.nn.functional as F import matplotlib.pyplot as plt import numpy as np def set_seed(seed=1): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) set_seed(1) # 设置随机种子 x1 = torch.tensor([[0.3, 0.5, 0.7], [0.3, 0.5, 0.7]]) x2 = torch.tensor([[0.1, 0.3, 0.5], [0.1, 0.3, 0.5]]) target = torch.tensor([[1, -1]], dtype=torch.float) loss_f = nn.CosineEmbeddingLoss(margin=0., reduction='none') loss = loss_f(x1, x2, target) print("Cosine Embedding Loss", loss)Cosine Embedding Loss tensor([[0.0167, 0.9833]])CTCLoss– CTC损失函数torch.nn.CTCLoss(blank=0, reduction='mean', zero_infinity=False)功能: 计算CTC损失,解决时序类数据的分类
主要参数:blank:blank labelzero_infinity:无穷大的值或梯度置0 • reduction :计算模式,可为none/sum/mean
import torch import random import torch.nn as nn import torch.nn.functional as F import matplotlib.pyplot as plt import numpy as np def set_seed(seed=1): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) set_seed(1) # 设置随机种子 T = 50 # Input sequence length C = 20 # Number of classes (including blank) N = 16 # Batch size S = 30 # Target sequence length of longest target in batch S_min = 10 # Minimum target length, for demonstration purposes # Initialize random batch of input vectors, for *size = (T,N,C) inputs = torch.randn(T, N, C).log_softmax(2).detach().requires_grad_() # Initialize random batch of targets (0 = blank, 1:C = classes) target = torch.randint(low=1, high=C, size=(N, S), dtype=torch.long) input_lengths = torch.full(size=(N,), fill_value=T, dtype=torch.long) target_lengths = torch.randint(low=S_min, high=S, size=(N,), dtype=torch.long) ctc_loss = nn.CTCLoss() loss = ctc_loss(inputs, target, input_lengths, target_lengths) print("CTC loss: ", loss)CTC loss: tensor(7.5385, grad_fn=<MeanBackward0>)
七、优化器
1.什么是优化器?
pytorch的优化器:管理并更新模型中可学习参数的值,使得模型输出更接近真实标签。通俗一点,就是采样梯度更新模型的可学习参数,使得损失减小。
2.optimizer的基本属性
class Optimizer(object):
def __init__(self, params, defaults):
self.defaults = defaults
self.state = defaultdict(dict)
self.param_groups = []
...
param_groups = [{'params': param_groups}]
Optimizer有如下属性:
defaults:存储的是优化器的超参数,例子如下:{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}state:参数的缓存,如momentum的缓存params_groups:管理的参数组,是一个list,其中每个元素是一个字典,顺序是params,lr,momentum,dampening,weight_decay,nesterov,例子如下:[{'params': [tensor([[-0.1022, -1.6890],[-1.5116, -1.7846]], requires_grad=True)], 'lr': 1, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}]_step_count:记录更新次数,学习率调整中使用
3.optimizer的基本方法
class Optimizer(object):
def __init__(self, params, defaults):
self.defaults = defaults
self.state = defaultdict(dict)
self.param_groups = []
...
param_groups = [{'params': param_groups}]
def zero_grad(self):
for group in self.param_groups:
for p in group['params']:
if p.grad is not None:
p.grad.detach_()
# 清零
p.grad.zero_()
def add_param_group(self, param_group):
for group in self.param_groups:
param_set.update(set(group['params’]))
...
self.param_groups.append(param_group)
def state_dict(self):
...
return {
'state': packed_state,
'param_groups': param_groups, }
def load_state_dict(self, state_dict):
...
zero_grad():清空所管理参数的梯度
pytorch特性:张量梯度不自动清零,会将张量梯度累加;因此,需要在使用完梯度之后,或者在反向传播前,将梯度自动清零step():执行一步梯度更新,参数更新add_param_group():添加参数组,例如:可以为特征提取层与全连接层设置不同的学习率或者别的超参数state_dict():获取优化器当前状态信息字典
长时间的训练,会隔一段时间保存当前的状态信息,用来在断点的时候恢复训练,避免由于意外的原因导致模型的终止- load_state_dict() :加载状态参数字典,可以用来进行模型的断点续训练,继续上次的参数进行训练
4.优化器中的常用参数
4.1 learning rate 学习率
梯度下降:
? ? + ? = ? ? − ? ( ? ? ) ? ? + ? = ? ? − l r ∗ ? ( ? ? ) ?_{?+?} = ?_? − ?(?_? )\\?_{?+?} = ?_? − lr * ?(?_?)wi+1=wi−g(wi)wi+1=wi−lr∗g(wi)
学习率(learning rate)控制更新的步伐
import torch
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(1)
def func(x_t):
"""
y = (2x)^2 = 4*x^2 dy/dx = 8x
"""
return torch.pow(2*x_t, 2)
# init
x = torch.tensor([2.], requires_grad=True)
lr = 0.01
max_iteration = 20
for i in range(max_iteration):
y = func(x)
y.backward()
# x.detach().numpy():x中含有梯度信息,先去除梯度信息,再转化为numpy格式
print("Iter:{}, X:{:8}, X.grad:{:8}, loss:{:10}".format(
i, x.detach().numpy()[0], x.grad.detach().numpy()[0], y.item()))
x_rec.append(x.item())
# x -= x.grad 数学表达式意义: x = x - x.grad
x.data.sub_(lr * x.grad)
x.grad.zero_()
Iter:0, X: 2.0, X.grad: 16.0, loss: 16.0
Iter:1, X:1.840000033378601, X.grad:14.720000267028809, loss:13.542400360107422
Iter:2, X:1.6928000450134277, X.grad:13.542400360107422, loss:11.462287902832031
Iter:3, X:1.5573760271072388, X.grad:12.45900821685791, loss:9.701680183410645
Iter:4, X:1.432785987854004, X.grad:11.462287902832031, loss:8.211503028869629
Iter:5, X:1.3181631565093994, X.grad:10.545305252075195, loss:6.950216293334961
Iter:6, X:1.2127101421356201, X.grad:9.701681137084961, loss:5.882663726806641
Iter:7, X:1.1156933307647705, X.grad:8.925546646118164, loss:4.979086399078369
Iter:8, X:1.0264378786087036, X.grad:8.211503028869629, loss:4.214298725128174
Iter:9, X:0.9443228244781494, X.grad:7.554582595825195, loss:3.5669822692871094
Iter:10, X:0.8687769770622253, X.grad:6.950215816497803, loss:3.0190937519073486
Iter:11, X:0.7992748022079468, X.grad:6.394198417663574, loss:2.555360794067383
Iter:12, X:0.7353328466415405, X.grad:5.882662773132324, loss:2.1628575325012207
Iter:13, X:0.6765062212944031, X.grad:5.412049770355225, loss:1.8306427001953125
Iter:14, X:0.6223857402801514, X.grad:4.979085922241211, loss:1.549456000328064
Iter:15, X:0.5725948810577393, X.grad:4.580759048461914, loss:1.3114595413208008
Iter:16, X:0.526787281036377, X.grad:4.214298248291016, loss:1.110019326210022
Iter:17, X:0.4846442937850952, X.grad:3.8771543502807617, loss:0.9395203590393066
Iter:18, X:0.4458727538585663, X.grad:3.5669820308685303, loss:0.795210063457489
Iter:19, X:0.41020292043685913, X.grad:3.281623363494873, loss:0.673065721988678
4.2 momentum 动量
momentum 动量:结合当前梯度与上一次更新信息,用于当前更新。pytorch中更新公式为:
v i = m ∗ v i − 1 + g ( w i ) w i + 1 = w i − l r ∗ v i v_i=m*v_{i-1}+g(w_i)\\w_{i+1}=w_i-lr*v_ivi=m∗vi−1+g(wi)wi+1=wi−lr∗vi
v i v_ivi:更新量
m mm:momentum系数,通常设置为0.9
g ( w i ) g(w_i)g(wi):w i w_iwi的梯度
v i v_ivi有两部分组成,v i v_ivi直接依赖于v i − 1 v_{i-1}vi−1和g ( w i ) g(w_i)g(wi),而不仅仅是g ( w i ) g(w_i)g(wi)。
? ? ? ? = ? ∗ ? ? ? + ? ( ? ? ? ? ) = ? ( ? ? ? ? ) + ? ∗ ( ? ∗ ? ? ? + ? ( ? ? ? ) ) = ? ( ? ? ? ? ) + ? ∗ ? ( ? ? ? ) + ? ? ∗ ? ? ? = ? ( ? ? ? ? ) + ? ∗ ? ( ? ? ? ) + ? ? ∗ ? ( ? ? ? ) + ? ? ∗ ? 99 ?_{???} = ? ∗ ?_{??} + ?(?_{???}) \\= ?(?_{???}) + ? ∗ (? ∗ ?_{??} + ?(?_{??})) \\= ?(?_{???}) + ? ∗ ?(?_{??}) + ?^? ∗ ?_{??} \\= ?(?_{???}) + ? ∗ ?(?_{??}) + ?^? ∗ ?(?_{??}) + ?^? ∗ ?_{99}v100=m∗v99+g(w100)=g(w100)+m∗(m∗v98+g(w99))=g(w100)+m∗g(w99)+m2∗v98=g(w100)+m∗g(w99)+m2∗g(w98)+m3∗v99
可以看到越往前梯度信息的作用就越小。
import torch
import numpy as np
import torch.optim as optim
import matplotlib.pyplot as plt
torch.manual_seed(1)
def func(x):
return torch.pow(2*x, 2) # y = (2x)^2 = 4*x^2 dy/dx = 8x
iteration = 100
m = 0.63
lr_list = [0.01, 0.03]
momentum_list = list()
loss_rec = [[] for l in range(len(lr_list))]
iter_rec = list()
for i, lr in enumerate(lr_list):
x = torch.tensor([2.], requires_grad=True)
momentum = 0. if lr == 0.03 else m
momentum_list.append(momentum)
optimizer = optim.SGD([x], lr=lr, momentum=momentum)
for iter in range(iteration):
y = func(x)
y.backward()
optimizer.step()
optimizer.zero_grad()
loss_rec[i].append(y.item())
for i, loss_r in enumerate(loss_rec):
plt.plot(range(len(loss_r)), loss_r, label="LR: {} M:{}".format(lr_list[i], momentum_list[i]))
plt.legend()
plt.xlabel('Iterations')
plt.ylabel('Loss value')
plt.show()

5.Pytorch十种优化器简介
optim.SGD:随机梯度下降法optim.SGD(params, lr=<object object>, momentum=0, dampening=0, weight_decay=0, nesterov=False)主要参数:
params:管理的参数组lr:初始学习率momentum:动量系数weight_decay:L2正则化系数nesterov:是否采用NAG
optim.Adagrad:自适应学习率梯度下降法optim.RMSprop: Adagrad的改进optim.Adadelta: Adagrad的改进optim.Adam:RMSprop结合Momentumoptim.Adamax:Adam增加学习率上限optim.SparseAdam:稀疏版的Adamoptim.ASGD:随机平均梯度下降optim.Rprop:弹性反向传播optim.LBFGS:BFGS的改进
上述优化器的使用可参考:torch.optim
SGD与Adam是两种最常用的方式。PyTorch官方文档介绍的非常详细!
注:
optimizer在一个神经网络的epoch中需要实现下面两个步骤:梯度置零和梯度更新。optimizer = torch.optim.SGD(net.parameters(), lr=1e-5) for epoch in range(EPOCH): ... optimizer.zero_grad() #梯度置零 loss = ... #计算loss loss.backward() #BP反向传播 optimizer.step() #梯度更新给网络不同的层赋予不同的优化器参数。
from torch import optim from torchvision.models import resnet18 net = resnet18() optimizer = optim.SGD([ {'params':net.fc.parameters()},#fc的lr使用默认的1e-5 {'params':net.layer4[0].conv1.parameters(),'lr':1e-2}],lr=1e-5)
八、训练与评估
首先应该设置模型的状态:如果是训练状态,那么模型的参数应该支持反向传播的修改;如果是验证/测试状态,则不应该修改模型参数。在PyTorch中,模型的状态设置非常简便,如下的两个操作二选一即可:
model.train() # 训练状态
model.eval() # 验证/测试状态
我们前面在DataLoader构建完成后介绍了如何从中读取数据,在训练过程中使用类似的操作即可,区别在于此时要用for循环读取DataLoader中的全部数据。
for data, label in train_loader:
之后将数据放到GPU上用于后续计算,此处以.cuda()为例
data, label = data.cuda(), label.cuda()
开始用当前批次数据做训练时,应当先将优化器的梯度置零:
optimizer.zero_grad()
之后将data送入模型中训练:
output = model(data)
根据预先定义的criterion计算损失函数:
loss = criterion(output, label)
将loss反向传播回网络:
loss.backward()
使用优化器更新模型参数:
optimizer.step()
这样一个训练过程就完成了。
验证/测试的流程基本与训练过程一致,不同点在于:
需要预先设置
torch.no_grad,以及将model调至eval模式不需要将优化器的梯度置零
不需要将loss反向回传到网络
不需要更新optimizer
一个完整的图像分类的训练过程如下所示:
def train(epoch):
model.train()
train_loss = 0
for data, label in train_loader:
data, label = data.cuda(), label.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(label, output)
loss.backward()
optimizer.step()
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
对应的,一个完整图像分类的验证过程如下所示:
def val(epoch):
model.eval()
val_loss = 0
with torch.no_grad():
for data, label in val_loader:
data, label = data.cuda(), label.cuda()
output = model(data)
preds = torch.argmax(output, 1)
loss = criterion(output, label)
val_loss += loss.item()*data.size(0)
running_accu += torch.sum(preds == label.data)
val_loss = val_loss/len(val_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, val_loss))
参考: