1. SQL语句在mysql的执行过程
一条更新语句完整流程图如下所示: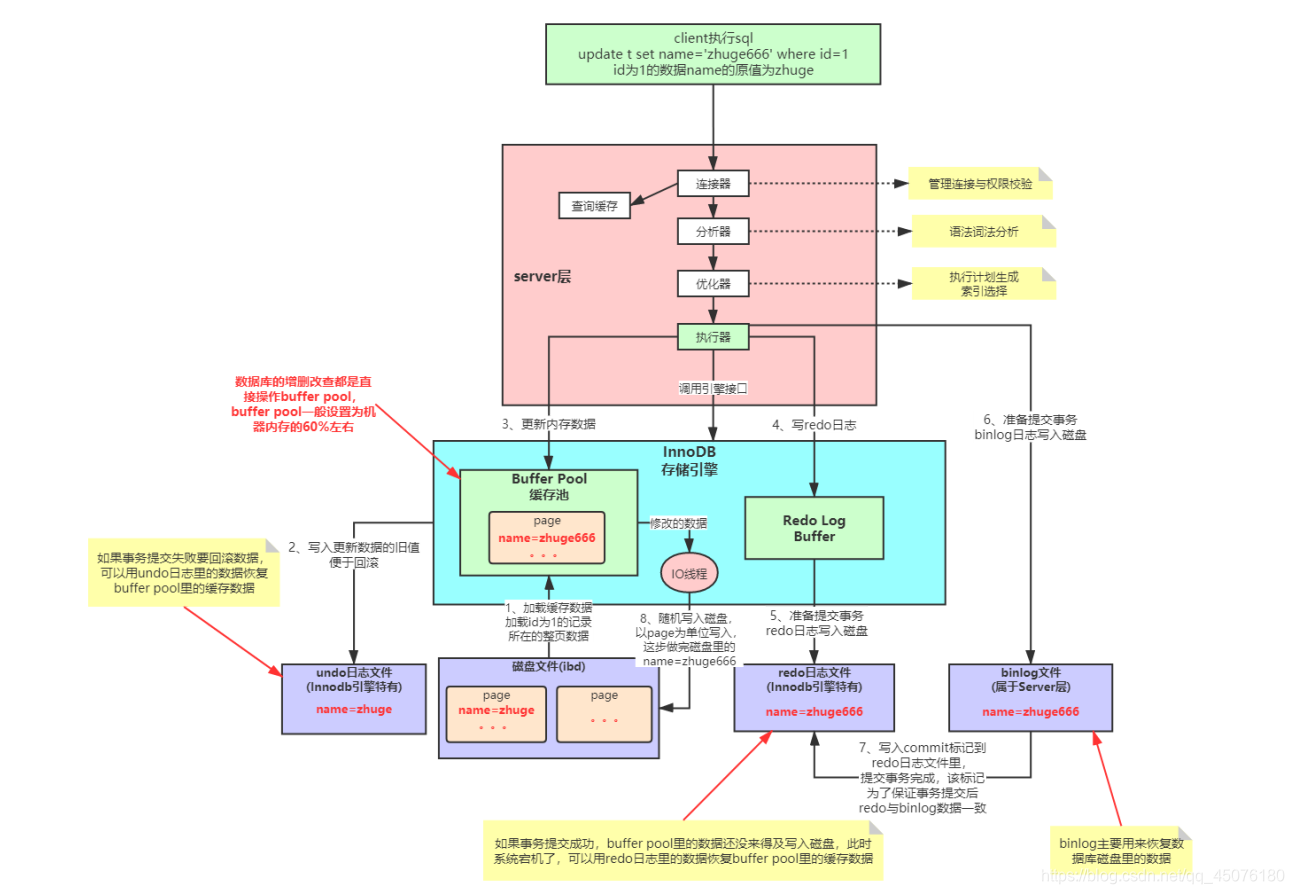
步骤:
一:客户端层
id为1的name字段原来的值是zhuge。
- ①:mysql的客户端执行sql
update t set name = 'zhuge666' where id = 1;
二:mysql服务器层
- ②: 进入mysql服务器,由
连接器验证账号密码等身份信息,验证通过去查mysql缓存,如果有,直接返回。没有进入分析器。 - ③:进入mysql的
分析器,分析sql语句是否符合mysql规范。 - ④:进入sql
优化器,mysql底层优化sql,比如调换索引列等。 - ⑤:进入
执行器,执行sql。
三:innoDB引擎层
mysql服务层后边连接了很多引擎层,如MyIsam、innoDB等,这里只分析innoDB引擎。
以一个update语句为例,看一下inndb是如何执行,并实现底层事务的!
- ⑥:加载磁盘上id为
1的整页数据到buff pool缓存池中,此时buff pool中的name值为zhuge,为什么加载整页,因为磁盘上存储数据都是整页整页存的。这里要注意:mysql加载数据是整页整页加载的!! - ⑦:把
buff pool中的 旧值zhuge写入undo日志版本链,方便事务提交失败后回滚,回滚时直接从undo日志版本链中取值即可。 - ⑧:在
buff pool中把新的值zhuge666赋给name,注意此时只有buff pool中的name属性做了更新,磁盘上的文件还是原来的旧值zhuge。 - ⑨:执行器把更新的操作先写入
内存中的Redo Log buffer(Redo日志缓冲区) - ⑩:把
Redo日志缓冲区分批次顺序写入inndb独有的redo磁盘日志文件中,此时准备提交事务 - ⑪:把更新操作写入
binlog日志,内容与redo日志差不多,属于mysql服务层,所有引擎层都有这一步操作。此时还是准备提交事务中,还没提交 。 - ⑫:写一个
commit标记到redo日志中去,该标记为了保证事务提交后,redo日志和binlog日志数据一致。此时才标志着提交事务完成
问题一:binlog为什么要给redo日志中写一个commit标记?
binlog主要用于恢复数据,提交事务时,要给redo日志中写一个commit标记可以保证binlog日志中的数据与redo日志中的数据保持一致性
问题二:磁盘文件的数据什么时候更新?
不确定,有一个后台io线程从Buffer pool缓存池中随机以页为单位写入磁盘。
问题三:如果事务提交后,数据库服务挂了,此时buff pool的数据还没来得及更新到磁盘上,怎么办?
当再次重启服务器时,可以使用redo日志里的数据恢复buff pool中的数据,后台线程再把数据从buff pool中写入磁盘,这也是redo日志的最主要作用
问题四:为什么Mysql不能直接更新磁盘上的数据,而是设置这么一套复杂的机制来执行SQL?
- ①:内存操作,异步刷盘:如果每个请求都要来更新磁盘,数据库性能将特别差。利用
buff poll缓存池在内存中操作数据,定时写入磁盘,大大提高了数据库性能。 - ②:redo日志顺序写入磁盘:
redo日志虽然也使用磁盘存储,但相对与直接随机读写磁盘来说,redo日志是顺序写磁盘日志文件的。顺序写入的速度远高于随机写入,同时redo日志还能保证各种异常情况下的数据一致性。
正是通过这套机制,才能让我们的MySQL数据库在较高配置的机器上每秒可以抗下几干的读写请求。
2. undo日志、redo日志、binlog日志的区别?
三种日志都写入磁盘!不过undo日志和redo日志是innoDB存储特有的,binlog日志是所有存储引擎都有的!
undo日志:主要用于mvcc机制的实现,还有事务回滚也可直接从undo日志中取到原始值redo日志:主要用于防止mysql宕机时,buff pool中的数据还未来得及写入磁盘,导致数据丢失。使用redo日志可在mysql宕机后再启动时,把数据恢复到buff pool中。第二点就是等待binlog日志发送commit标记后才提交事务,保证与binlog日志文件数据一致!binlog日志:主要用于数据库数据误删恢复,主从复制
版权声明:本文为qq_45076180原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。