文章目录
0 笔记说明
来源于【机器学习】【白板推导系列】【合集 1~23】,我在学习时会跟着up主一起在纸上推导,博客内容为对笔记的二次书面整理,根据自身学习需要,我可能会增加必要内容。
注意:本笔记主要是为了方便自己日后复习学习,而且确实是本人亲手一个字一个公式手打,如果遇到复杂公式,由于未学习LaTeX,我会上传手写图片代替(手机相机可能会拍的不太清楚,但是我会尽可能使内容完整可见),因此我将博客标记为【原创】,若您觉得不妥可以私信我,我会根据您的回复判断是否将博客设置为仅自己可见或其他,谢谢!
本博客为(系列三)的笔记,对应的视频是:【(系列三) 线性回归1-最小二乘法及其几何意义】、【(系列三) 线性回归2-最小二乘法-概率视角-高斯噪声-MLE】、【(系列三) 线性回归3-正则化-岭回归-频率角度】、【(系列三) 线性回归4-正则化-岭回归-贝叶斯角度】。
下面开始即为正文。
1 最小二乘法求线性回归模型
D = {(x1, y1), (x2, y2),…,(xN, yN)},xi为p维向量,即xi∈Rp,yi是一维实数,即yi∈R,i=1,2…N。令矩阵X = (x1,x2,…,xN)T,则X为N×p阶矩阵;Y = (y1,y2,…,yN)T,则Y为N×1阶矩阵。
设线性回归的函数为f(w)=wTx,其中w = (w1,w2,…,wp)T。f(w)的平方损失函数(最小二乘法)为: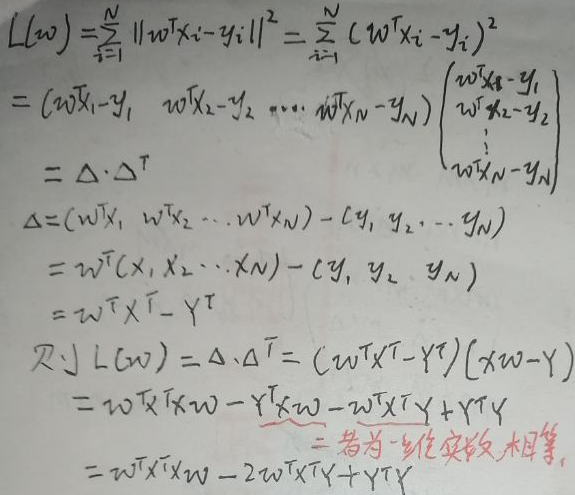
在进行下一步之前给出求导公式: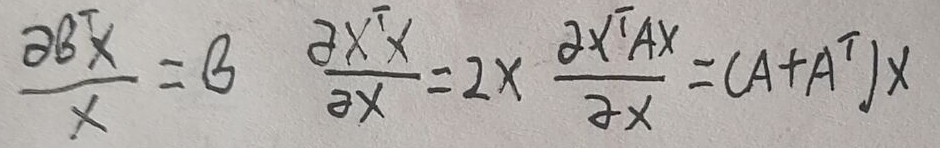
继续推: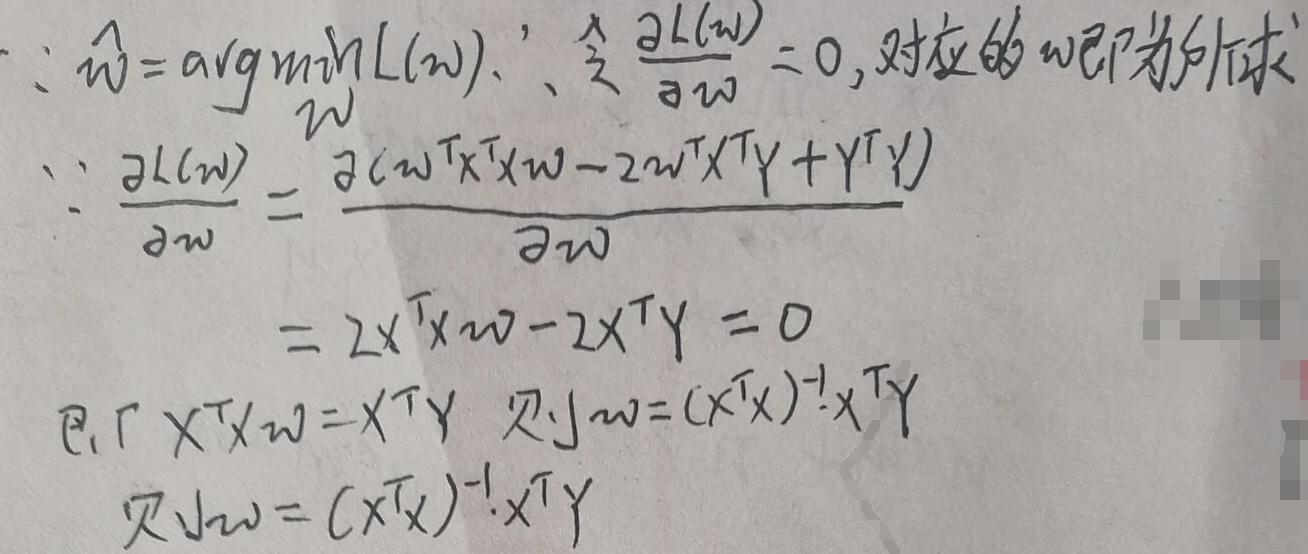
则w的最大似然估计就是上图中的最后一行。
2 几何意义
2.1 平方损失函数的几何意义
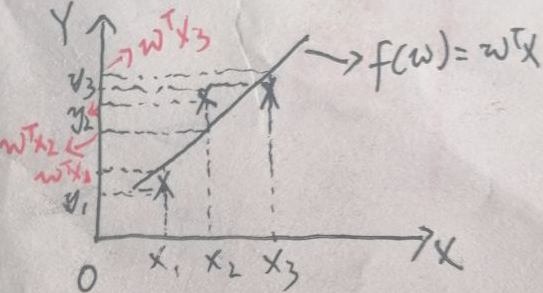
上图中,横纵坐标分别为X与Y,直线为f(w)=wTx。为了方便画图和解释,假设数据集有三个点,即D = {(x1, y1), (x2, y2),(x3, y3)}。将x1,x2,x3代入f(w)=wTx,得到线性回归模型的三个结果:wTx1,wTx2,wTx3。
则平方损失函数的几何意义就是所有【实际值与模型预测值差值】的平方和。
2.2 用几何意义求线性回归模型
现在换一种方式,将线性回归的函数设为f(β)=xTβ,视xT为函数的系数。为了方便画图和解释,假设p=2,即xi为2维向量,即xi∈R2,i=1,2…N,则第i个样本的xi=(xi1,xi2),Y=(y1,y2,…yN),数据集D = {(x1, y1), (x2, y2),…,(xN, yN)}。规定N>>p=2(其实样本数N本来就远远大于样本维度p,只是这里设p=2罢了),于是所有数据xi形成了二维子空间(应该是p维子空间,只是这里p=2罢了)。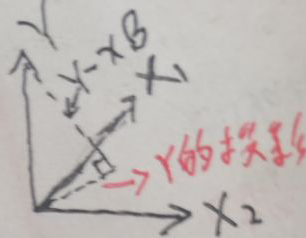
如上图,Y一般不在所有数据xi形成的二维子空间中(如果在的话,线性回归的函数线就是一条直线了,这条线还可以拟合所有数据,但是绝大部分情况下不是这样的;而且应该是p维子空间,只是这里p=2罢了),所以要计算的就是向量Y到所有数据xi形成的二维子空间中的投影(因为Y在子空间上的投影离向量Y距离最短)。
Y的投影既然在所有数据xi形成的二维子空间上,则Y的投影一定可以由xi的线性组合表示,设Y的投影为xβ(我这里有疑问,为什么不是xTβ,我没搞清楚),则二维空间的法向量为Y-xβ。而x属于这个二维空间的随机变量,则有【Y-xβ⊥x】,根据向量的垂直与点积运算得到: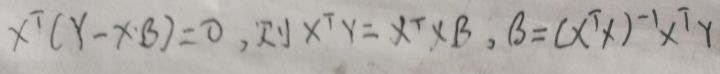
注意到没有,在【1 最小二乘法求线性回归模型】一节求得的w与上图的β一模一样?!为什么?
因为两个模型分别为f(w)=wTx,f(β)=xTβ,其实两者算出的值均为一维实数,而且(xTβ)T=βTx=wTx,这样的话w与β一模一样就很正常了。
3 从概率视角看最小二乘法
下面从概率视角来讨论最小二乘法。
样本用x表示,是一个随机变量,y为样本的标签值,所有样本之间独立同分布。设噪声数据为ε,且ε~N(0,σ2),y=f(w)+ε=wTx+ε,则有【y|x;w~N(wTx,σ2)】。根据此文【机器学习-白板推导-系列(二)笔记:高斯分布与概率】中【3 高斯分布的概率密度函数】一节的第二个图片可得y|x;w的概率密度函数如下: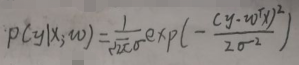
现在求wMLE。设似然函数L(w)为: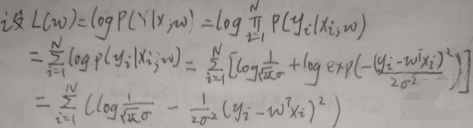
则wMLE为: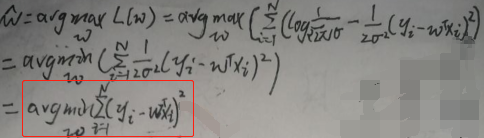
仔细看,上图框住的不就是平方损失函数的表达式吗?!
再看本节给出的条件——设噪声数据为ε,且ε~N(0,σ2),也就是说【线性模型参数的最小二乘估计LSE】等价于【线性模型参数的极大似然估计MLE,同时噪声ε~N(0,σ2)】。
4 正则化方法:岭回归
正则化是解决模型过拟合问题的方法之一。根据【1 最小二乘法求线性回归模型】一节,线性回归模型的平方损失函数为: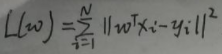
通过MLE求得的w为: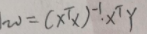
现在给损失函数L(w)加一个正则化项λp(w),令目标函数J(w)=L(w)+λp(w),其中λ为超参数(超参数是在开始学习过程之前设置的参数,其他参数的值通过训练得出),p(w)称为罚项penalty。有两种p(w):
(1)L1范数正则项,LASSO,Least Absoulute Shrinkage and Selection Operator,最小绝对收缩选择算子。p(w)=||w||1,这是关于参数w的1范数;
(2)L2范数正则项,Ridge Regression,岭回归。p(w)=||w||22=wTw,这是关于参数w的2范数。
下面仅讨论岭回归。
4.1 频率角度
将平方损失函数与L2范数正则项p(w)=wTw代入J(w)得: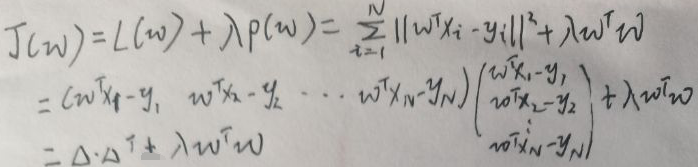
上图的Δ与【1 最小二乘法求线性回归模型】一节第一张图片的Δ相同,所以Δ·ΔT相同,所以直接代入得: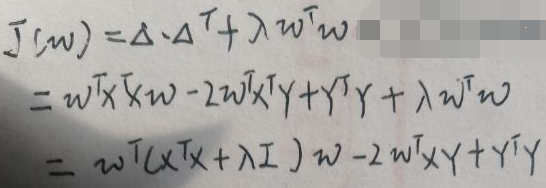
继续通过MLE求w: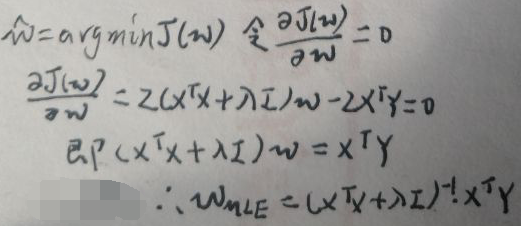
则w的最大似然估计就是上图中的最后一行。
4.2 贝叶斯角度
现在设噪声数据为ε,且ε~N(0,σ2),y=f(w)+ε=wTx+ε,则有【y|x;w~N(wTx,σ2)】。假设参数w~N(0,σ02),根据贝叶斯公式:
由于【y|x;w~N(wTx,σ2)】与【w~N(0,σ02)】,所以y|x;w与w的概率密度函数为: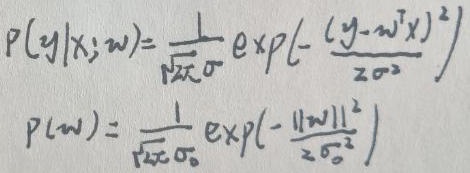
则wMAP为: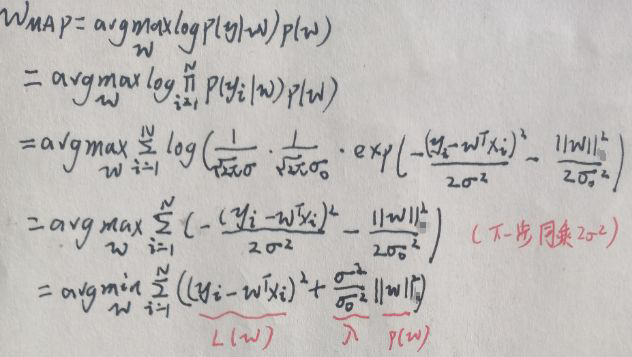
与目标函数J(w)=L(w)+λp(w)相比,对应的表达式已在上图最后一行标出。
再看本节给出的条件——同样是设噪声数据为ε,且ε~N(0,σ2),也就是说【线性模型中加正则项的平方损失函数】等价于【线性模型参数的最大后验概率估计(MAP估计),同时噪声ε~N(0,σ2)】。
5 总结
1、【线性模型参数的最小二乘估计LSE】等价于【线性模型参数的极大似然估计MLE,同时噪声ε~N(0,σ2)】。
2、【线性模型中加正则项的平方损失函数】等价于【线性模型参数的最大后验概率估计(MAP估计),同时噪声ε~N(0,σ2)】。
END