目录
定义
DOM -----Document Object Model
文档对象模型(DOM)是一个能够让程序和脚本动态访问和更新文档内容、结构和样式的语言平台, 提供了标准的 HTML 和 XML 对象集, 并有一个标准的接口来访问并操。
一些重要的概念(主要DOM树)
1、DOM树模型:
DOM解析将按照标签的层次体现出标签的所属,形成一个树状结构---DOM树。
标签、属性和文本内容称为节点(node),节点也称为对象,标签通常也称为页面中的元素(element)
(1)DOM技术的核心内容:
把标记文档变成对象树,通过对树中的对象进行操作,实现对文档内容的操纵。
(2)DOM解析的方式:
将标记文档解析成一棵DOM对象树,并将树中的内容都封装成对象。----这些动作由浏览器帮我们完成
(3)DOM解析的好处:
可以对树中的节点进行任意的操作:增删改查
(4)DOM解析的弊端:
这种解析需要将整个标记型文档加载进内存,因此,如果标记型文档很,耗内存。
2、DHTML:
动态的HTML,它不是一门语言,是多项技术综合体的简称。
以HTML+CSS的方式做的是静态网页,要想变成动态的,必须在此基础上加入JS和DOM技术。因此,DHTML包含:HTML+CSS+JS+DOM
3、HTML:
提供标签,封装数据
4、CSS:
提供样式属性,对数据的显示样式进行定义
5、DOM:
把标记型文档封装成对象,供JS操纵
6、JS:
提供程序设计语言,通过DOM来操纵文档内容和显示样式
DOM 节点
文档中的所有内容都可表示为一个节点(node),如:HTML 里整个文档、每个标签、每个标签的属性和文本都可作为一个节点。
节点树
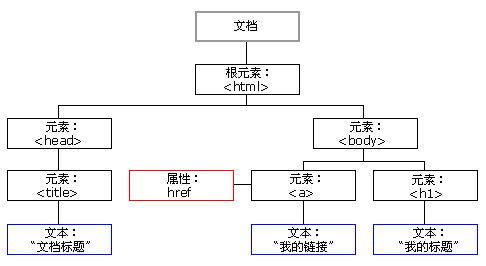
1.节点分类
(1)文档节点(Document):整个 XML、HTML 文档
(2) 元素节点(Element):每个 XML、HTML 元素
(3) 属性节点(Attr):每个 XML、HTML 元素的属性
(4) 文本节点(Text):每个 XML、HTML 元素内的文本
(5) 注释节点(Comment):每个注释
注:
节点包含标签,标签不包含节点。
要操作DOM模型下的内容,首先需要获取DOM中的节点。
2.节点层次
文档中所有节点相互之间都有关系,包括父子关系,同胞关系。
- parseNode:指向文档树中的父节点
- nextSibling:紧挨着当前节点的下一个节点
- firstChild:表现某一节点的第一个节点,childNodes[0]
- lastChild:表示某一节点的最后一个子节点,childeNodes[childNodes.length-1]
3.节点属性
3.1 nodeName 属性: 节点的名称,是只读的。
(1) 元素节点的 nodeName 与标签名相同
(2) 属性节点的 nodeName 是属性的名称
(3) 文本节点的 nodeName 永远是 #text
(4) 文档节点的 nodeName 永远是 #document
console.log( document.nodeName ); // => #document:文档节点 console.log( document.body.nodeName ); // => BODY:元素节点 console.log( document.getElementById('div').nodeName ); // => DIV:元素节点 console.log( document.getElementById('div').attributes.style.nodeName ); // => style:属性节点
3.2 nodeValue 属性:节点的值
(1)元素节点的 nodeValue 是 undefined 或 null
(2)文本节点的 nodeValue 是文本自身
(3)属性节点的 nodeValue 是属性的值
<div style="width:200px;height:100px;border:1px solid black" id="div"> <span>文本1</span> 文本2 </div> console.log( document.nodeValue ); // => null:文档节点 console.log( document.body.nodeValue ); // => null:元素节点 console.log( document.getElementById('div').nodeValue ); // => null:元素节点 console.log( document.getElementById('div').attributes.style.nodeValue ); // => width:200px;height:100px;border:1px solid black;:style属性的值 document.getElementById('div').attributes.style.nodeValue = ' width:200px;height:200px'; // 设置style属性的值
3.3 nodeType 属性: 节点的类型,是只读的。
以下常用的几种结点类型:
元素类型 节点类型
元素 1
属性 2
文本 3
注释 8
文档 9
console.log( document.nodeType ); // => 9:文档节点 console.log( document.body.nodeType ); // => 1:元素节点 console.log( document.getElementById('div').nodeType ); // => 1:元素节点 console.log( document.getElementById('div').attributes.style.nodeType ); // => 2:属性节点
4.节点的操作
4.1创建节点
document.createElement('tagName')
- document.createElement() 方法创建由 tagName 指定的 HTML 元素。因为这些元素原先不存在,是根据我们的需求动态生成的,所以我们也称为动态创建元素节点。
4.2 添加节点
node.appendChild(child)
- node.appendChild() 方法将一个节点添加到指定父节点的子节点列表末尾。类似于 CSS 里面的after 伪元素。
node.insertBefore(child, 指定元素)
- node.insertBefore() 方法将一个节点添加到父节点的指定子节点前面。类似于 CSS 里面的 before 伪元素。
4.3 删除节点
从子节点列表中删除某个节点。
结构:
nodeObject.removeChild(node)返回值:返回被删除的节点,如失败,则返回 NULL。
4.4 替换节点
结构 :
父元素.replaceChild(newChild, oldChild)
参数:
- newChild:必须。你要插入的节点对象。
- oldChild:必须。你要移除的节点对象。
var replaceChild = document.body.replaceChild(div1,div2);//将div1替换div2
4.5 复制节点
node.cloneNode()
node.cloneNode() 方法返回调用该方法的节点的一个副本。 也称为克隆节点/拷贝节点
注意:
1. 如果括号参数为空或者为 false ,则是浅拷贝,即只克隆复制节点本身,不克隆里面的子节点。
2. 如果括号参数为 true ,则是深度拷贝,会复制节点本身以及里面所有的子节点。
4.6 修改文本节点
方法 作用 appendData(data); 将data加到文本节点后面 deleteData(start,length); 将从start处删除length个字符 insertData(start,data); 在start处插入字符,start的开始值是0; replaceData(start,length,data); 在start处用data替换length个字符 splitData(offset); 在offset处分割文本节点 substringData(start,length); 从start处提取length个字符
4.7查找节点
parentObj.firstChild;//如果节点为已知节点的第一个子节点就可以使用这个方法。此方法可以递归进行使用
parentObj.firstChild.firstChild.....parentObj.lastChild; //获得一个节点的最后一个节点,与firstChild一样也可以进行递归使用
parentObj.lastChild.lastChild.....parentObj.childNodes; //获得节点的所有子节点,然后通过循环和索引找到目标节点
常用方法
方法 功能 兼容性 document.getElementById() 通过id得到元素 IE6 document.getElementsByTagName() 通过标签名得到元素数组 IE6 document.getElementsByClassName() 通过类名得到元素数组 IE9 document.queryselector() 通过选择器得到元素
IE8部分兼容、IE9完全兼容 document.querySelectorAll() 通过选择器得到元素数组 IE8部分兼容、IE9完全兼容
1.getElementById
getElementById() 方法返回带有指定 ID 的元素:
var element=document.getElementById("intro");
2.getElementByTagName
document.getElementByTagName(‘标签名’)通过指定的上下文获取指定的标签,获取的是一个元素集合,如果没有获取到元素,那就是空元素集合 (通过数组方法取元素)
3.getElementClassName
document.getElementClassName(‘类名’)在整个文档中,通过标签的NAME属性值获取一组节点集合(在IE中只有表单元素的NAME才能识别,所以我们一般应用于表单元素的处理)
4.querySelector
document.getElementClassName(‘类名’)在指定上下文中通过选择器获取第一个元素(只能获取一个),获取不到就是null
5. querySelectorAll
document.querySelectorAll(‘选择器’)在指定上下文中通过选择器获取一组元素集合,获取不到就是空元(通过数组方法取元素)