环境要求:
- 虚拟机上hadoop集群hdfs开启
- 虚拟机配置hive,且hive配置metastore到mysql
- windows中配置hadoop环境,且IDEA中sparksql内部可运行
- 虚拟机防火墙关闭
网上很多帖子的操作步骤过于繁琐,现总结如下:
1.向pom.xml中导入依赖(mysql驱动、hive依赖,spark-on-hive依赖)
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>2.将虚拟机hive/conf目录下hive-site.xml 文件拷贝到项目的 resources 目录中,(需根据自己的mysql情况调整url、用户名和密码)
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
</configuration>

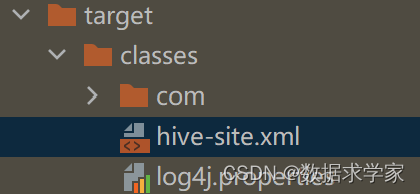
3.idea项目target/classes目录中hive-site.xml是否已自动复制,若无,需要放置其中,否则spark只能本地运行
4.开启Hive支持,在创建SparkSession时,添加enableHiveSupport()即可
//创建 SparkSession
val spark: SparkSession = SparkSession
.builder()
.enableHiveSupport()
.master("local[*]")
.appName("sql")
.getOrCreate()版权声明:本文为weixin_36040866原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。