为什么要使用并发编程?并发编程适用于什么场景?创建多少个线程合适?
我们都知道并发编程能够提高CPU利用率,提高程序执行效率,简言之,很“快”。但是:
- 并发编程在所有场景下都是快的吗?
- 知道它很快,何为快?怎样度量?
看似再问第一句,实则在问第二句。因此并发线程适用场景就是:通过设置正确个数的线程来最⼤化程序的运⾏
速度,就是说能够充分利用CPU和I/O的利用率。下面具体谈谈:
这里提出两个场景:
- CPU密集型程序
- I/O密集型程序
CPU 密集型程序
⼀个完整请求,I/O操作可以在很短时间内完成, CPU还有很多运算要处理,也就是说 CPU 计算的⽐例占很⼤⼀部分
假如我们要计算 1+2+…100亿 的总和,很明显,这就是⼀个 CPU 密集型程序在【单核】CPU下,如果我们创建 4 个线程来分段计算,即:
- 线程1计算 [1,25亿)
- … 以此类推
- 线程4计算 [75亿,100亿]
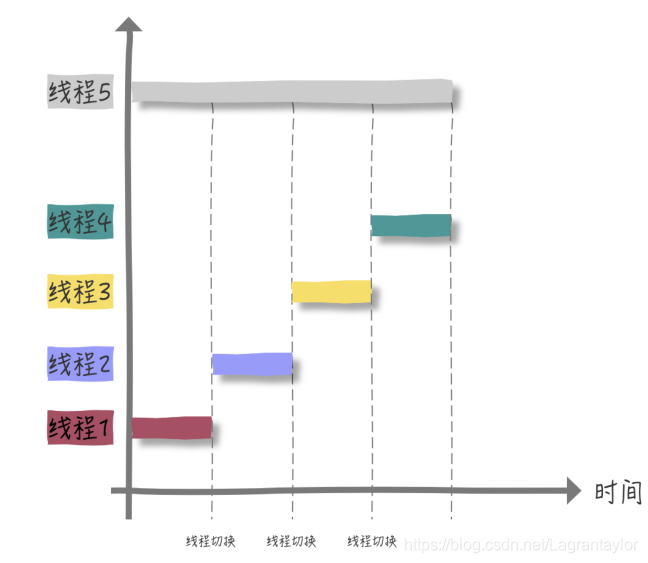
由于是单核 CPU,所有线程都在等待 CPU 时间⽚。按照理想情况来看,四个线程执⾏的时间总和与⼀个线程5独⾃完成是相等的,实际上还忽略了四个线程上下⽂切换的开销
当然,如果是四核CPU下,
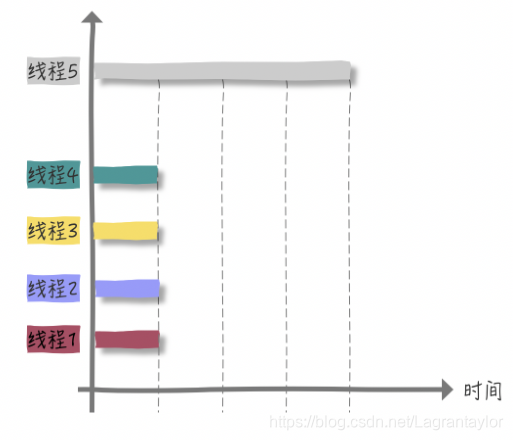
每个线程都有 CPU 来运⾏,并不会发⽣等待 CPU 时间⽚的情况,也没有线程切换的开销。理论情况来看效率提升了 4 倍。
所以,如果是多核CPU 处理 CPU 密集型程序,我们完全可以最⼤化的利⽤ CPU核⼼数,应⽤并发编程来提⾼效率。
I/O密集型程序
与 CPU 密集型程序相对,⼀个完整请求,CPU运算操作完成之后还有很多 I/O
操作要做,也就是说 I/O 操作占⽐很⼤部分
我们都知道在进⾏ I/O 操作时,CPU是空闲状态,所以我们要最⼤化的利⽤ CPU,不能让其是空闲状态
因此,可以得出结论:线程等待时间所占⽐例越⾼,需要越多线程;线程CPU时间所占⽐例越⾼,需要越少线程。
创建多少个线程合适?
CPU密集型程序创建多少个线程合适?
从前面例子我们已经发现,理论上线程数量 = CPU 核数(逻辑)即可,实际上,数量一般设置为CPU 核数(逻辑)+ 1.why?看《Java并发编程实战》中说:
计算(CPU)密集型的线程恰好在某时因为发⽣⼀个⻚错误或者因其他原因⽽暂停,刚好有⼀个“额外”的线程,可以确保在这种情况下CPU周期不会中断⼯作。
I/O密集型程序创建多少个线程合适?
实际上,当一个线程进行IO阻塞让出CPU给其他线程“瓜分”时,为均分,一般般就是刚好其他线程CPU执行时间能够瓜分IO时间。
最佳线程数 = (1/CPU利⽤率) = 1 + (I/O耗时/CPU耗时)
例如:CPU耗时1,IO耗时6.
最佳线程 = 1 / (1 / 1 + 6) = 1 + 6 = 7 个线程
如果是多核情况,再乘以核数即可
最佳线程数 = CPU核⼼数 * (1/CPU利⽤率) = CPU核⼼数 * (1 + (I/O耗时/CPU耗时))
上述例子如果是4核,则28个线程。
理论上来说,这样就能达到 CPU 100% 的利⽤率如果理论都好⽤,那就⽤不着实践了,也就更不会有调优的事出现了。不过在初始阶段,我们确实可以按照这个理论之作为伪标准, 毕竟差也可能不会差太多,这样调优也会更好⼀些
谈完理论,咱们说点实际的,现在两个疑问:
- 怎么知道具体的 I/O耗时和CPU耗时呢?
- 怎么查看CPU利⽤率?
有几个工具可以得到准确数据:SkyWalking, CAT, zipkin
下面再看几个场景例子:
1.假设要求⼀个系统的 TPS(Transaction Per Second 或者 Task PerSecond)⾄少为20,然后假设每个Transaction由⼀个线程完成,继续假设平均每个线程处理⼀个Transaction的时间为4s.
问:如何设计线程个数,使得可以在1s内处理完20个Transaction?
很简单,平均一个线程处理Transaction是4s,则一个线程每s处理0.25TPS,要求20, 20/0.25 = 80个线程。
但是,这还没有考虑CPU数目,一般服务器CPU核数为16或者32,如果有80个线程,那么肯定会带来太多不必要的线程上下⽂切换开销,这就需要调优了,来做到最佳 balance
2.计算操作需要5ms,DB操作需要 100ms,对于⼀台 8个CPU的服务器,怎么设置线程数呢?
按照前面公式线程数 = 8 * (1 + 100/5) = 168 (个)
那如果DB的 QPS(Query Per Second)上限是1000,此时这个线程数⼜该设置为多⼤呢?
当前处理一个任务时间为5 + 100 = 105ms,那么一个线程每秒可以处理的任务数为:1000/105
那么168个线程每秒可以处理的任务数为 168 * 1000 / 105 = 1600 QPS,由于上限1000,所以线程数量应该为168 * 1000/ 1600 = 105个。
增加 CPU 核数⼀定能解决问题吗?
看到这,有些同学可能会认为,即便我算出了理论线程数,但实际CPU核数不够,会带来线程上下⽂切换的开销,所以下⼀步就需要增加 CPU 核数,那我们盲⽬的增加 CPU 核数就⼀定能解决问题吗?
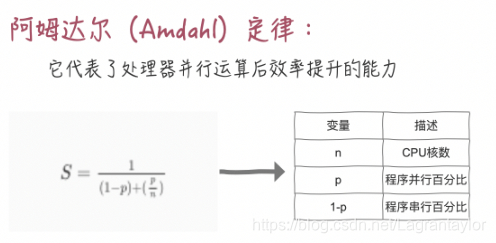
怎么理解这个公式呢?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-d9wnSlgY-1626955891820)(Java面试基础_线程池.assets/image-20210721230916761.png)]
这个结论告诉我们,假如我们的串⾏率是 5%,那么我们⽆论采⽤什么技术,最⾼也就只能提⾼ 20 倍的性能。
如何简单粗暴的理解串⾏百分⽐(其实都可以通过⼯具得出这个结果的)呢?来看个⼩ Tips:
Tips: 临界区都是串⾏的,⾮临界区都是并⾏的,⽤单线程执⾏临界区的时间/⽤单线程执⾏(临界区+⾮临界区)的时间就是串⾏百分⽐
因此,在使用synchronized时,最小化临界区范围,也是具有意义的了。
现在我们知道创建多少个线程合适了,那么为什么还要搞出来一个线程池出来?创建一个线程都要做哪些事情?为什么说频繁的创建线程开销很⼤?
线程池
手动创建线程很简单,为什么要使用线程池?
手动创建线程的缺点?
- 不受控风险
- 频繁创建开销大
不受控风险
系统资源有限,每个⼈针对不同业务都可以⼿动创建线程,并且创建标准不⼀样(⽐如线程没有名字)。当系统运⾏起来,所有线程都在疯狂抢占资源,⽆组织⽆纪律,混乱场⾯。而且过多的线程会引起上下文切换的开销
频繁创建开销大
创建⼀个线程⼲了什么就开销⼤了?和我们创建⼀个普通 Java 对象有什么差别?
按照常规理解 new Thread() 创建⼀个线程和 new Object() 没有什么差别。Java中万物接对象,因为 Thread 的⽼祖宗也是 Object。可是new Thread() 在操作系统层⾯并没有创建新的线程,这是编程语⾔特有的。真正转换为操作系统层⾯创建⼀个线程,还要调⽤操作系统内核的API,然后操作系统要为该线程分配⼀系列的资源
Object object = new Object() 过程
- 分配一块内存M
- 在内存M上初始化该对象
- 将内存M的地址赋值给引用变量obj
创建一个线程的过程
为了更好的理解创建并启动⼀个线程的开销,我们需要看看 JVM 在背后帮我们做了哪些事情:
- 它为⼀个线程栈分配内存,该栈为每个线程⽅法调⽤保存⼀个栈帧
- 每⼀栈帧由⼀个局部变量数组、返回值、操作数堆栈和常量池组成
- ⼀些⽀持本机⽅法的 jvm 也会分配⼀个本机堆栈
- 每个线程获得⼀个程序计数器,告诉它当前处理器执⾏的指令是什么
- 系统创建⼀个与Java线程对应的本机线程
- 将与线程相关的描述符添加到JVM内部数据结构中
- 线程共享堆和⽅法区域
创建⼀个线程(即便不⼲什么)需要多⼤空间呢?⼤约 1M 左右,下列命名可查看
java -XX:+UnlockDiagnosticVMOptions -XX:NativeMemoryTracking=summary -
XX:+PrintNMTStatistics -version
什么是线程池?
Java提供了它⾃⼰实现的线程池模型—— ThreadPoolExecutor 。套⽤池化的想象来说,Java线程池就是为了最⼤化⾼并发带来的性能提升,并最⼩化⼿动创建线程的⻛险,将多个线程统⼀在⼀起管理的思想
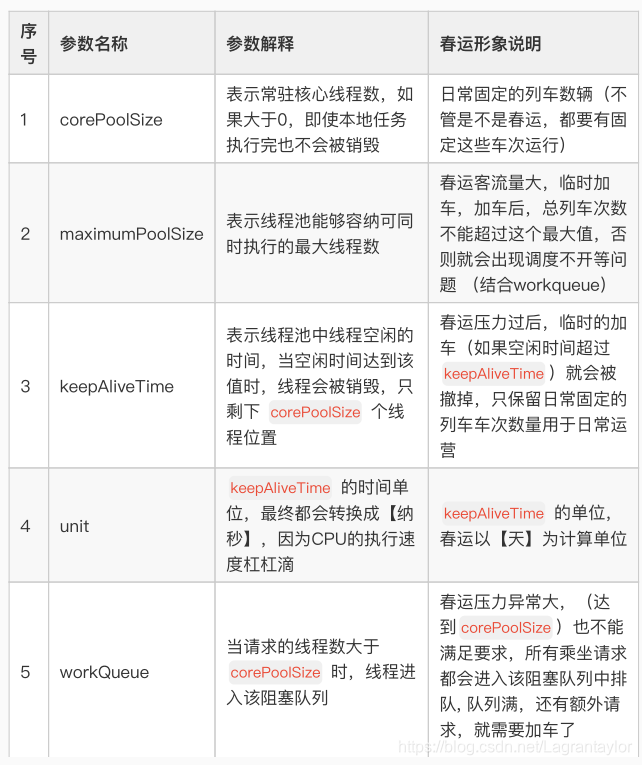
构造函数与相关参数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}

工作流程:
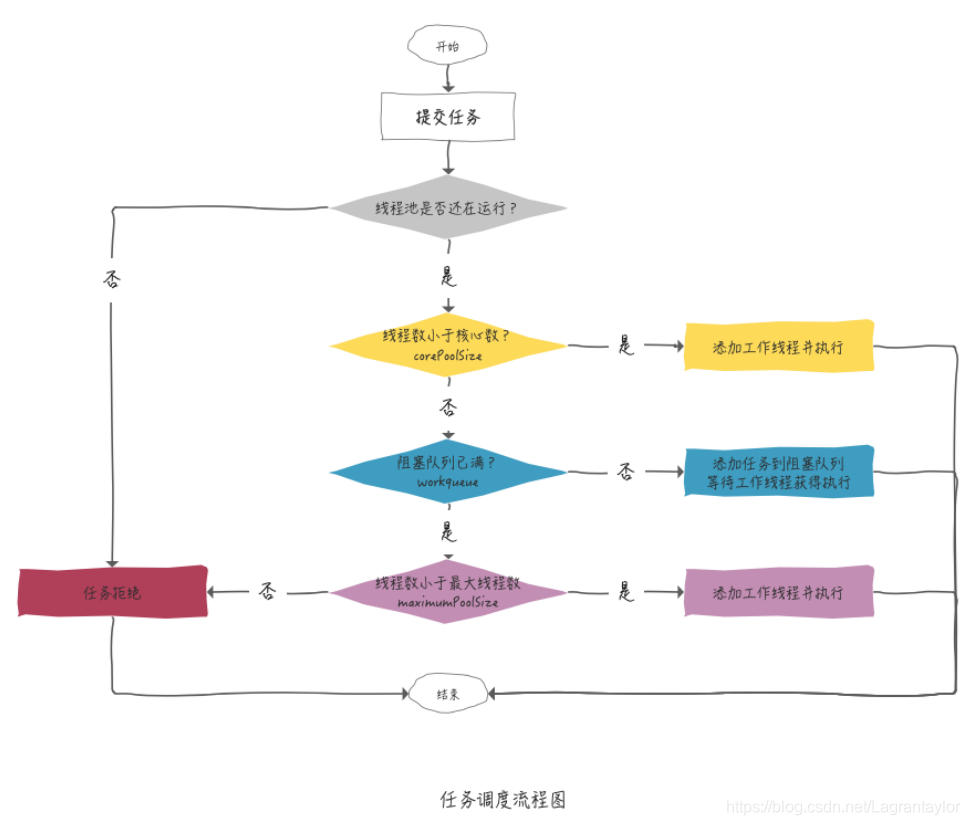
为啥要等阻塞队列满了才去创建额外线程?
业务是有高峰低谷的,低谷时没必要那么多线程,高峰时需要更多。任务队列提供了从核心线程数,转变成最大线程数的一个缓冲,不至于任务一多就轻易创建线程。
线程池的作用
- 利⽤线程池管理并服⽤线程,控制最⼤并发数(⼿动创建线程很难得到保证)
- 实现任务线程队列缓存策略和拒绝机制
- 实现某些与实践相关的功能,如定时执⾏,周期执⾏等(⽐如列⻋指定时间运⾏)
- 隔离线程环境,⽐如,交易服务和搜索服务在同⼀台服务器上,分别开启两个线程池,交易线程的资源消耗明显要⼤。因此,通过配置独⽴的线程池,将较慢的交易服务与搜索服务个离开,避免个服务线程互相影响
线程池使⽤思想/注意事项
线程池拒绝策略
我们很难准确的预测未来的最⼤并发量,所以定制合理的拒绝策略是必不可少的步骤。默认情况, ThreadPoolExecutor 提供了四种拒绝策略:
- AbortPolicy:默认的拒绝策略,会 throw RejectedExecutionException 拒绝
- CallerRunsPolicy:提交任务的线程⾃⼰去执⾏该任务
- DiscardOldestPolicy:丢弃最⽼的任务,其实就是把最早进⼊⼯作队列的任务丢弃,然后把新任务加⼊到⼯作队列
- DiscardPolicy:相当⼤胆的策略,直接丢弃任务,没有任何异常抛出
不同的框架(Netty,Dubbo)都有不同的拒绝策略,我们也可以通过实现 RejectedExecutionHandler ⾃定义的拒绝策略
禁⽌使⽤Executors创建线程池
Executors ⼤⼤的简化了我们创建各种类型线程池的⽅式,为什么还不让使⽤呢?其实,看看它的静态⽅法参数就明⽩了。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
/* 进入构造函数 */
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
传⼊的workQueue 是⼀个边界为 Integer.MAX_VALUE 队列,我们也可以变相的称之为⽆界队列了,因为边界太⼤了,这么⼤的等待队列也是⾮常消耗内存的
/**
* Creates a {@code LinkedBlockingQueue} with a capacity of
* {@link Integer#MAX_VALUE}.
*/
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
另外该 ThreadPoolExecutor⽅法使⽤的是默认拒绝策略(直接拒绝),但并不是所有业务场景都适合使⽤这个策略,当很重要的请求过来直接选择拒绝显然是不合适的
private static final RejectedExecutionHandler defaultHandler =
new AbortPolicy();
总的来说,使⽤ Executors 创建的线程池太过于理想化,并不能满⾜很多现实中的业务场景,所以要求我们通过 ThreadPoolExecutor来创建,并传⼊合适的参数