之前的格物汇文章给大家介绍过,无论是提供商品还是服务,用户画像都是数据挖掘工作的重要一环。而要深度构建用户画像,就必须对用户的数据进行关联分析,得到精准的推荐算法。作为关联分析常用的经典算法,Apriori算法可以挖掘出数据中经常一起出现的数据,我们称之为频繁集。但是Apriori算法需要多次扫描数据,在海量数据面前效率显得非常低。今天的格物汇就带大家来了解一种新的算法:FP Tree。只需要全部扫描两遍数据,即可获得数据的频繁集,是不是很神奇呢?
 什么是FP Tree
什么是FP Tree
FP即FrequentPattern,FP树的根节点是空集,其他结点由单个元素以及这个元素在数据集中的出现次数组成,出现次数越多的元素越接近根节点。此外,结点之间通过链接(link)相连,只有在数据中同时出现的元素才会被连起来,连起来的元素形成频繁集。同一个元素可以在FP树中多次出现,根据位置不同,对应着不同的频繁项集。可以为FP树设置最小支持度,过滤掉出现次数太少的元素。
 FP树构建的步骤
FP树构建的步骤
上面的论述可能过于抽象,我们还是通过一个具体的案例来看,我们还是用商店的销售数据来作为案例说明,假如某个商店的购物篮数据如下:一共有A,B,C,D,E,F,G 7种商品。
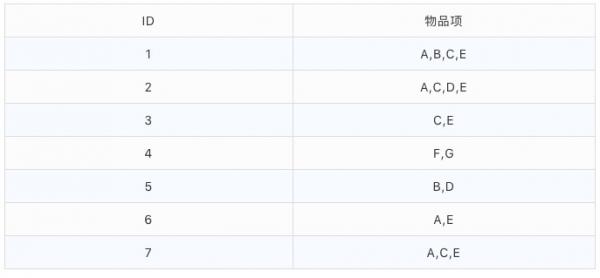
我们的目标是:找到物品项中频繁出现的商品组合。按照FP-tree的做法,我们首先需要统计每一个频繁一项集的支持度,也就是单个商品出现计数,结果如下:
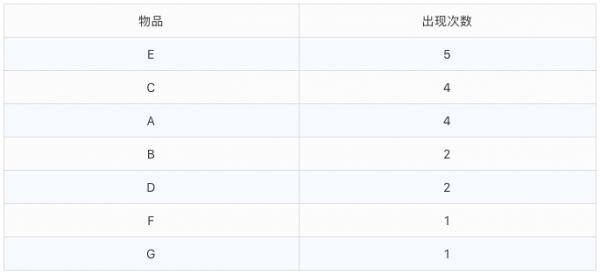
此时,我们可以根据需要,把支持度较小的物品舍去,比如F和G,他们只出现了一次,在建树的过程中将不会出现它们。接下来,我们就要开始构建树了。首先最开始的根节点固定为空,表示开始时FP树没有数据,建立FP树时我们一条条的读入数据集,插入FP树,例如我们读取第一条数据时:
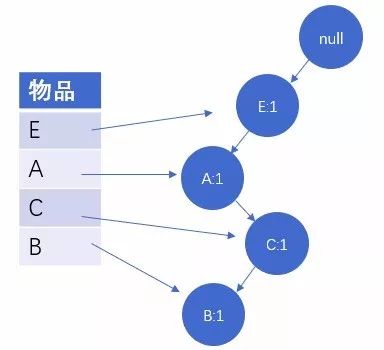
图1:读取第一条数据
我们可以看到第一个节点为null,代表空节点,空节点下每一个节点上分别由物品和其计数的数字组成,他们共同组成了树的一个枝桠,并且他们的顺序是根据元素出现次数多少进行排序的。以此类推,我们可以依次读取第二条数据,与第一条类似,同样生成一条树的枝桠,重复的枝桠节点物品个数将叠加:
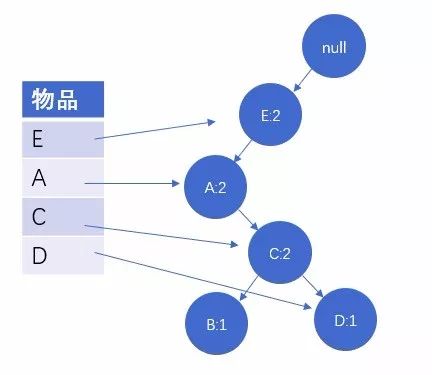
图2:读取第二条数据
接着,我们依次读取其他的数据:
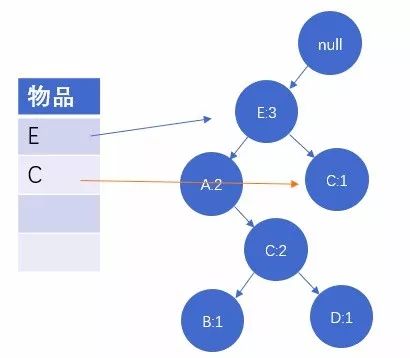
图3:读取第三条数据
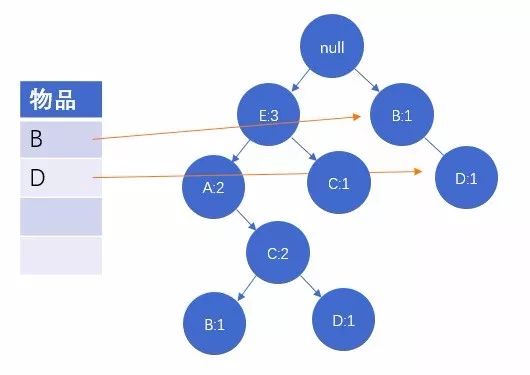
图4:读取第四条数据
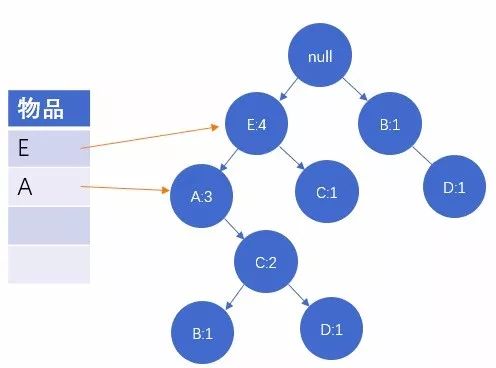
图5:读取第五条数据
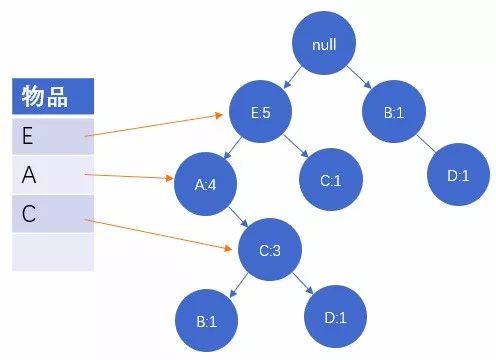
图6:读取第六条数据
至此,数据读取完以后,FP-tree也就生成了,那么我们怎么去找频繁项集呢?我们从最长的结点开始找起,不难发现{E,A,C,B}和{E,A,C,D} 次数都仅为1,于是再找其他的枝桠,最终可以很容易的发现频繁项集为{E,A,C}。当然也可以设定一个支持度阈值,来筛选频繁项集。
 FP树小结
FP树小结
FP Tree算法改进了Apriori算法的I/O瓶颈,巧妙的利用了树结构,提高算法运行速度。利用内存数据结构以空间换时间是常用的提高算法运行时间瓶颈的办法。现在对FP树的算法流程做一个简单的归纳:
扫描数据,得到频繁-项集的计数,剔除支持度较低的项集。
对数据按技术进行排序。
按照排序后的数据,依次读取放到FP树中,进行树的构建。在对应的物品计数中进行叠加。
跟进FP树依次查找支持度满足条件的枝桠,即最后的结果。
好了,以上就是本期格物汇的内容,我们下期再见。
本文作者:格创东智OT团队(转载请注明作者及来源)