本文主要内容
- Hadoop环境介绍;
- 分布式文件系统[HDFS]的基本组件与四大机制;
- 分布式计算[MapReduce]的策略、理念、体系架构与工作流程;
- 数据仓库工具[Hive]的起源、特点、四种数据模型以及HQL转换MapReduce的原理;
- 数仓分层的好处、通用的数据分层设计以及分层设计示例。
本文目录
第一节 Hadoop 环境
1.1 分布式文件系统[HDFS]
现在企业环境中,单机容量无法存储大量数据,需要跨机器[集群]存储,而统一管理分布在集群上的文件系统称之为分布式文件系统。
HDFS(Hadoop Distributed Fill System) 是Hadoop的子项目,使用多台计算机存储文件,并且提供统一的访问接口(NameNode),像是访问一个普通文件系统一样使用分布式文件系统。
默认切割固定大小128M,储存3份
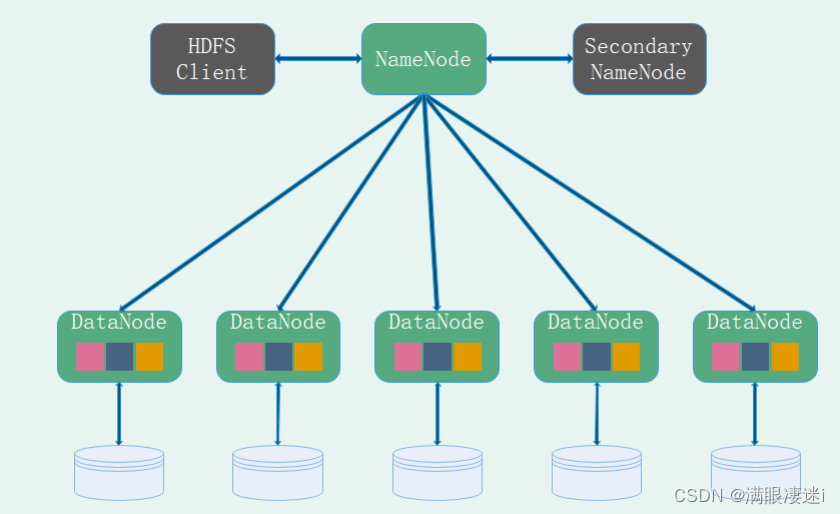
HDFS基本组件
HDFS Client : 提供命令管理HDFS,工作职责:读/删除/覆盖 哪个文件
NameNode:管理整个文件系统的元数据 , 工作职责:管理元数据、维护目录结构、响应客户端请求
DataNode:复制管理用户的文件数据块, 工作职责:管理用户提交的数据、心跳机制、块报告
SecondaryNameNode:NameNode的助理(备份),帮助加载元数据,紧急情况下(例如NameNode宕机),可以帮助恢复数据
HDFS四大机制
心跳机制(Master/Slave结构, Master是NameNode, Slave是DataNode)。
默认DataNode向NameNode发送请求的时间间隔为3s;
默认NameNode向DataNode发送请求的时间间隔为5min;
NameNoder如果长时间没有接收到DataNode的心跳,也会每隔一段时间(5min)向DataNode发送请求,一共会发两次。
安全模式 HDFS集群正常冷启动时,NameNode也会在safemode状态下维持相当长一段时间(没有加载完,不能有操作命令),等待它自动退出安全模式即可。
副本存放策略 将每个文件的数据进行分块存储(备份),每一个数据块有保存有多个副本,这些数据块副本分布在不同的机器节点上。
负载均衡 机器容量最高的那个值和最低的那个值差距不能超过10%,会自动调节。
1.2 分布式计算(MapReduce)
MapReduce 是一种分布式并行编程框架。
MapReduce 策略: 分而治之
MapReduce 理念: 计算向数据靠拢而不是数据向计算靠拢
- MapReduce 体系架构 【主从(Master/Slave)架构】
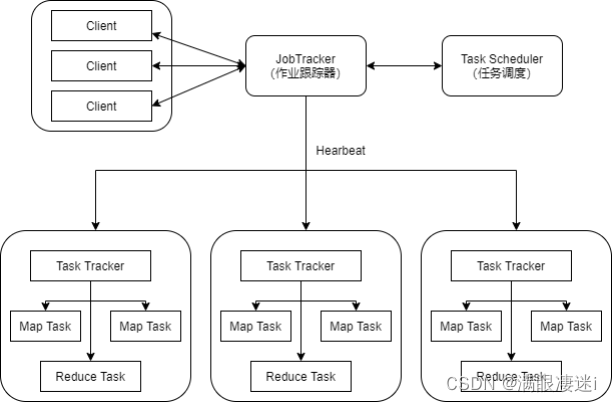
client(客户端):
通过Client可以提交用户编写的应用程序,用户通过它将应用程序提交到 JobTracker端;
用户也可以通过Client提供的一些接口去查看看前提交作业的运行状态。
JobTracker:
资源的监控和作业的调度
监控底层的其他的TaskTracker以及当前运行的Job的健康状况
一旦探测到失败的情况就把这个任务转移到其它节点继续执行跟踪任务执行和资源使用量
TaskTracker:
执行具体的相关任务一般接受Job Tracker 发送过来的命令(如启动新任务,杀死任务等)
把一些自己的资源使用情况,以及任务的运行进度通过心跳的方式也就是heartbest发送给JobTracker
Task:分为MapTask和Reduce Task两种,均由TaskTracker启动。
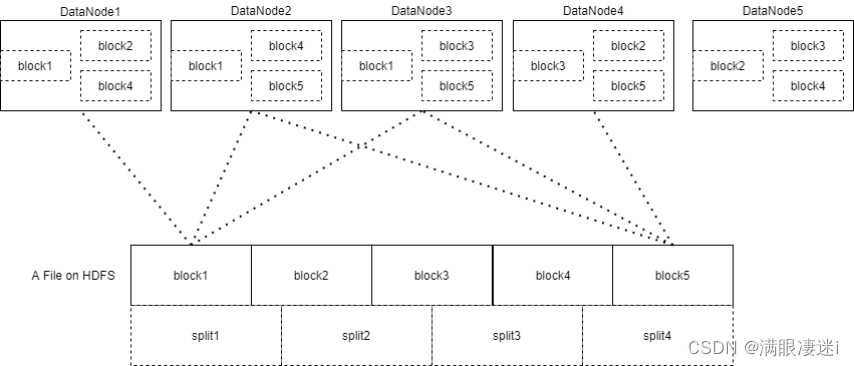
HDFS以固定大小的block为基本单位存储数据,而对于MapReduce而言,其处理单位是split。它的划分方法完全由用户自己决定。但需要注意的是,split的多少决定了MapTask的数目,因为每一个split只会交给一个MapTask处理。split与block的关系图如下:
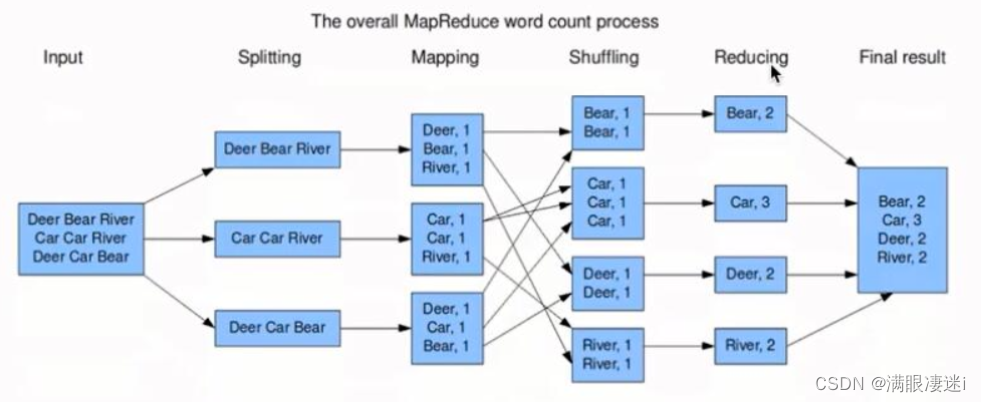
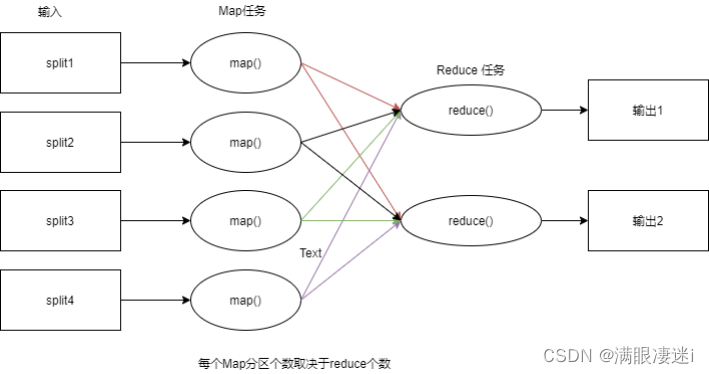
- Mapreduce工作流程
(Map是分,Reduce是合)
1.3 数据仓库工具(Hive)
Hive是Facebook为了解决海量日志数据的统计分析而开发的基于Hadoop的一个数据仓库工具(后来开源给了Apache软件基金会),可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能:HQL。
1.3.1 Hive特点
Hive 本身并不支持数据存储和处理,只是一个面向用户的编程接口
只负责管理Hive元数据(只负责hive表与Hdfs文件的映射关系, 元数据的存储是借助于mysql)
Hive 依赖分布式文件系统HDFS存储数据
Hive 依赖分布式并行计算模型MapReduce 处理数据
借鉴SQL语言设计了新的查询语言HiveQL
上传装载文件格式一般是文本格式/csv
1.3.2 四种数据模型
表
表——分区
表——分区——分桶
表——分桶
Hive中的分桶表最大的作用就是提高了 join的速度[见1.3.3(三)语句5]
1.3.3 HQL转换为MapReduce原理
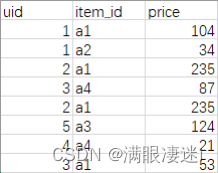
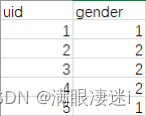
假如有两个表:
| Order表:表内容:用户id,商品id,付费金额 | User表:用户id,性别(1:男;2:女) |
|---|---|
 |  |
(一) 直接抽取
语句1
select uid,gender from user;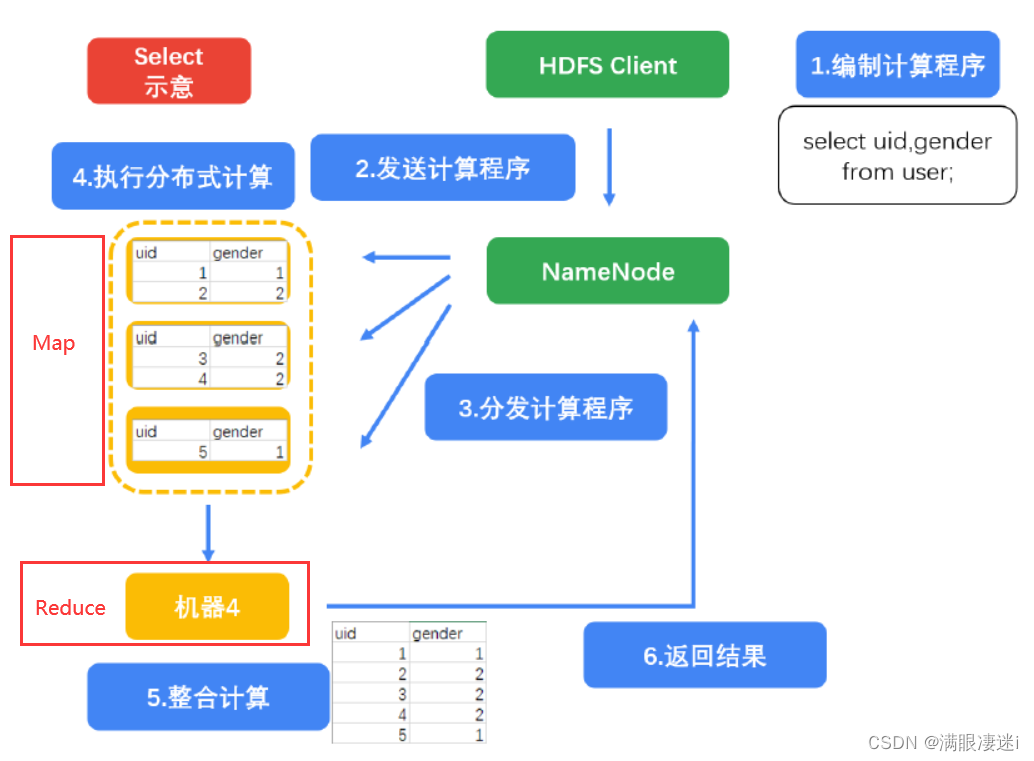
语句2
select uid,gender from user where gender = '1';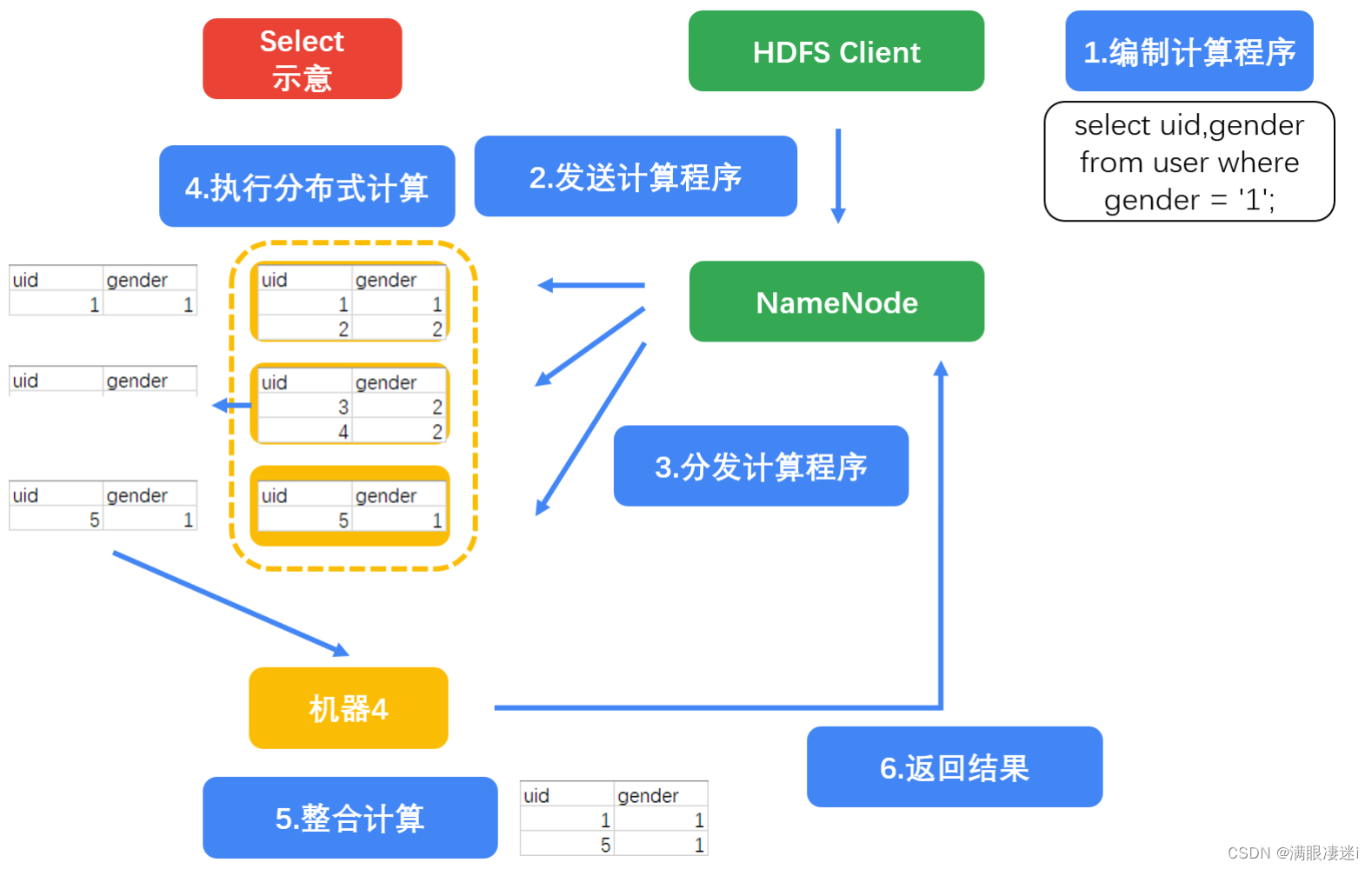
(二) group by
语句3
select count(uid) as uv,item_id from order group by item_id;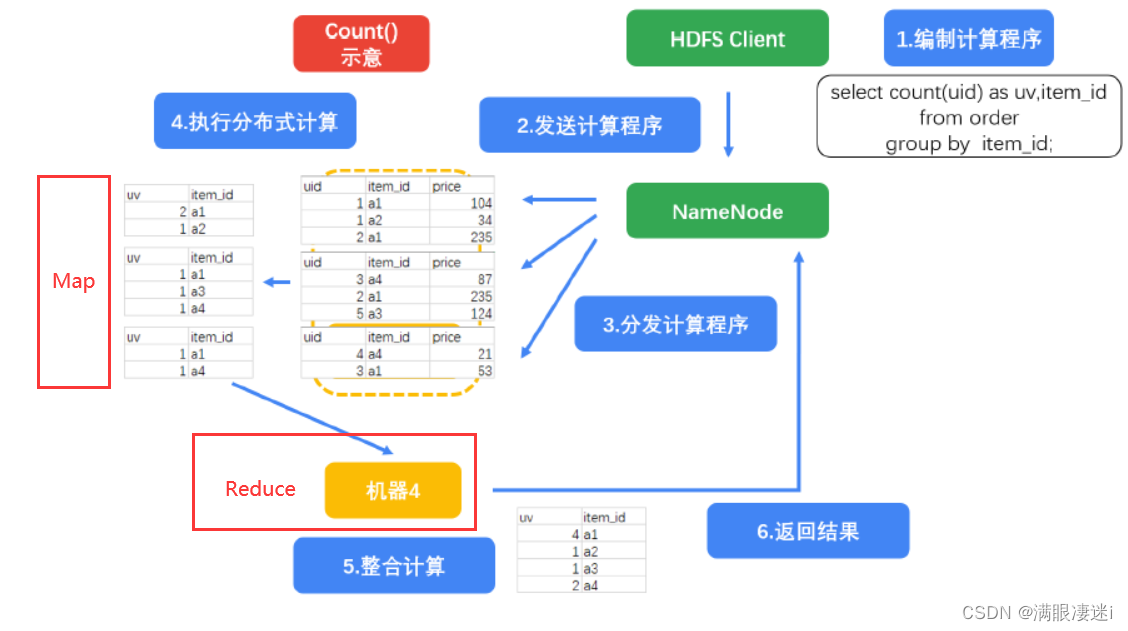
语句4
select count(distinct uid) as uv,item_id from order
group by item_id;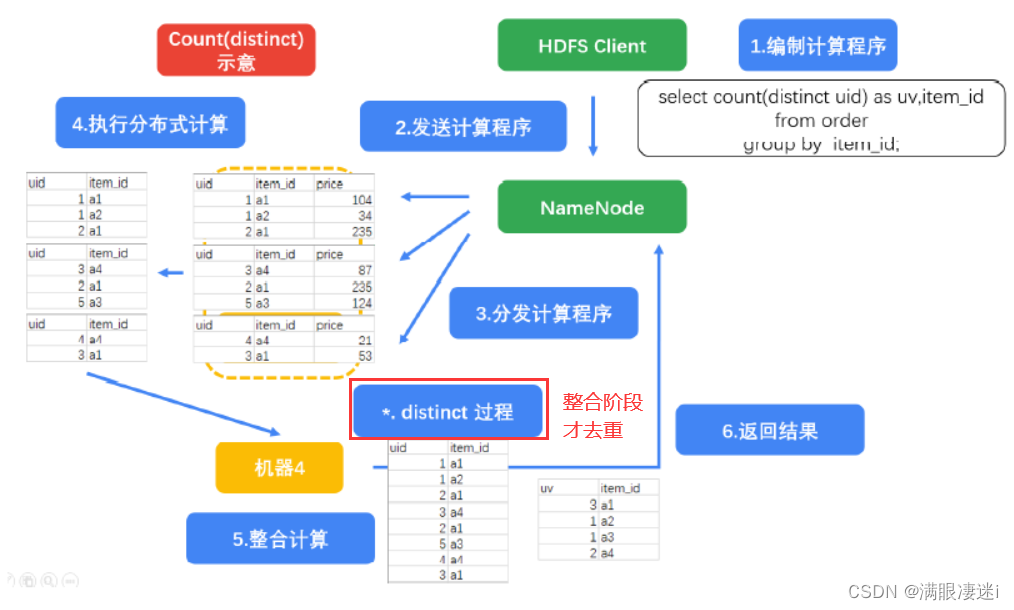
(三) join
语句5
select sum(price) as u_price,gender
from user a --左表尽量放小表,它会加载到内存中,这样速度会更快
join order b on a.uid = b.uid
group by gender;- 这里没有进行分桶
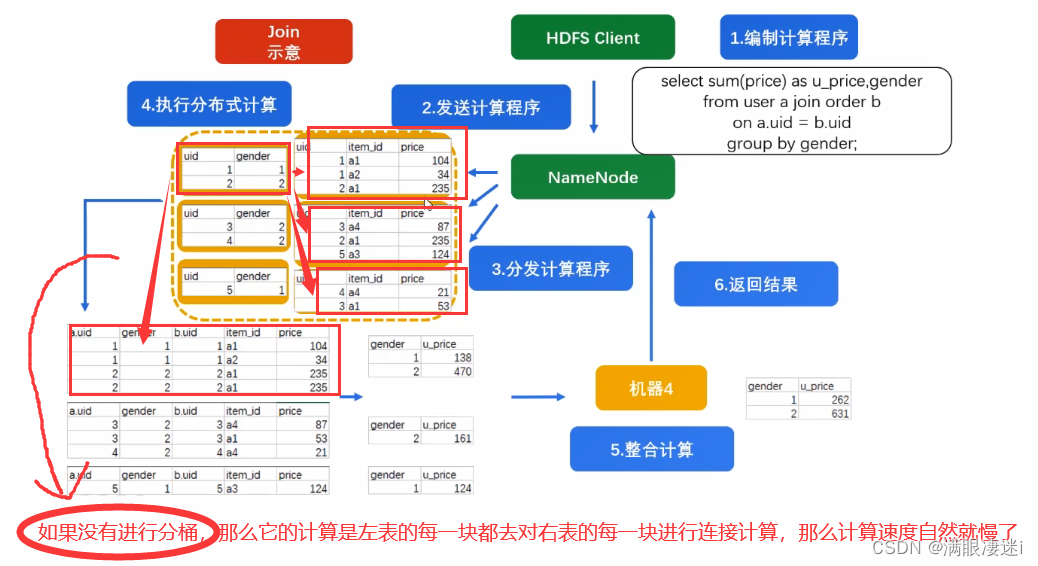
- 如果user和order都以 uid 进行了分桶,那么它以哈希值的计算原理是一样的,所以可以对应桶来进行关联
- Hive中的分桶表最大的作用就是提高了 join的速度
1.4 数仓分层
1.4.1 数据分层的好处
清晰数据结构:每一个数据分层都有它的作用域和职责,在使用表的时候能更方便地定位和理解。(每个层只能做它自己的事,不能去管其他层的事)
减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。(以空间换时间,因现在硬件集群廉价,可以买很多集群去做一些中间层数据存放,就不用每次计算都从头开始)
统一数据口径:通过数据分层,提供统一的数据出口,统一对外输出的数据口径。(在统一的一层中,所有的出口方式已经开发好,只需要取就行)
复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层解决特定的问题。(MySQL里的复杂的子查询,在这里可能每层都可以解决一个子查询)
1.4.2 通用的数据分层设计
以数据库对数据进行分层的
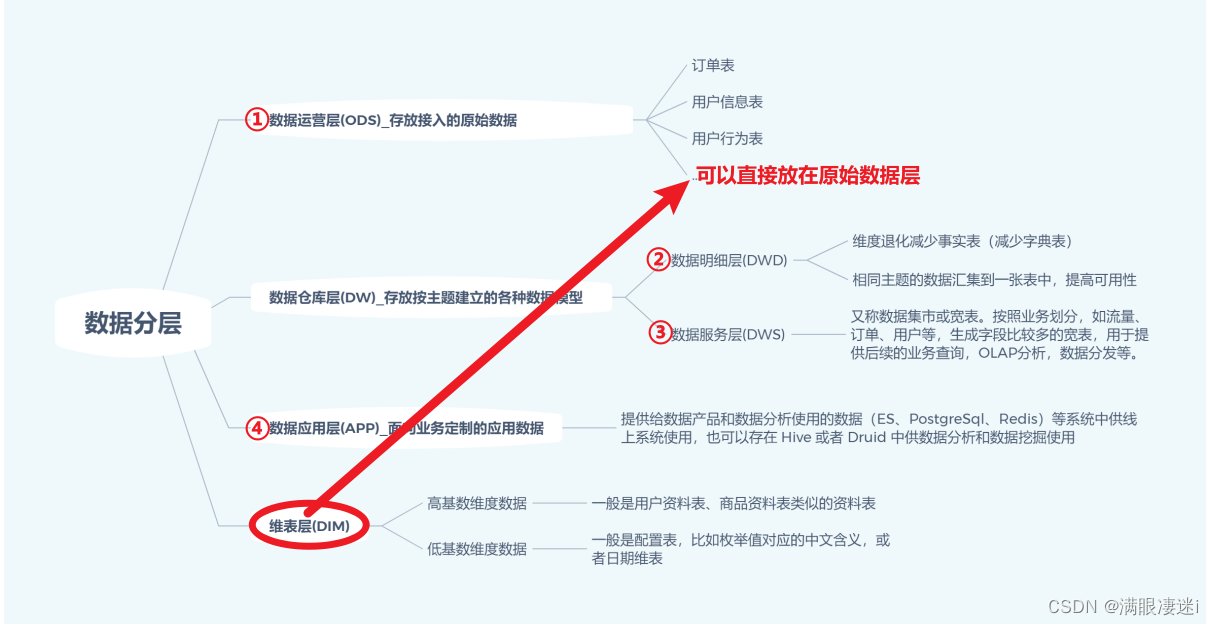
1.4.3 数据分层设计示例
(一)、电商网站的数据体系设计
暂且只关注用户访问行为及用户信息,商品信息等部分数据。

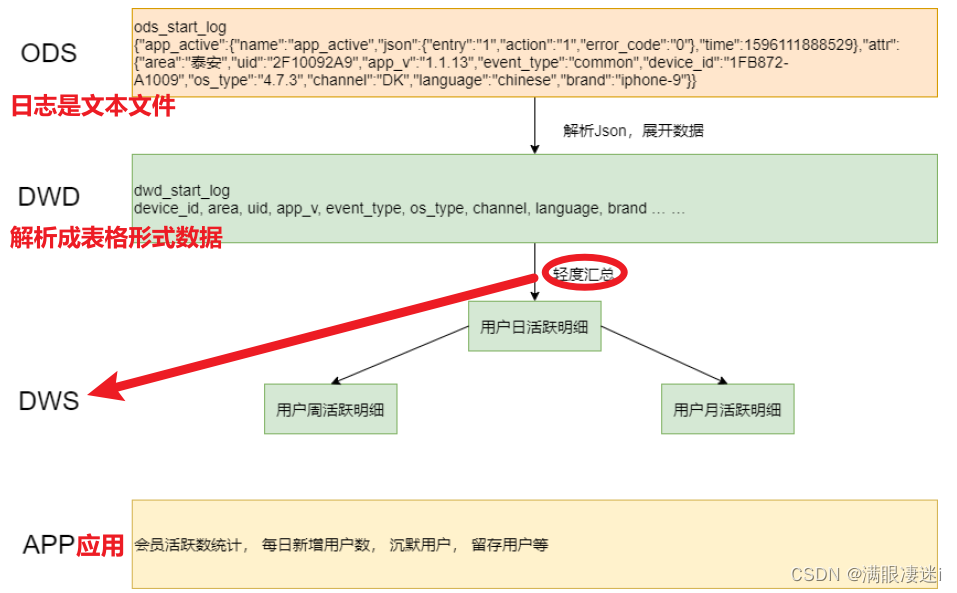
(二)、用户行为日志代码分层
一般事务数据库的日志是不入库的,就只是写一个文本文件(Json格式)
第二节 Hue 环境介绍
2.1 Apache Hue 介绍
2.1.1 Hue是什么
HUE=Hadoop User Experience
Hue是一个开源的Apache Hadoop UI系统,由Cloudera Desktop演化而来,最后Cloudera公司将其贡献给Apache基金会的Hadoop社区,它是基于Python Web框架Django实现的。
通过使用Hue,可以在浏览器端的Web控制台上与Hadoop集群进行交互,来分析处理数据,例如操作 HDFS上的数据,运行MapReduce Job,执行Hive的HQL语句,浏览HBase数据库等等
2.1.2 Hue能做什么
访问HDFS和文件浏览
通过web调试和开发hive以及数据结果展示
通过web调试和开发impala交互式SQL Query
spark调试和开发
Pig开发和调试
Hbase数据查询和修改,数据展示
Hive的元数据(metastore)查询
MapReduce任务进度查看,日志追踪
创建和提交MapReduce,Streaming,Java job任务
Sqoop2的开发和调试
Zookeeper的浏览和编辑
数据库(MySQL,PostGres,SQlite,Oracle)的查询和展示
2.2 Apache Hue 界面应用
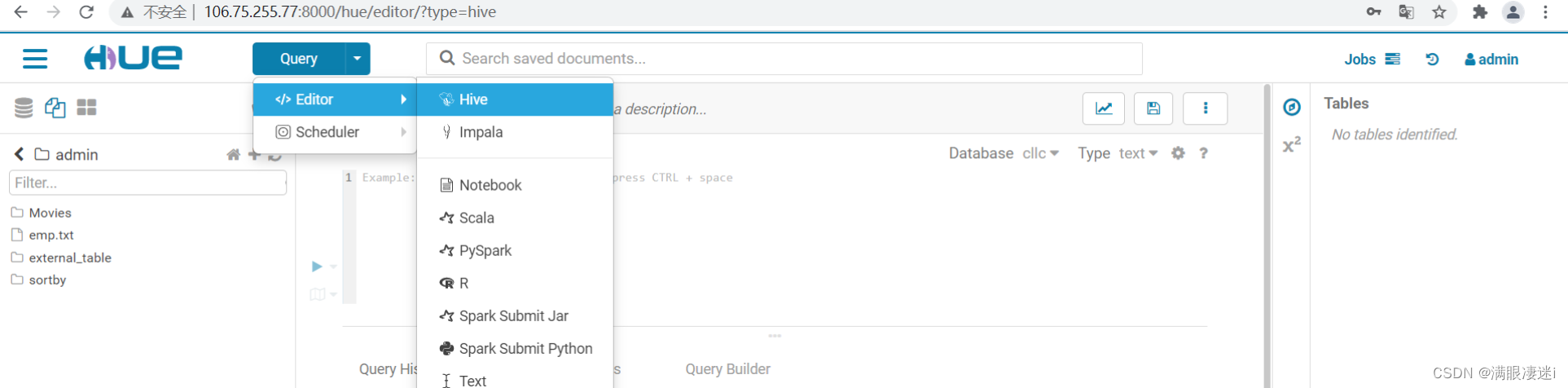
1.输入 Hue - Welcome to Hue 网址 ;
2.输入用户名密码进入Hue主界面,点击Query下拉按钮,选择Editor下的Hive选项,进入Hive;
3.选中数据库图标,对现有数据库进行操作
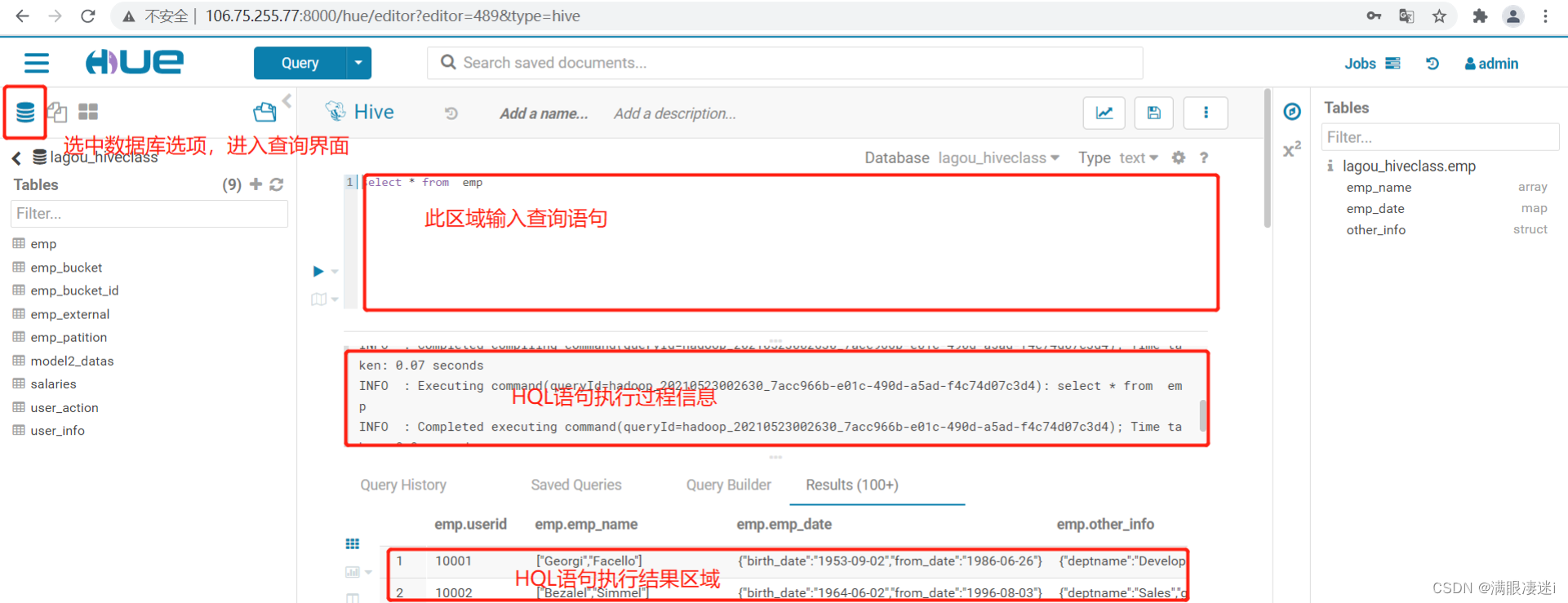
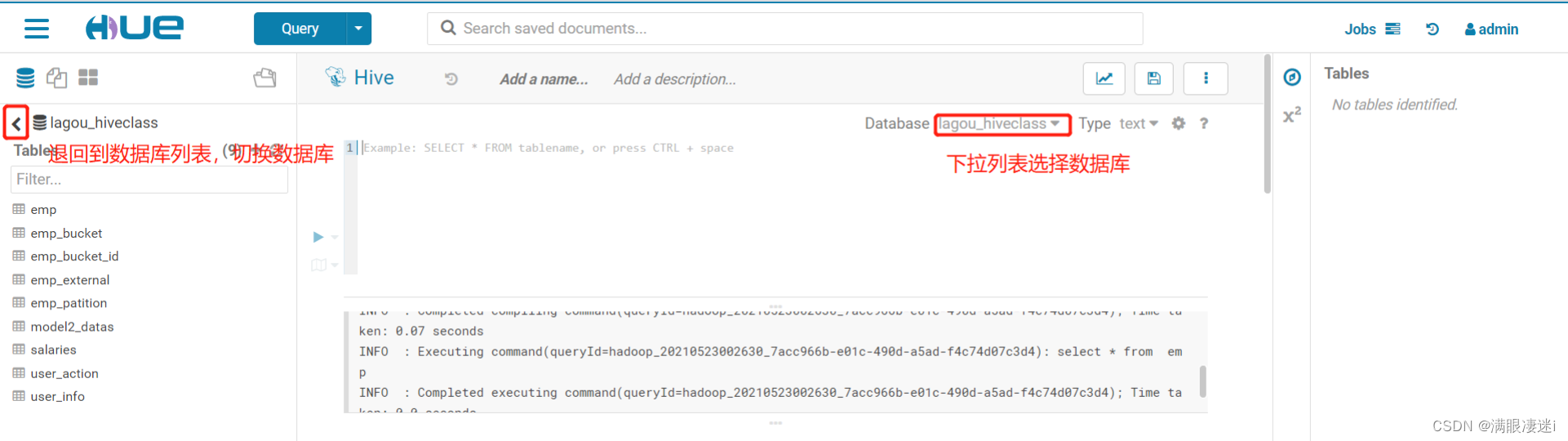
4.切换数据库 可是使用“use 数据库名” ,也可以点击左侧 < 箭头,到数据库列表中, 或着编辑区域上册Database 处进行下拉选择
注意:左侧列表显示与Database 处显示不一致时,以Database 处为准
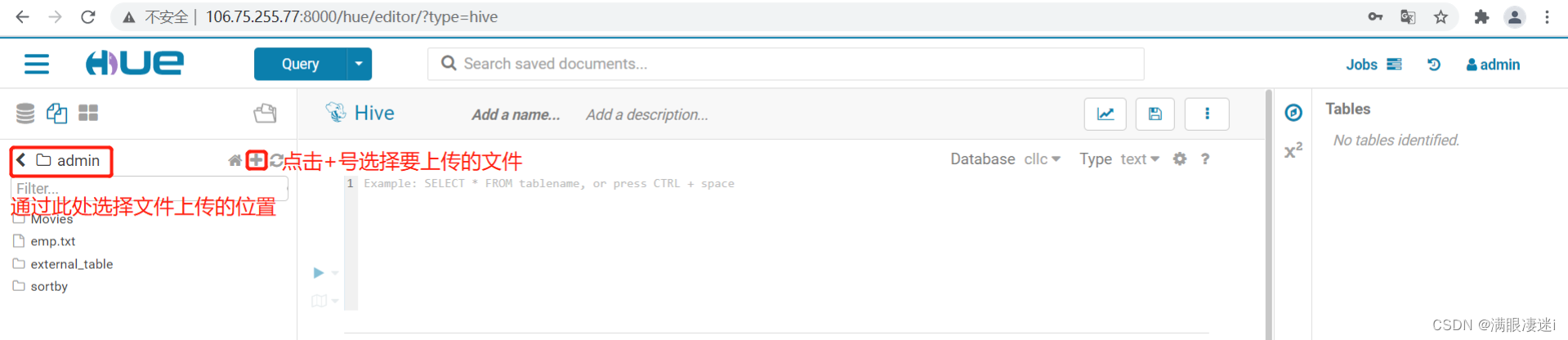
5.上传文件进行数据装载: 点击左侧文件图标,或者点击Hue 图标标前的三图标选择 Files 进入文件管理界面
注意:文件一旦被load到数据库的表中,文件将被移动到相应表的目录下
6.管理文件:点击Hue 图标标前的三图标选择 Files 进入文件管理界面
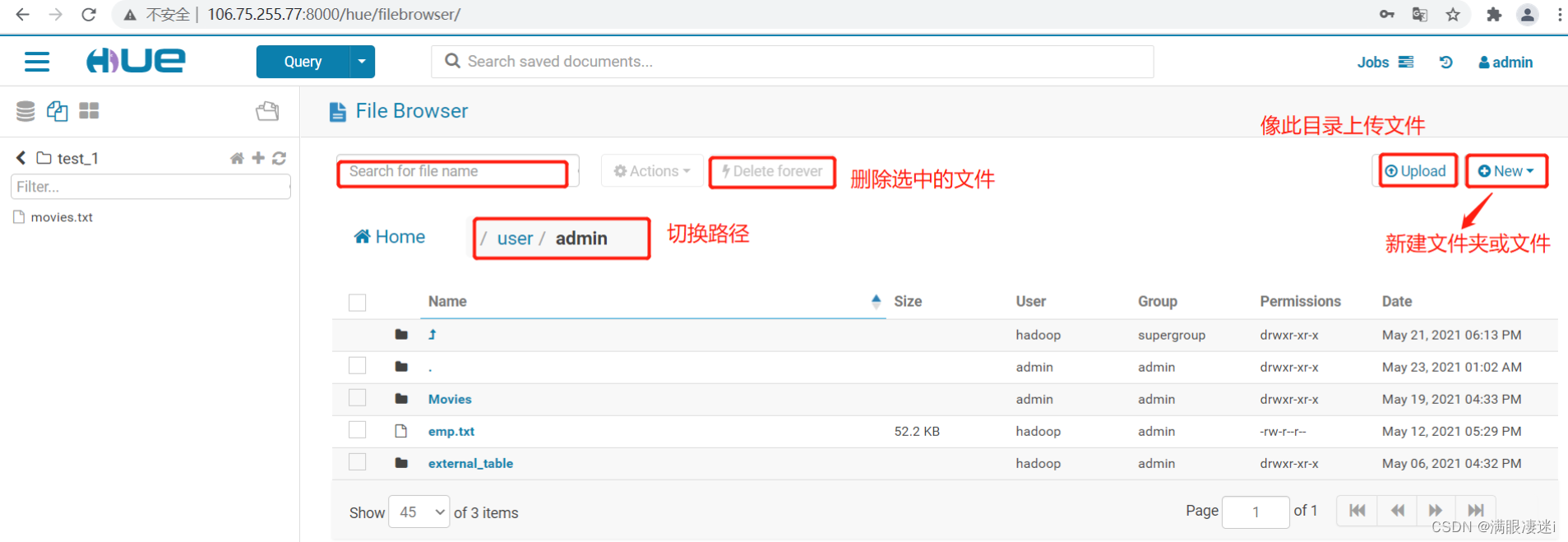
点击任意文件,可以对当前文件进行编辑或下载
第三节 本文知识总结
hadoop 核心分布式存储 + 分布式计算
分布式存储(HDFS) hadoop.2X(默认块大小128M,备份数 3)
分布式计算 MapReduce (分而治之,分而后和)
hive 数仓工具的特点:
①基于HDFS存储数据;
②基于MapReduce 处理数据;
③类SQL 语句 HQL;
④只负责管理Hive 元数据(只负责hive表与Hdfs 文件的映射关系, 元数据的存储是借助于mysql)。
数据分层存储作用
区域化管理,数据体系结构清晰,指标口径统一,避免重复计算,复杂问题简单化
通过Hue访问操作数据库
①对“数据库菜单”的操作
②对“文件菜单”的操作