获取收件箱列表信息就是使用selenium实现模拟登录、点击收件箱链接、获取收件箱列表的html过程,然后就是正常的查找数据
1.我们首先就是要登录到QQ邮箱中,然后找到收件箱的页面的,才能爬取到我们需要的数据,需要好注意的是在出现登录界面和收件箱界面的时候需要Frame切换/窗口切换,否者无法找到指定的元素;还有就是QQ邮箱登录分为QQ登录和QQ未登录2种状态。QQ登录时,登录QQ邮箱只需要点击QQ登录图标就可实现邮箱登录。未登录时,则要输入用户密码
#登录QQ邮箱
def login(user,pwd):
try:
driver=webdriver.Edge()
driver.get("http://mail.qq.com")
time.sleep(3)
driver.switch_to.frame("login_frame")#
images="img_out_"+user#因为QQ头像的id就是img_out_加上自己的QQ号,所以提前使用拼接的方法设置一个参数
#QQ已经登录
if driver.find_element_by_id(images):
driver.find_element_by_id(images).click()
else:#QQ没有登录
driver.find_element_by_css_selector("#u").send_keys(user)#找到用户名登录并输入qq号
driver.find_element_by_id("p").send_keys(pwd) #找到密码框并输入密码
driver.find_element_by_id("logon_button").click() #找到登录按钮并点击
time.sleep(6)
driver.find_element_by_id("folder_1").click()#找到收件箱并点击
driver.switch_to.frame("mainFrame")#切换窗口
return driver.find_elements_by_css_selector("table")[1::2] #将收件箱的第一页数据全部取出来作为返回值
except Exception as error:
print ("login",error)2.第二点就是解析我们取到的数据了
#解析数据
def parse(sobj):
try:
out_list = []
for i in sobj:
sendInfo = i.find_elements_by_css_selector("td .tf span")[0]#找到发件人和发件人邮箱的父节点
#发件人
source = sendInfo.text
#发件人Email
sendmail = sendInfo.get_attribute("e")
#邮件标题
title = i.find_element_by_css_selector(".gt u").text
#收件日期
dt = i.find_element_by_css_selector(".dt div").text
out_list.append([source,sendmail,title,dt])
print(out_list)
return out_list
except Exception as error:
print("parse",error)3.最后就是将数据以csv格式保存下来
#保存数据
def save(data,path): #输出csv公共函数
with open(path,"a+",newline='',encoding='utf-8') as f:
writer=csv.writer(f)
title=['发件人','发件人邮箱','内容','时间']
writer.writerow(title)
writer.writerows(data)爬取保存下来就是这样的:
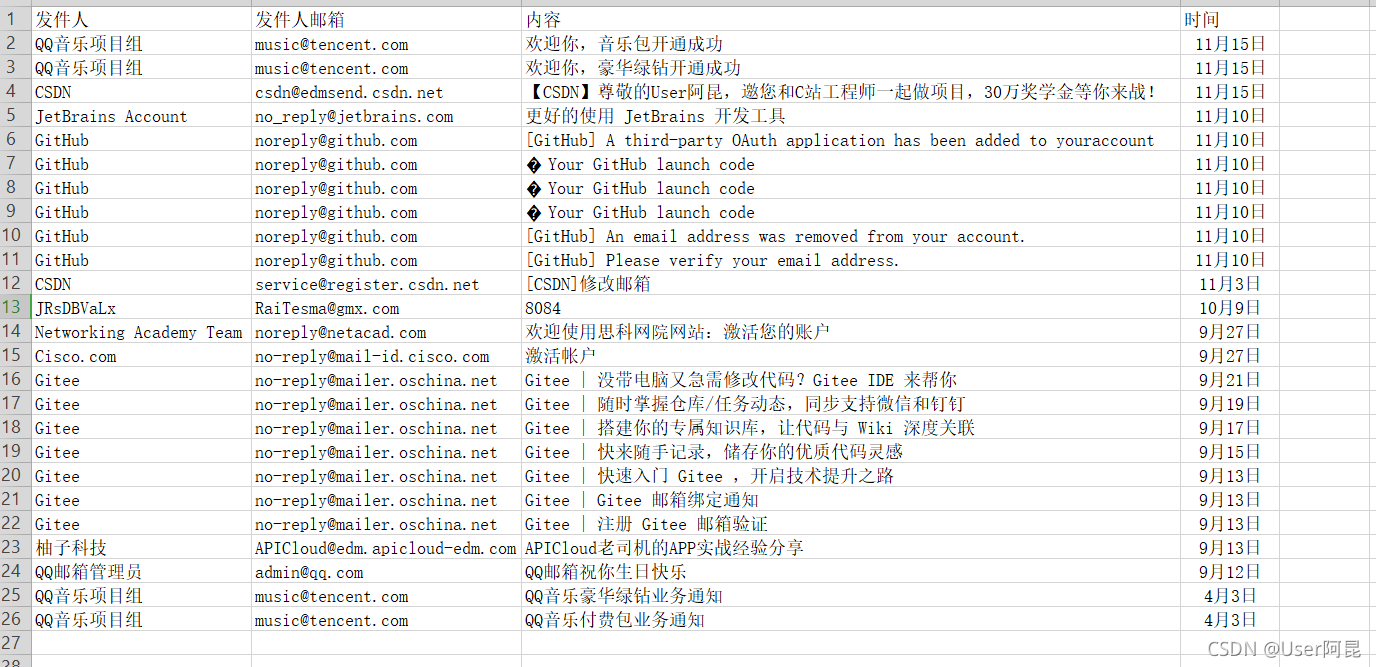
下面就是完整代码:
from selenium import webdriver
import time
import csv
#登录QQ邮箱
def login(user,pwd):
try:
driver=webdriver.Edge()
driver.get("http://mail.qq.com")
time.sleep(3)
driver.switch_to.frame("login_frame")#
images="img_out_"+user#因为QQ头像的id就是img_out_加上自己的QQ号,所以提前使用拼接的方法设置一个参数
#QQ已经登录
if driver.find_element_by_id(images):
driver.find_element_by_id(images).click()
else:#QQ没有登录
driver.find_element_by_css_selector("#u").send_keys(user)#找到用户名登录并输入qq号
driver.find_element_by_id("p").send_keys(pwd) #找到密码框并输入密码
driver.find_element_by_id("logon_button").click() #找到登录按钮并点击
time.sleep(6)
driver.find_element_by_id("folder_1").click()#找到收件箱并点击
driver.switch_to.frame("mainFrame")#切换窗口
return driver.find_elements_by_css_selector("table")[1::2] #将收件箱的第一页数据全部取出来作为返回值
except Exception as error:
print ("login",error)
#解析数据
def parse(sobj):
try:
out_list = []
for i in sobj:
sendInfo = i.find_elements_by_css_selector("td .tf span")[0]#找到发件人和发件人邮箱的父节点
#发件人
source = sendInfo.text
#发件人Email
sendmail = sendInfo.get_attribute("e")
#邮件标题
title = i.find_element_by_css_selector(".gt u").text
#收件日期
dt = i.find_element_by_css_selector(".dt div").text
out_list.append([source,sendmail,title,dt])
print(out_list)
return out_list
except Exception as error:
print("parse",error)
#保存数据
def save(data,path): #输出csv公共函数
with open(path,"a+",newline='',encoding='utf-8') as f:
writer=csv.writer(f)
title=['发件人','发件人邮箱','内容','时间']
writer.writerow(title)
writer.writerows(data)
if __name__=="__main__":
sobj=login("你的QQ号","你的QQ密码")
out_list = parse(sobj)
save(out_list,"D:\\VSCodeUserSetup-x64-1.60.0\\运行代码\\数据采集\\qq.csv")
上面就是QQ邮箱案例的全部过程。
版权声明:本文为user__s原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。