一、环境准备
接博客的另外两篇文章,虚拟机和mobaxterm已经安装好了。接下来就是配其他的环境了。
(1)打开mobaxterm并连接上虚拟机。
(2)先在根目录下安装一个软件。
(3)根据官方文档来说,先要安装的是java环境。
(4)所以我先创建了一个文件夹(mkdir soft)用来放两个需要的软件。
(5)选择rpm包是因为基本现在已经规范化了,rpm包安装后是直接可以查到官方文档中它建议的这个路径的,tar包比较麻烦。
官方文档:官方文档链接
(6)直接在soft文件夹安装rpm,安装完我们看一下默认的路径。
(7)安装后查看路径正好是官方推荐的路径。这个路径要记好,后面配java解释器要在这里面找。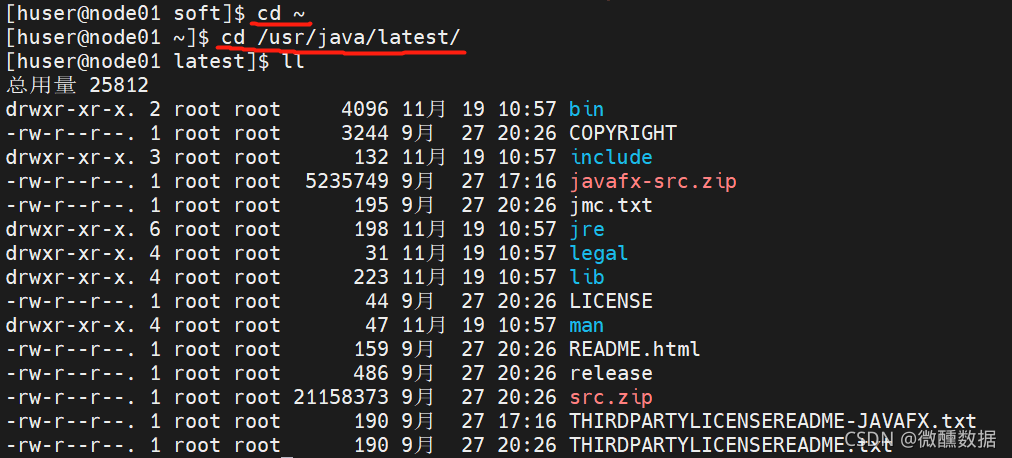
(8)然后我们回到soft文件夹,开始做hadoop的东西,一般都是解压到opt目录下。
(9)因为刚开始我们创建虚拟机的时候是给自己用户的权限,所以我们查看一下权限发现不是root权限。所以我们现在要做的事情就是把hadoop这个文件夹下的所有目录归到我们的huser用户下。
(10)通过下面的命令查看权限已经修改完毕。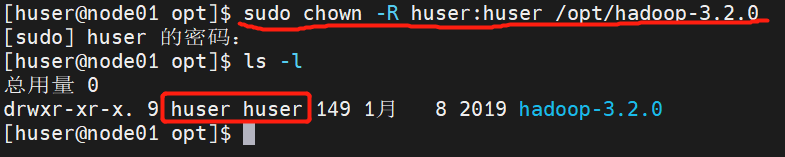
(11)关闭防火墙
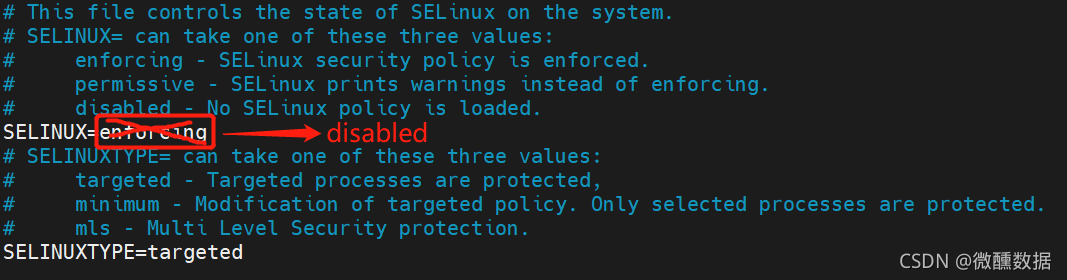
(12)关闭selinux,防止以后传输有问题,修改文件通过下面的命令打开,然后把enforcing更改为disabled。
(13)此时我们进到bin和sbin目录查看一下我们要用到的一些文件。像dfs.sh和yarn.sh都是要用到的。
(14)给hadoop添加环境变量,现在比较主流的方式是在添加文件作为环境变量,以后不用的时候也方便修改。用下面的命令创建文件,然后把上面的两行命令写进去保存退出。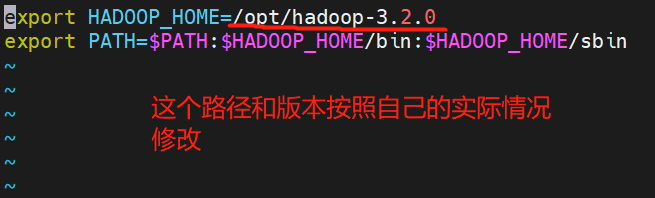
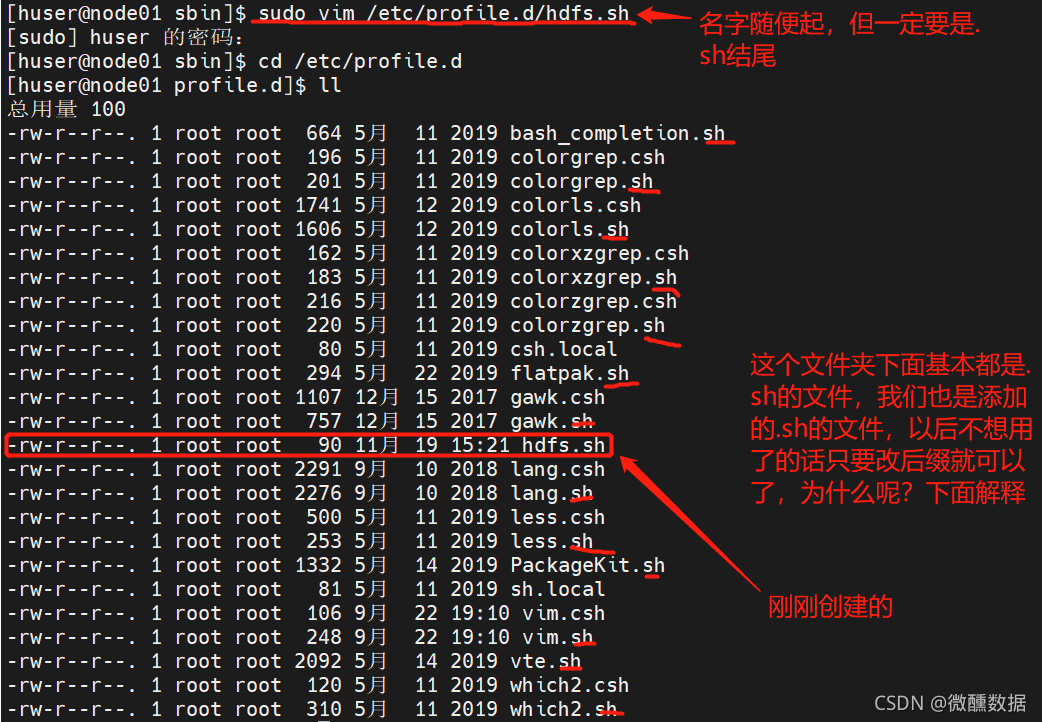
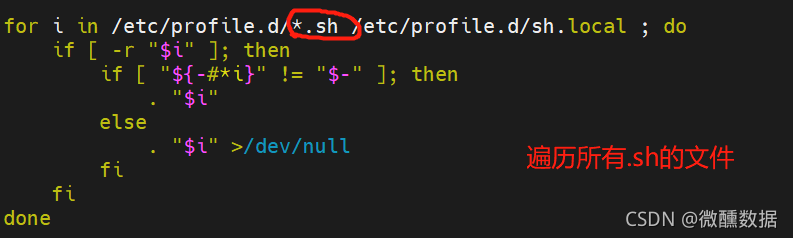
(15)打开如下文件,看到是遍历的所有.sh文件,所以我们通过添加.sh文件来控制环境变量。添加之后source一下,就是执行一下,相当于激活一下,安装环境变量说白了就是告诉你的计算机去哪里找你的执行文件。

(16)创建HDFS的NN和DN工作主目录:
sudo mkdir /var/big_data
因为是root权限创建的,所以要更改一下使用权限给huser用户。
sudo chown -R huser:huser /var/big_data
二、hadoop系统配置
(1)配置文件的位置:在hadoop解压文件下,进到hadoop的etc文件夹,再进到etc下的hadoop文件夹。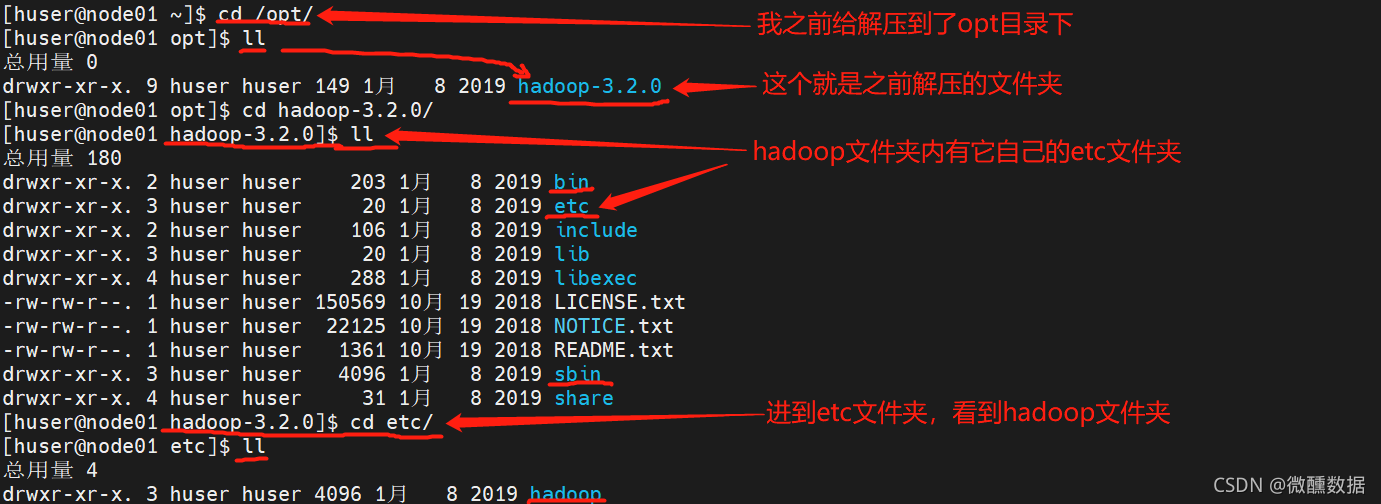
发现有大量的.xml文件和.sh文件,.xml就是键值对的配置,比如上传的副本数是多少,namenode是谁。.sh文件基本都是shell脚本去配javahome的,而shell都是去找java解释器的。而真正去配置HDFS工作的都是.xml文件。
(2)hadoop-env.sh是一定要配置的,因为sh登录到另外一台机器的时候,本地的环境变量是不会继承过去的,所以我们要让hadoop单独的知道解释器到底在哪里。
所以先配置一下hadoop-env.sh和yarn-env.sh
hadoop-env.sh加:export JAVA_HOME=/usr/java/default
yarn-env.sh加:export JAVA_HOME=/usr/java/default
(2).sh修改完了,我们修改下.xml文件,首先是core-site.xml,下面是官方文档的举例。把图中蓝色的部分粘贴过去之后,因为官方文档给的是本地一台机器,所以他写localhost没问题,但是我要配置三台而且都提前规划了名字,所以改为自己设置的名字。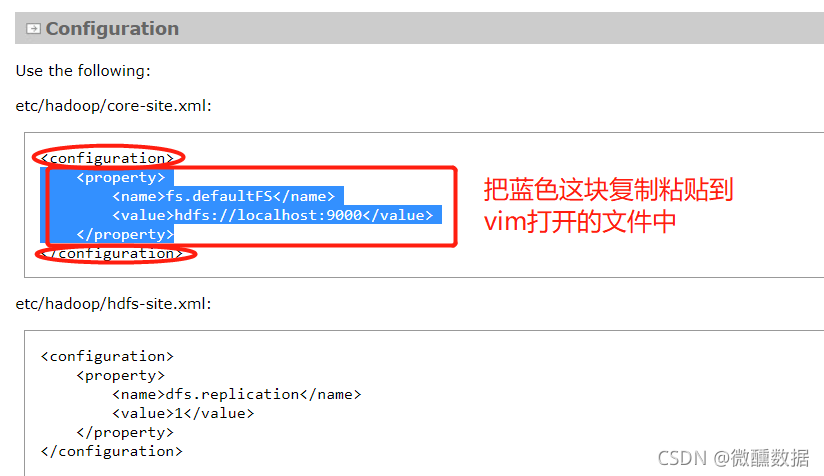
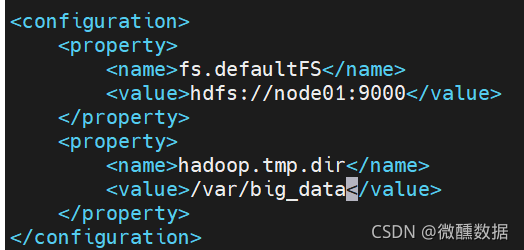
(3)然后配置HDFS核心。打开时候也是没有东西,没关系,看下官方手册。
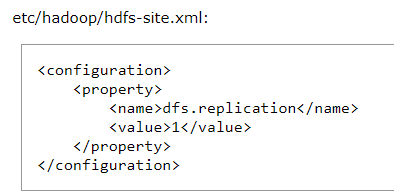
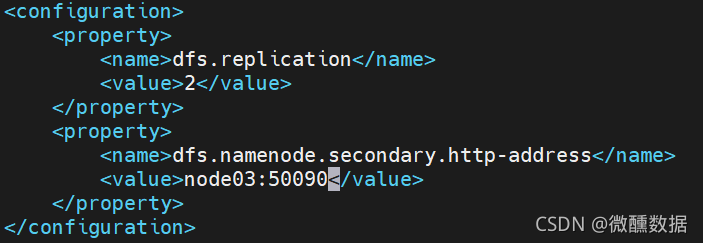
(4)然后是maped的。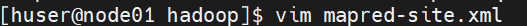
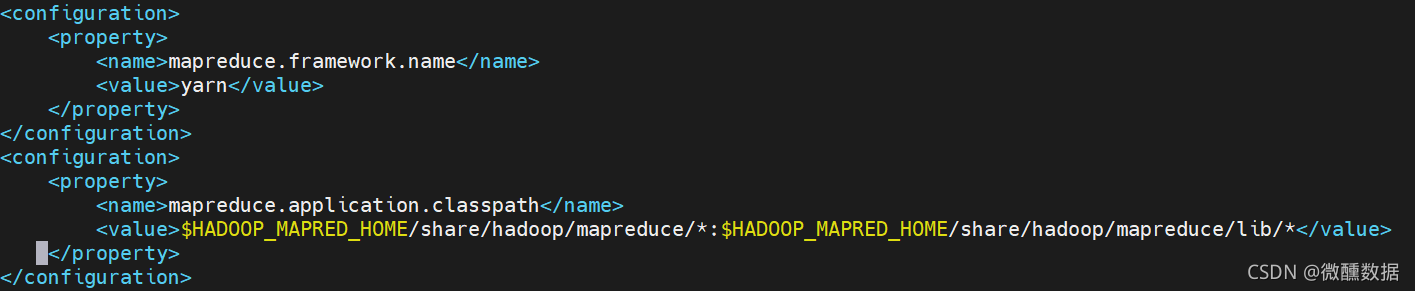
(5)配置yarn的。
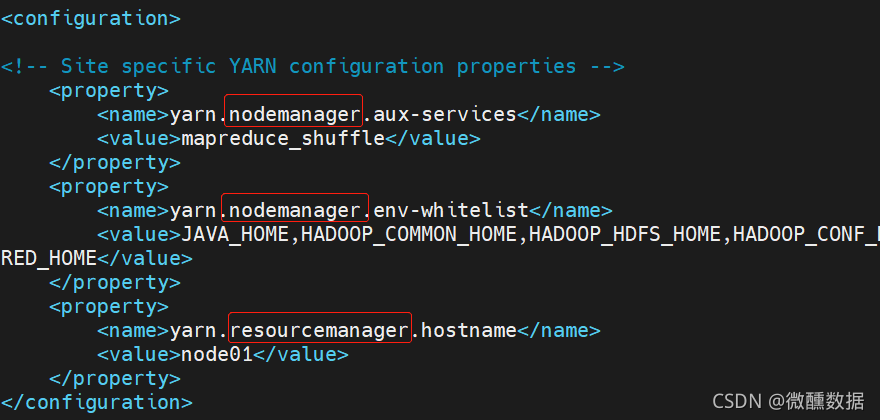
(6)然后配置数据存在哪里。前面的版本是有个slaves的文件夹,3.2.0版本变成了workers。。
打开slaves还是workers都是下面这张图。但是localhost是不对的,要修改为我们自己的。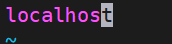
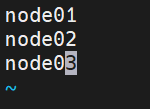
到此为止配置基本都完事了。
(7)添加提前设置的IP。


(8)开始克隆。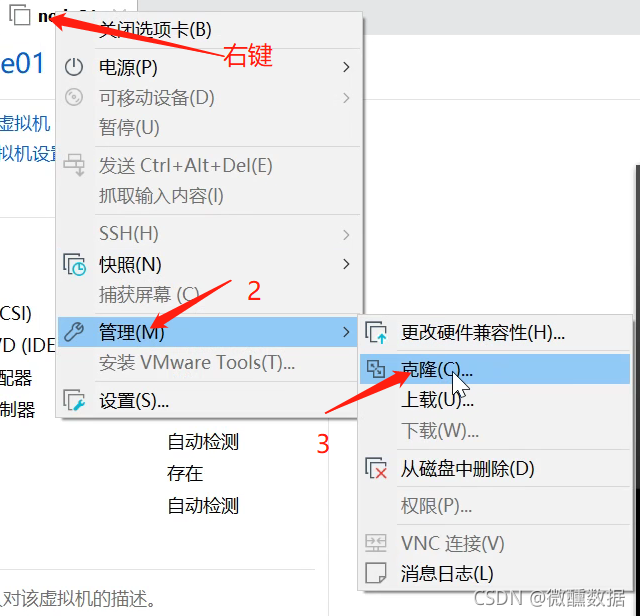
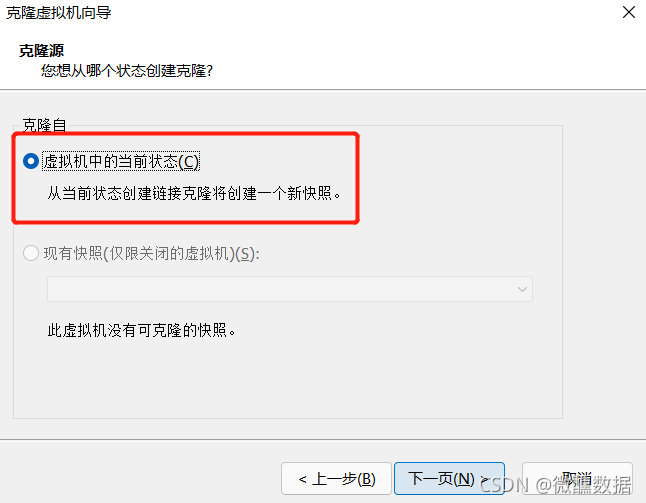
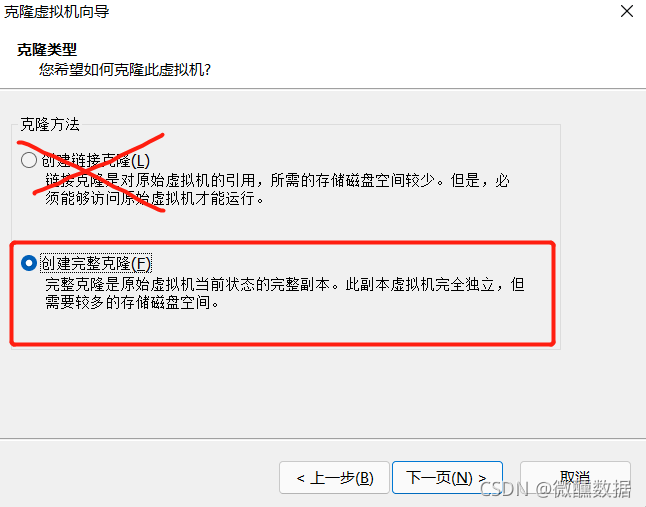
再克隆一台03
(9)因为是完整克隆,所以主机名和IP都要修改。一台一台改,先开启node02。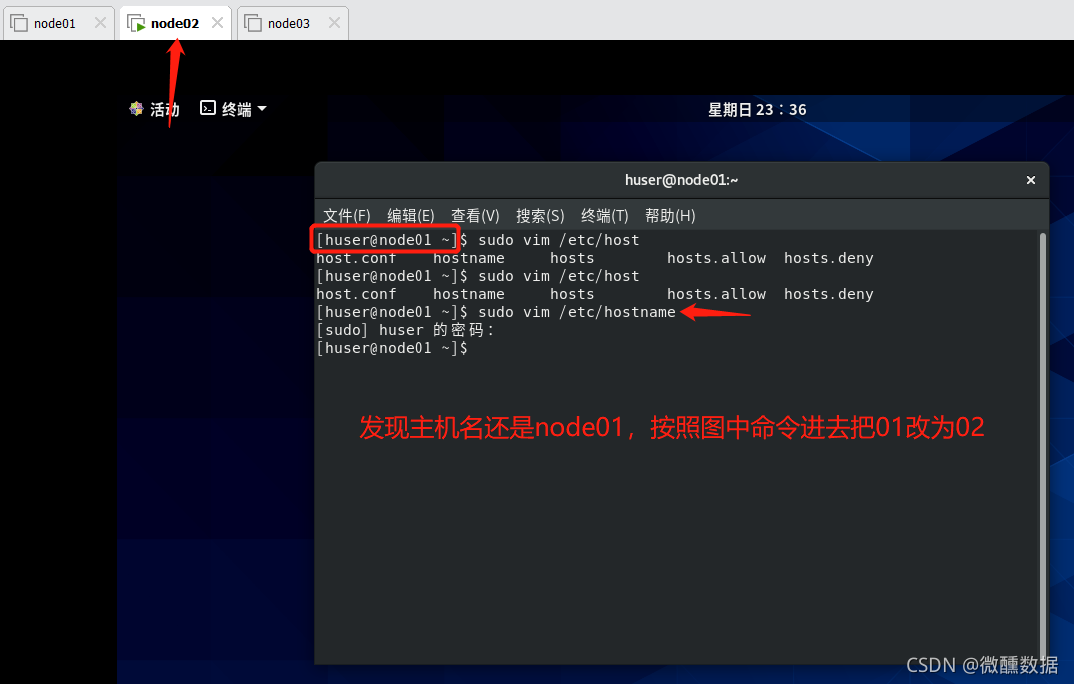
现在改IP,按照下面命令进去修改。
然后重启
重启之后登录查看一下,已经修改好了。第三台机器,如法炮制。
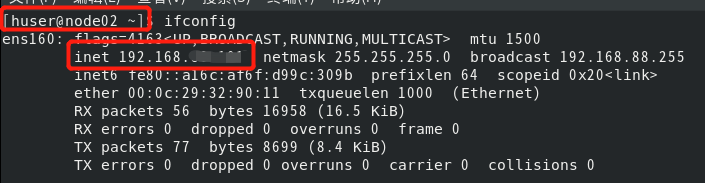
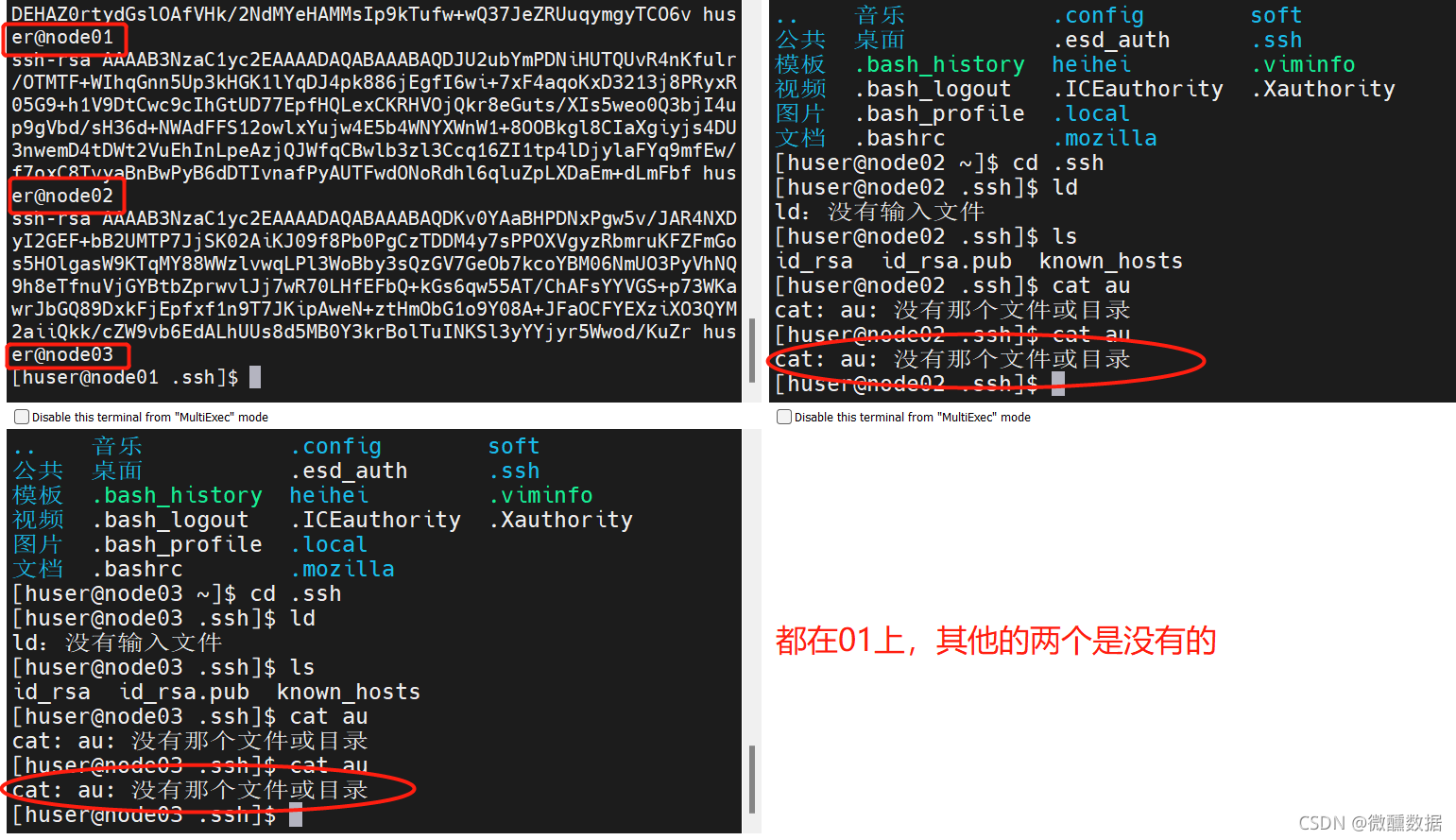
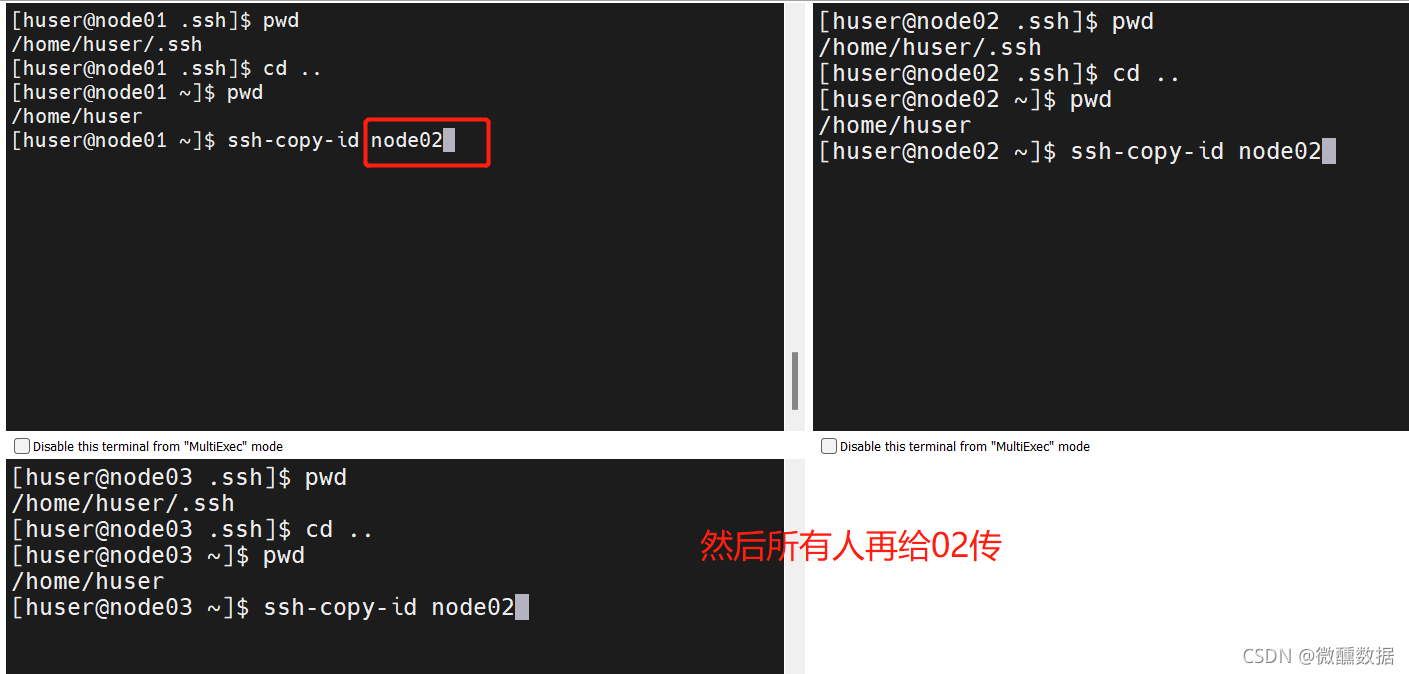
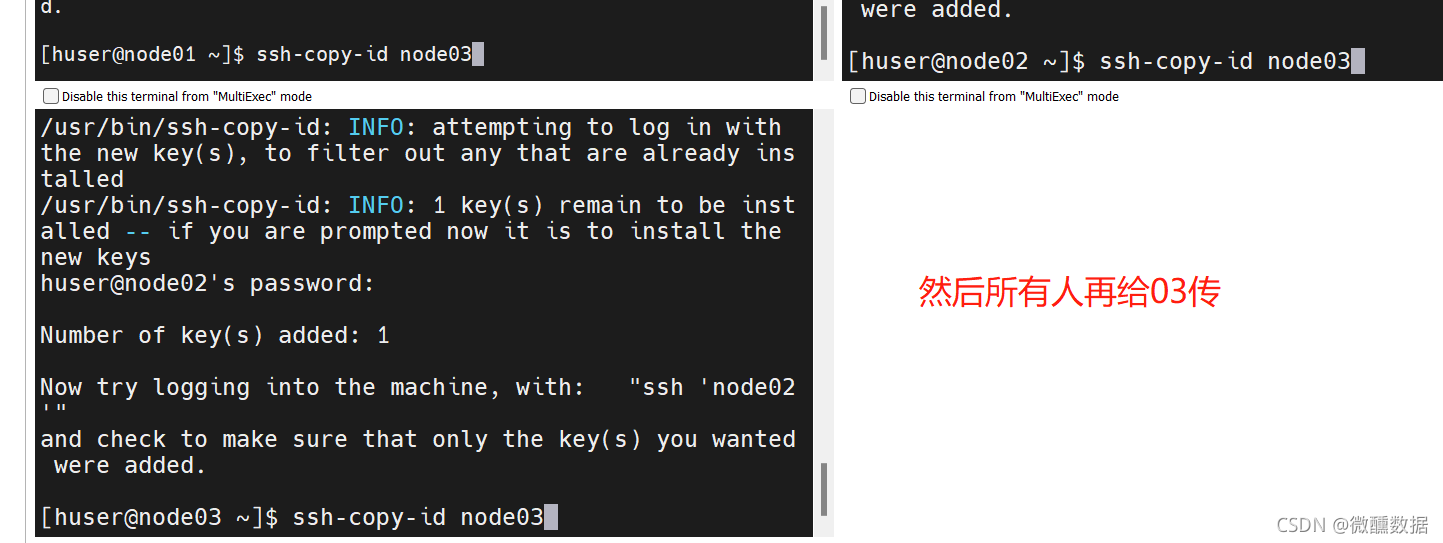
(10)设置免密。在mobaxterm中点击多窗口执行。这样在一个窗口敲命令,三个同时进行。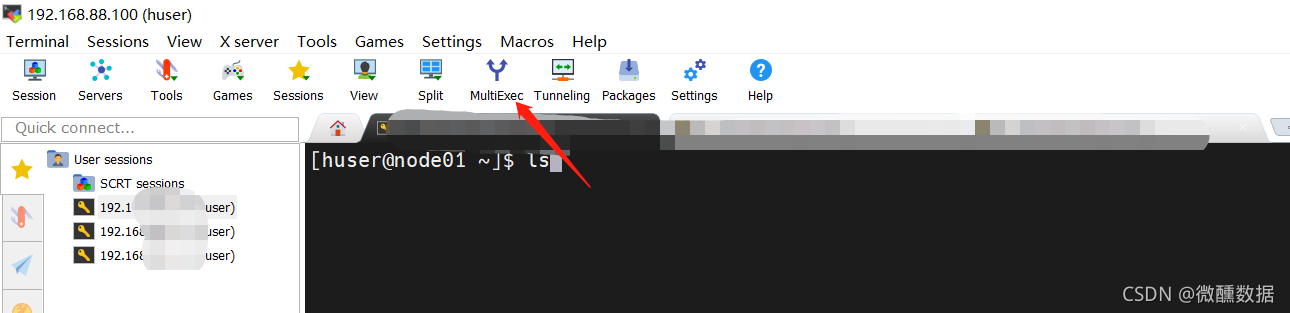
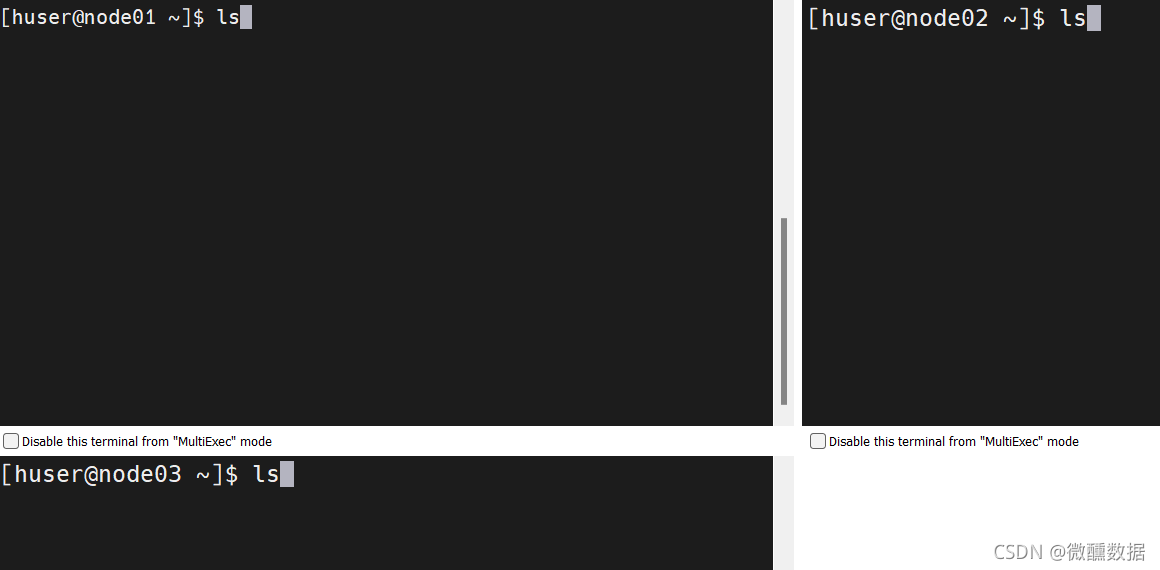
想要免密,首先设置公钥。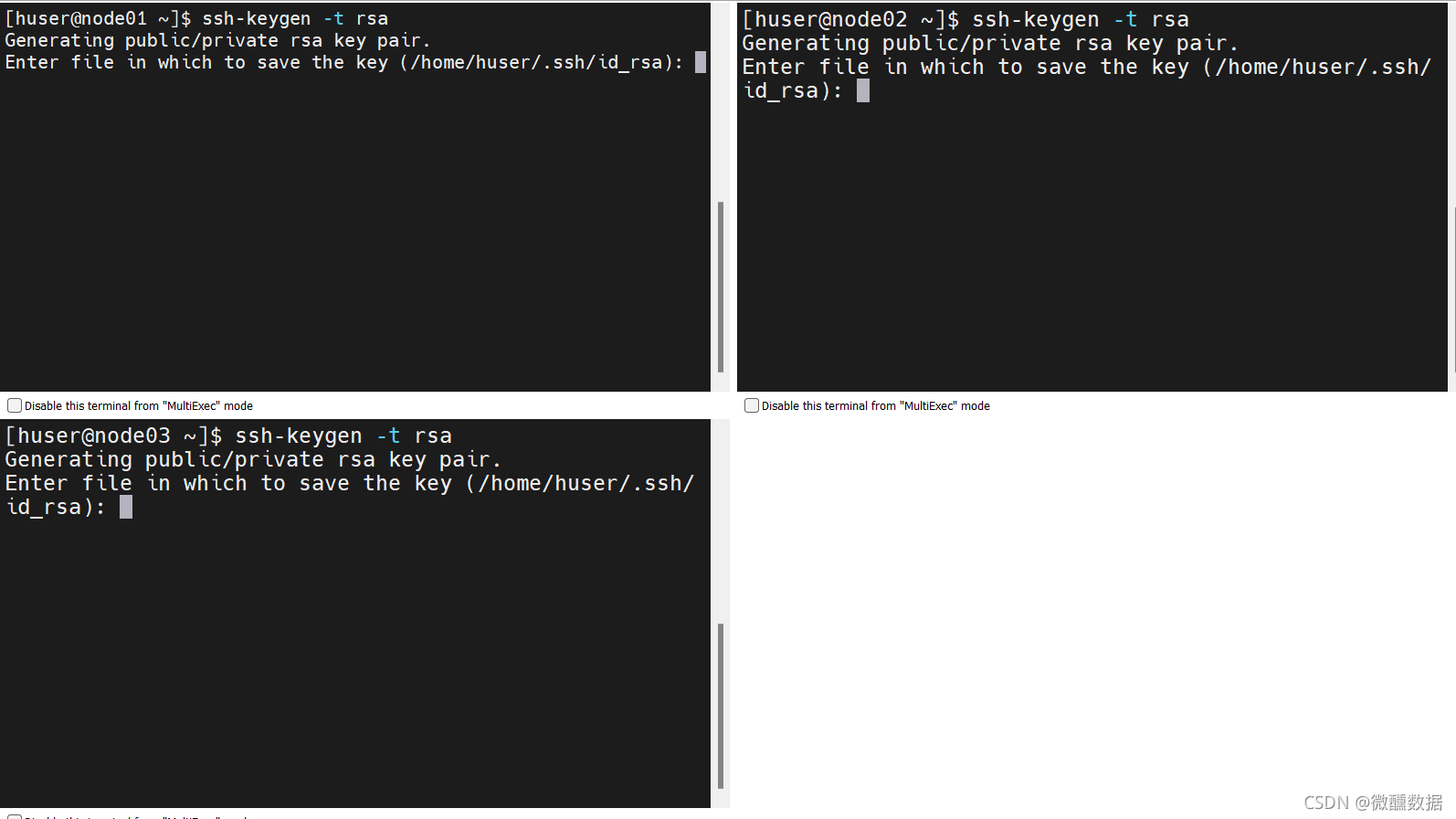
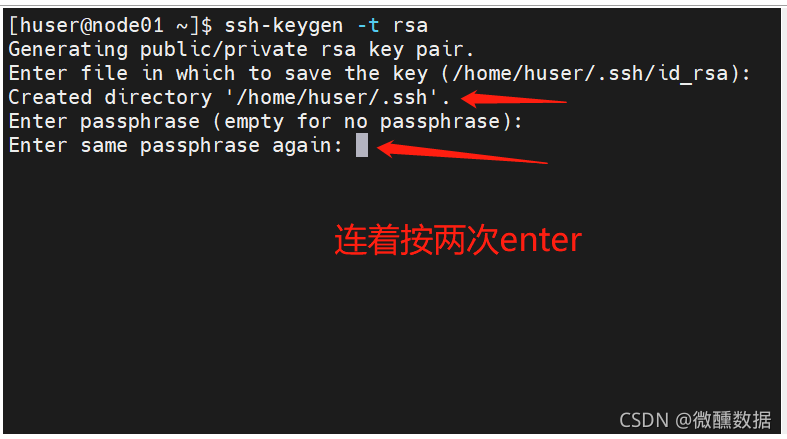
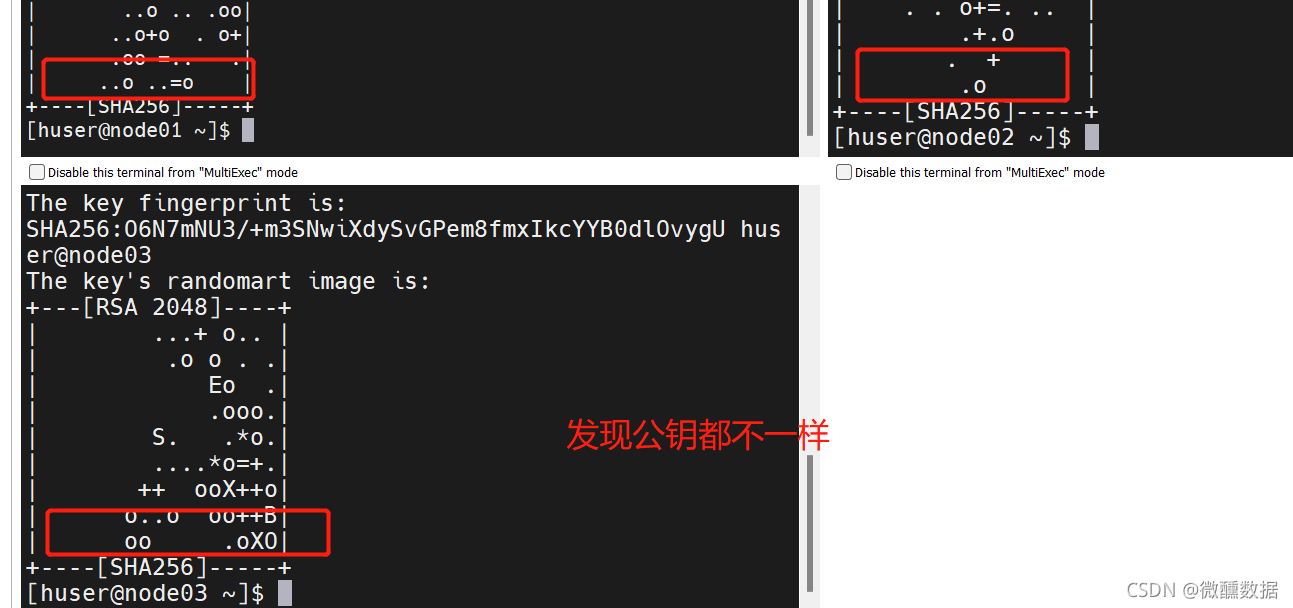
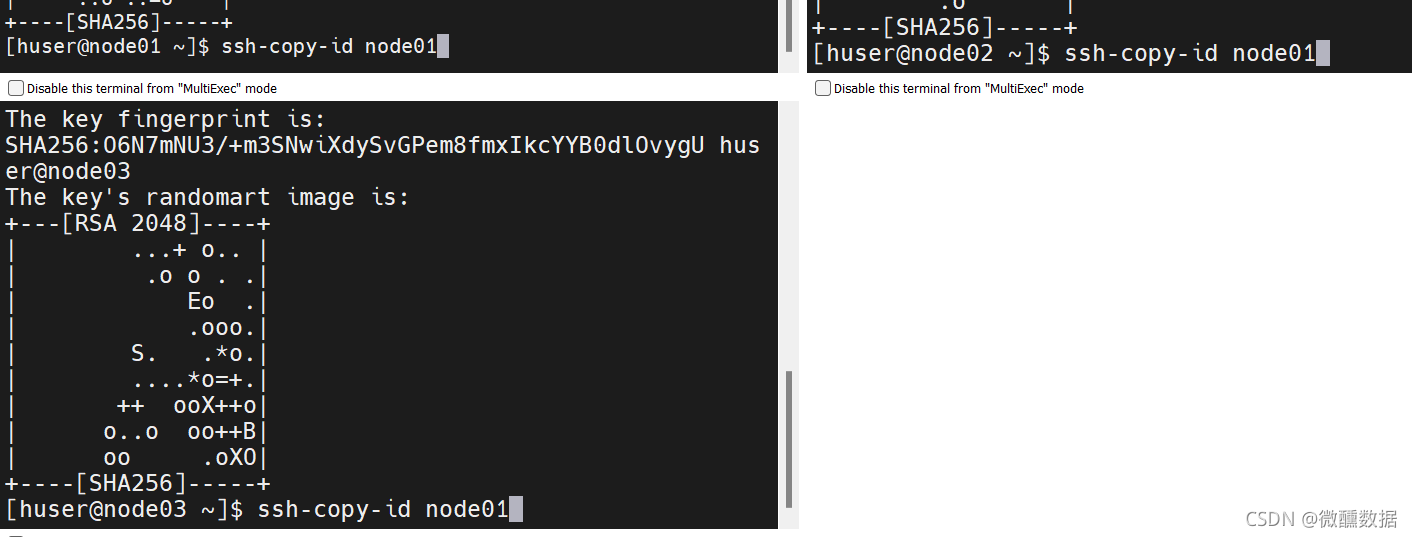
然后会问你yes不yes,那肯定是yes啊,然后再输入一下密码。然后发现都自动生成了.ssh。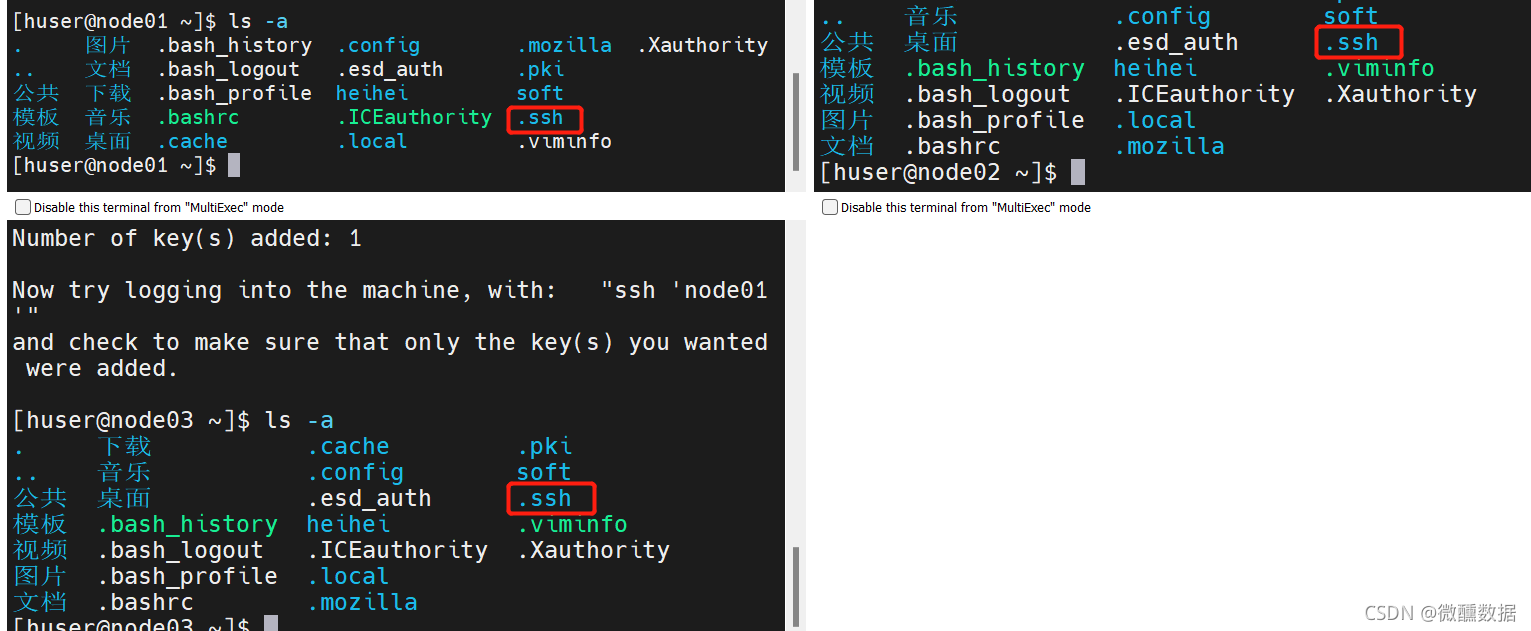
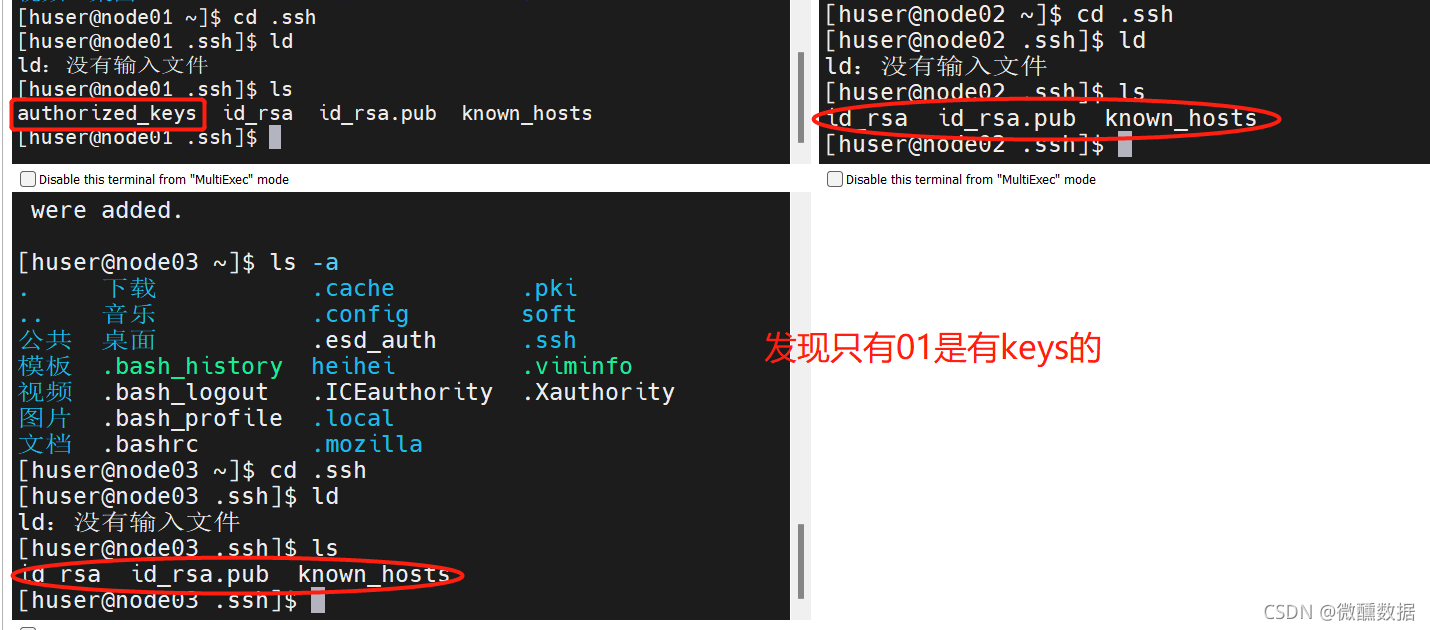
然后退出多窗口执行,在01上试着练一下02和03。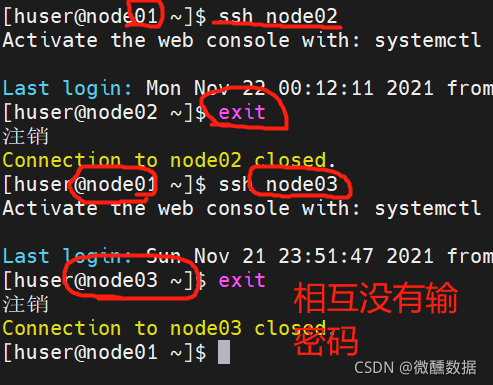
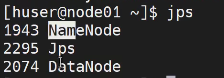
(11)然后格式化hdfs。然后输入下面的命令,image出现代表成功了。