抖音的用户信息页的网址有3种形式,分别是:
https://v.douyin.com/GW5S6D/
https://www.iesdouyin.com/share/user/88445518961?sec_uid=MS4wLjABAAAAWxLpO0Q437qGFpnEKBIIaU5-xOj2yAhH3MNJi-AUY04×tamp=1582709424&utm_source=copy&utm_campaign=client_share&utm_medium=android&share_app_name=douyin
https://www.douyin.com/share/user/88445518961
链接1是从客户端分享的短链接,在浏览器地址栏输入后重定向至链接2的形式。链接2和链接3很明显地把用户的UID显示出来,这个用户的UID为88445518961。
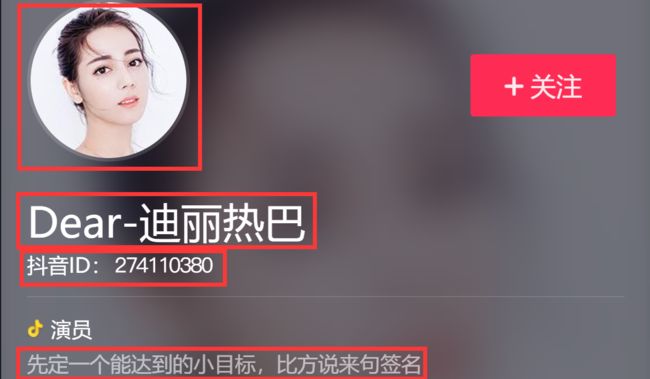
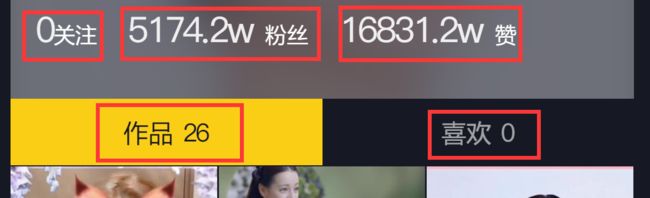
目标:抓取用户名、保存用户头像、UID、抖音ID、签名、关注数、粉丝数、赞数、作品数、喜欢数
0. 获取HTML
使用requests获得响应并利用BeautifulSoup来查找目标值,代码如下
import requests
from bs4 import BeautifulSoup as bs
def getHtml(url):
header = {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60"}
#try: 不必处理异常
response = requests.get(url=url, headers=header)
return bs(response.text, 'lxml') # lxml需要安装,可以选用html.parser
#except: 不必处理异常
# print('网址错误')
# quit()
url = 'https://www.iesdouyin.com/share/user/88445518961?sec_uid=MS4wLjABAAAAWxLpO0Q437qGFpnEKBIIaU5-xOj2yAhH3MNJi-AUY04×tamp=1582709424&utm_source=copy&utm_campaign=client_share&utm_medium=android&share_app_name=douyin'
soup = getHtml(url)
1. 抓取用户名
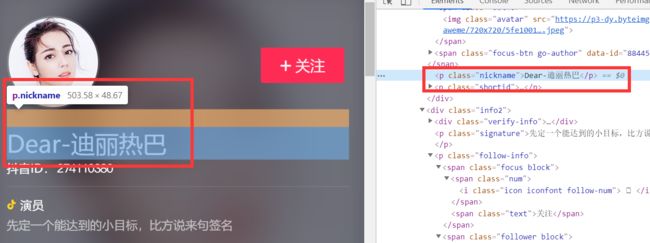
只要查找class="nickname"属性的标签
,标签内的内容即用户名
nickname = soup.find(name='p', attrs={'class': 'nickname'}).string
2. 保存头像
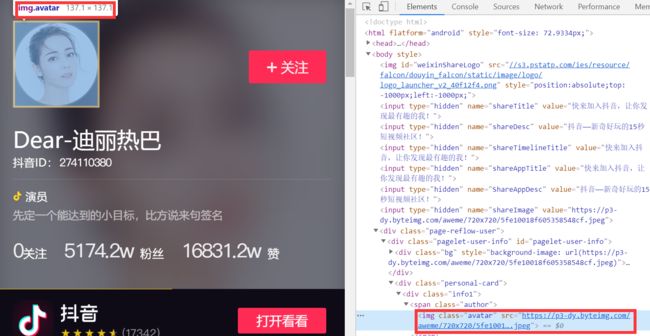
红色框内src的属性值就是头像的下载链接。同样通过find函数查找class="avatar"的标签
里另一属性src的值,下载图像后,文件保存在avatar目录下,文件名为nickname.jpeg。定义一个保存头像的函数
import os
def getAvatar(soup, nickname):
avatarAddr = soup.find(name='img', attrs={'class': 'avatar'})['src']
avatar = requests.get(avatarAddr)
if not os.path.exists('avatar'): # 判断目录是否存在,如果不存在,则创建
os.makedirs('avatar')
try:
with open('.\\avatar\\'+nickname+'.jpeg', 'wb') as img:
img.write(avatar.content)
print('头像保存成功 avatar\\'+nickname+'.jpeg')
except:
print('头像保存失败')
tag[attr]返回的是tag标签内属性为attr的值
3. UID
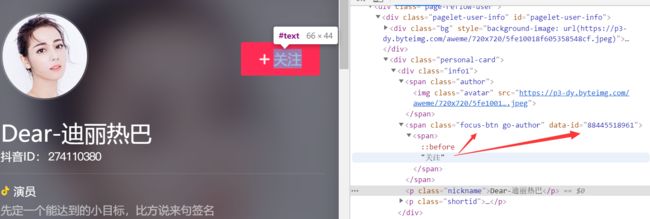
UID的数据在“关注”按钮位置
uid = soup.find(name='span', attrs={'class': 'focus-btn go-author'})['data-id']
4. 抖音ID
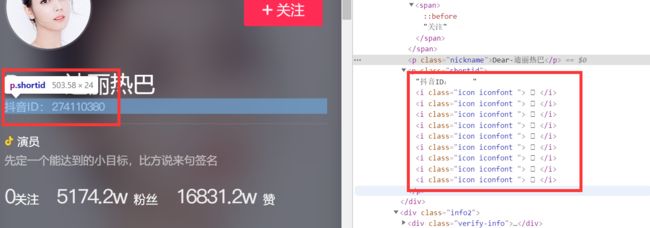
右边红色框内是用户的抖音id。抖音对数字进行一些处理,这是一种反爬虫的应对措施,使我们不能轻易获得数据。每个黑色方框代表一个数字,其实这些数字由特殊的字体控制着,一组Unicode码对应一个数字。
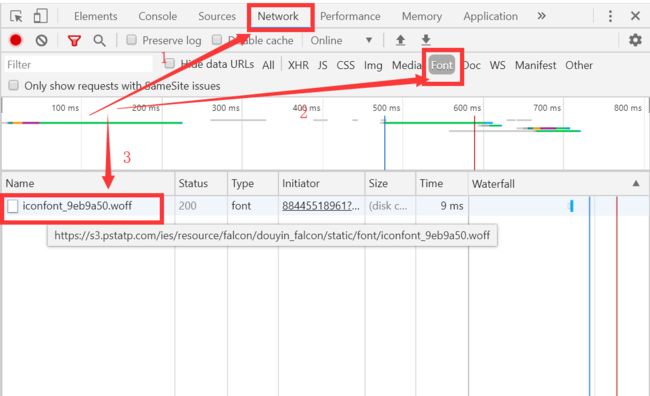
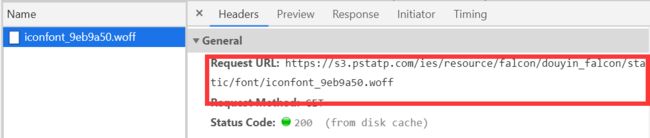
依次选中Network、Font,刷新网页,iconfont_9eb9a50.woff字体文件出现了。选中iconfont_9eb9a50.woff,出现下图的下载链接。把文件下载下来分析数字和Unicode码的映射关系
网上提到百度字体编辑器是一个非常好用的在线编辑器。这个例子里使用font creator查看
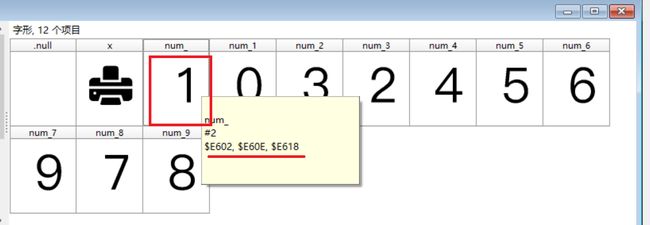
每一个数字由3个十六进制代码编码,具体查看网页源码的时候发现,每一次加载网页一个数字只由四位十六进制代码指定,如下图
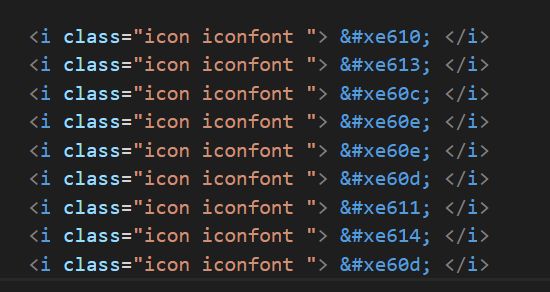
所以只需要找出所有的数字的映射关系就可以轻松地解码数字,利用词典能方便地实现。
codeMap = {
'\ue603': '0', '\ue60d': '0', '\ue616': '0',
'\ue602': '1', '\ue60E': '1', '\ue618': '1',
'\ue605': '2', '\ue610': '2', '\ue617': '2',
'\ue604': '3', '\ue611': '3', '\ue61a': '3',
'\ue606': '4', '\ue60c': '4', '\ue619': '4',
'\ue607': '5', '\ue60f': '5', '\ue61b': '5',
'\ue608': '6', '\ue612': '6', '\ue61f': '6',
'\ue60a': '7', '\ue613': '7', '\ue61c': '7',
'\ue60b': '8', '\ue614': '8', '\ue61d': '8',
'\ue609': '9', '\ue615': '9', '\ue61e': '9'
}
定义一个函数实现把经过“加密”的字符串转化成普通的字符串
def code2commStr(code):
retStr = ''
for c in code:
if c in codeMap:
retStr += codeMap[c]
else:
retStr += c
return retStr
再定义一个函数获得含有这类数字的信息
def getInfo(soup, tag, attr):
element = soup.find(name=tag, attrs={'class': attr})
return code2commStr(element.text.split())
find函数的返回对象的string和text属性有所不同。当find返回的标签含有子标签时,string属性的值为None,text属性的值为纯文本(包含空格)。把Unicode纯文本以空格为间隔分割每一个字符,使用code2commStr函数转化。为了只提取ID而不要其他文字,把shortid以中文冒号(“:”)为分割,只取后半部分。
shortid = getInfo(soup, 'p', 'shortid').split(':')[-1]
5. 签名
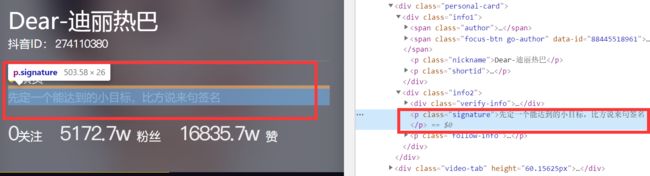
因为签名中的数字没有经过处理,所以直接获得即可。
signature = soup.find(name='p', attrs={'class': 'signature'}).string
6. 关注数、粉丝数、赞数、作品数、喜欢数
这5个数据都含有经过处理的数字,和获得抖音ID的方法相同,利用getInfo函数提取
focus = getInfo(soup, tag='span', attr='focus block')[:-2] # 关注
follower = getInfo(soup, tag='span', attr='follower block')[:-2] # 粉丝
likedNum = getInfo(soup, tag='span', attr='liked-num block')[:-1] # 赞
work = getInfo(soup, tag='div', attr='user-tab active tab get-list')[2:] # 作品
like = getInfo(soup, tag='div', attr='like-tab tab get-list')[2:] # 喜欢
为了提取数字本身,丢掉前(后)几个字符(“关注”、“粉丝”、“赞”、“作品”、“喜欢”)。
至此,利用Python爬取抖音分享页用户信息的代码基本完成,但是在测试过程中发现一个错误。

出现这个错误的位置是签名,原因是一些用户的个性签名很有个性,带有特殊符号,Tk不支持显示这种符号。
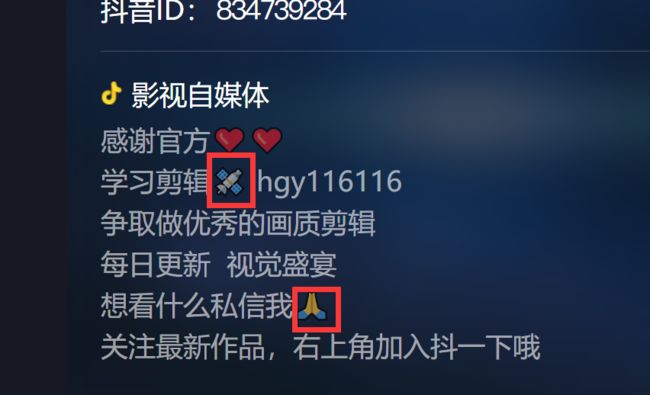
一个不完美的方法是不管该符号,保留其他符号显示。 将用户名和签名等可能含有特殊符号的信息进行修改
import sys
nonBmpMap = dict.fromkeys(range(0x10000, sys.maxunicode + 1), 0xfffd)
nickname = soup.find(name='p', attrs={'class': 'nickname'}).string.translate(nonBmpMap)
signature = soup.find(name='p', attrs={'class': 'signature'}).string.translate(nonBmpMap)
完整代码如下:
import requests
from bs4 import BeautifulSoup as bs
import os
import sys
codeMap = {
'\ue603': '0', '\ue60d': '0', '\ue616': '0',
'\ue602': '1', '\ue60E': '1', '\ue618': '1',
'\ue605': '2', '\ue610': '2', '\ue617': '2',
'\ue604': '3', '\ue611': '3', '\ue61a': '3',
'\ue606': '4', '\ue60c': '4', '\ue619': '4',
'\ue607': '5', '\ue60f': '5', '\ue61b': '5',
'\ue608': '6', '\ue612': '6', '\ue61f': '6',
'\ue60a': '7', '\ue613': '7', '\ue61c': '7',
'\ue60b': '8', '\ue614': '8', '\ue61d': '8',
'\ue609': '9', '\ue615': '9', '\ue61e': '9'
}
def code2commStr(code):
retStr = ''
for c in code:
if c in codeMap:
retStr += codeMap[c]
else:
retStr += c
return retStr
def getHtml(url):
header = {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60"}
#try: 不必处理异常
response = requests.get(url=url, headers=header)
return bs(response.text, 'lxml') # lxml需要安装,可以选用html.parser
#except:
# print('网址错误')
# quit()
def getAvatar(soup, nickname):
avatarAddr = soup.find(name='img', attrs={'class': 'avatar'})['src']
avatar = requests.get(avatarAddr)
if not os.path.exists('avatar'):
os.makedirs('avatar')
try:
with open('.\\avatar\\'+nickname+'.jpeg', 'wb') as img:
img.write(avatar.content)
print('头像保存成功 avatar\\'+nickname+'.jpeg')
except:
print('保存头像失败')
def getInfo(soup, tag, attr):
element = soup.find(name=tag, attrs={'class': attr})
return code2commStr(element.text.split())
url = 'https://www.iesdouyin.com/share/user/88445518961?sec_uid=MS4wLjABAAAAWxLpO0Q437qGFpnEKBIIaU5-xOj2yAhH3MNJi-AUY04×tamp=1582709424&utm_source=copy&utm_campaign=client_share&utm_medium=android&share_app_name=douyin'
soup = getHtml(url)
nonBmpMap = dict.fromkeys(range(0x10000, sys.maxunicode + 1), 0xfffd)
nickname = soup.find(name='p', attrs={'class': 'nickname'}).string.translate(nonBmpMap)
getAvatar(soup, nickname)
shortid = getInfo(soup, 'p', 'shortid')
uid = soup.find(name='span', attrs={'class': 'focus-btn go-author'})['data-id']
signature = soup.find(name='p', attrs={'class': 'signature'}).string.translate(nonBmpMap)
focus = getInfo(soup, tag='span', attr='focus block')[:-2]
follower = getInfo(soup, tag='span', attr='follower block')[:-2]
likedNum = getInfo(soup, tag='span', attr='liked-num block')[:-1]
work = getInfo(soup, tag='div', attr='user-tab active tab get-list')[2:]
like = getInfo(soup, tag='div', attr='like-tab tab get-list')[2:]
print('用户名:', nickname)
print('抖音ID:', shortid)
print('UID:', uid)
print('签名:', signature)
print('关注数:', focus)
print('粉丝数:', follower)
print('赞数:', likedNum)
print('作品:', work)
print('喜欢:', like)
结果
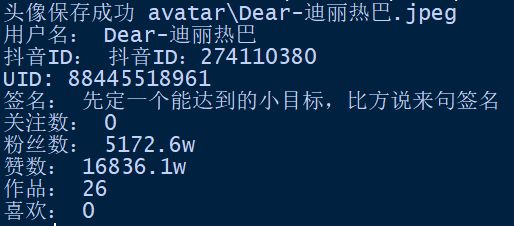
不过,这个程序意义不大,除非可以高效获得大量用户UID,或者只是为了提取几个用户的数据变化。