1.跨平台
一般对于不同平台需要写不同的程序代码,但 java 只需要安装与平台相对应的java虚拟机,然后就可以写一套一样的代码
2. JDK和JRE的区别:
jre是运行时环境,它包括java虚拟机(JVM负责将字节码转换为特定机器代码,内存管理和垃圾回收)和类库,JDK在JRE的基础之上还包括编译器这些。
如果只需要运行安装jre就行,如果需要编写java程序,则需要安装JDK。
3. == 和 equals 的区别是什么?
==比较的是内存地址,equals是Object中的方法,他需要我们自己重写覆盖,在Object中他比较的也是内存地址,在String中他比较的是字符内容,所以说得看具体内容
4. 两个对象的 hashCode()相同,则 equals()也一定为 true,对吗?
不一定相同。
hashCode值相等,两个对象不一定相等,hashCode值不等,两个对象一定不相等。
比较相等用equals,比较不相等用hashCode
Hashcode值不是内存地址,不同的内存地址对应不同的Hashcode值,Hashcode值是用内存地址通过一定的算法得到的
5. java 中的 Math.round(-1.5) 等于多少?
Math.floor(),向下取整
Math.round(),四舍五入
Math.ceil(),向上取整
6. java面向对象四大特征
抽象:就是将一些事物的共同之处归为一个类
封装:是将一类事物的属性和行为抽象成一个类,一般是使其属性私有化,行为公开化,提高了数据的隐秘性的同时,使代码模块化
- 信息隐藏,提高安全性
- 类与类之间比较独立,低耦合,高内聚,解耦
- 提高了代码复用率
继承:基于已有的类的定义为基础,构建新的类,已有的类称为父类,新构建的类称为子类
- 提高了代码复用率
- 可扩展性,即对父类方法不是很满意,可以对其进行父类方法进行重写
多态:方法的重写、重载与动态连接构成多态性。简单来说,多态就是允许父类引用(或接口)指向子类(或实现类)对象
实现多态,有二种方式,覆盖(override),重载(overload)。
- 不同场景可做出不同的动作,动态调用
- 解耦
- 可扩展性
7. 内部类
成员内部类,局部内部类不能有静态声明,静态内部类可以
局部内部类访问局部变量必须加final(生命周期会存在冲突,局部变量在局部内部类内中是成员变量,局部变量生命周期比成员变量的要短),
调用局部内部类的方法:因为局部内部类定义在方法里,不能实例化局部内部类,只能在局部方法里实例化并调用局部内部类的方法。
匿名内部类new 接口名(){} //可以想象成new一个接口,{}后是接口的实现
8. String、StringBuilder和StringBuffer的区别
–String是内容不可变的字符串,StringBuilder和StringBuffer内容可变
–StringBuilder是线程不安全的,但效率高,而StringBuffer线程安全,但效率低
–拼接字符串不能用String,因为会创建很多的对象
9. 什么是死锁?
是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象
10. 造成死锁的四个条件
(1) 互斥条件:一个资源每次只能被一个进程使用。
(2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3) 不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
(4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
11. yield, sleep和wait区别
yield会临时暂停当前正在执行的线程,来让有同样优先级的正在等待的线程有机会执行,放弃自己的CPU资源,重新进入就绪状态;
sleep仅仅让你的线程进入睡眠状态,进入阻塞状态
wait只能在同步环境中被调用,会释放对象锁,当某个条件为真时会继续执行程序;
notify:唤醒等待队列中随机的一个线程
notifyAll:唤醒等待队列中的所有线程
12. 序列化与反序列化
序列化和反序列化。序列化是这个过程的第一部分,将数据分解成字节流,以便存储在文件中或在网络上传输。
反序列化就是打开字节流并重构对象。
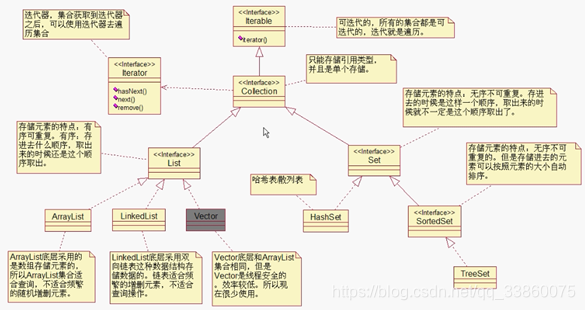
13. 集合不能存基本数据类型,只能存引用类型
- Collection
- Map
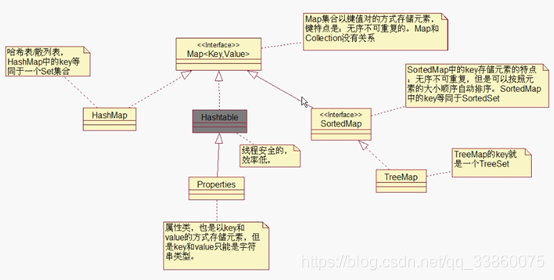
Ø 哈希表/散列表
HashMap底层是一个哈希表,哈希表实际上是一个数组,而数组中每个元素又是一个单链表,链表中每个节点包含四个内容,Object key,Object value,
final int hash,Entry next;其中由key通过hashCode()算出的Hash值,等同于数组的下标,next是指向下一个节点。
get(Object key):先把key通过hashCode()算出hash值,得到对应的下标,然后在单链表中找到对应key的value返回
put(Object key,Object value): 先把key通过hashCode()算出hash值,如果哈希表中没用相同的hash值则添加,否则调用equals方法,比较是否有相同的key,如果有则放弃添加该元素,如果没有则添加。
14. ArrayList和LinkedList区别?
--ArrayList是数组,查询快,插入和删除慢
--LinkedList是双向链表,查询慢,插入和删除快
ArrayList用在查询多,插入、删除少的情况;而LinkedList用在插入、删除多,查询少的情况
15.抽象类与接口的区别?
实现:实现的关键字不同,抽象类是extends,接口是implement
16. HashMap和HashTable的区别?
--HashMap的key和value可以是null,hashTable不能
--HashMap是线程不安全,但效率高;HashTable是线程安全的,但效率低
--ConcurrentHashMap可以实现线程安全,效率高
将Map分成N个Segment(类似HashTable),可以提供相同的线程安全,效率提高N倍,默认是16倍
17. HTTP GET POST区别
--GET提交的数据会在URL之后显示出来,POST不会
--GET地址长度有限制,所以数据传输有限制,POST不会
--POST的安全性比GET高
18. servlet的生命周期
加载servlet的class–>实例化servlet–>调用servlet的init(初始化)–>调用servlet的service(处理请求)–>调用servlet的destroy方法(服务结束)
19. RESTful风格
Ø 对URL进行规范,url简洁
Ø 对HTTP方法规范,使用get,post,put,delete进行CRUD
Ø 可以对HTTP的contentType规范,即指定数据的格式。
20. 过滤器与Springmvc拦截器区别
Ø 依赖于servlet容器,一次请求只会调用一次
Ø 依赖于web框架,AOP,调用多次,基于反射
如果同时配置了filter和Interceptor,则会先执行filter,然后执行Interceptor
21. 什么是Spring MVC ?简单介绍下你对springMVC的理解?
Spring MVC是一个基于Java的实现了MVC设计模式的请求驱动类型的轻量级Web框架,通过把Model,View,Controller分离,将web层进行职责解耦,把复杂的web应用分成逻辑清晰的几部分,简化开发,减少出错,方便组内开发人员之间的配合。
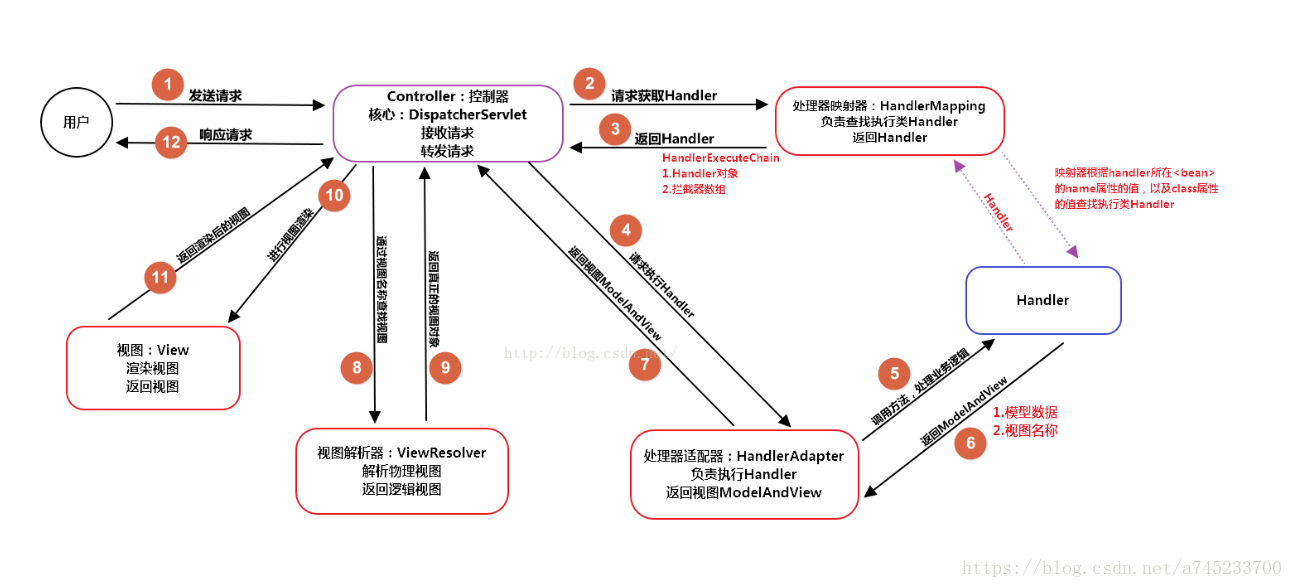
22. SpringMVC的流程?
(1)用户发送请求至前端控制器DispatcherServlet;
(2) DispatcherServlet收到请求后,调用HandlerMapping处理器映射器,请求获取Handle;
(3)处理器映射器根据请求url找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet;
(4)DispatcherServlet 调用 HandlerAdapter处理器适配器;
(5)HandlerAdapter 经过适配调用 具体处理器(Handler,也叫后端控制器);
(6)Handler执行完成返回ModelAndView;
(7)HandlerAdapter将Handler执行结果ModelAndView返回给DispatcherServlet;
(8)DispatcherServlet将ModelAndView传给ViewResolver视图解析器进行解析;
(9)ViewResolver解析后返回具体View;
(10)DispatcherServlet对View进行渲染视图(即将模型数据填充至视图中)
(11)DispatcherServlet响应用户。
-spring常见面试题
-springmvc常见面试题
-mybatis常见面试题
23. JDBC连接
Ø 加载驱动类
Ø 使用DriverManager获取连接
24. 索引类型(type)
System>const>eq_ref>ref>range>index>all(从左到右查询效率依次降低)
l System:查询的表只有一条数据
l Const:仅仅能查到一条数据的SQL,用于Primary Key或unique索引
Ø Eq_ref:唯一性索引,对于每个索引键的查询,返回有且只有一行数据(常见于唯一索引和主键索引);
若为连接查询,则查询的数据要与其对应连接查询的个数要一样
Ø Ref:非唯一性索引
Ø Range:检索指定范围的行,范围查询between…and…,<,>,>=,<=,in(in有时候会失效)
² Index:查询索引中全部数据
² All: 查询表中全部数据
25.设计模式
--单例模式:饱汉模式,饥汉模式
--工厂模式:Spring IOC
–代理模式:Spring AOP
必要条件:被代理类和代理类共同实现某个接口,代理类关联于被代理类
动态代理:首先有一个被代理类实现某个接口,代理类实现 InvocationHandler 接口并关联于被代理类,Proxy.newProxyInstance(ClassLoader loader, Class<?>[] interfaces,InvocationHandler)做代理类与接口关联,
InvocationHandler 的实现类invoke(Object proxy, Method method, Object[] args)做真正的方法调用
26.三大范式
第一范式(1NF):数据库表中的每一列是不可再分割的基本数据项
第二范式(2NF):在1NF的前提下,数据库表中每一列必须可以被区分(用主键进行区分)
第三范式(3NF):在2NF的前提下,数据库表中不能包含其他表中已存在的非主键关键字信息(如果需要,用外键关联)
27.事务(ACID)
原子性:表示事务内的操作不可再分割
一致性:要么都成功,要么都失败
持久性/持续性:表示事务开始了就不能结束
隔离性:一个事务开始后,不能与其他事务干扰
28.单例模式
饿汉模式:线程安全、反射不安全、反序列化不安全
登记式(静态内部类):线程安全、防止反射攻击、反序列化不安全
枚举式:线程安全、支持序列化、反序列化安全、防止反射攻击(不支持反射)
懒汉模式:线程不安全、延迟加载
双检锁:线程安全、volatile
29.Exception和Error

exception:可预见的,可以捕获的
error:不可预见的,不需要捕获的
30.String

31.HashMap和hashTable

32.&和&&
都是进行与运算
&(按位与):没有短路功能
&&(逻辑与):有短路功能

33.栈和堆的区别

34.接口和抽象类
接口特点:

接口成员特点:

抽象类特点:

抽象类成员特点:

接口和抽象类区别:
35.cookie和session的区别
cookie:

cookie被禁止使用时,将sessionid放在URL里带回
session

区别:
cookie是session用来跟踪用户的,cookie会保存一个sessionid,用来识别session
cookie保存在客户端,保存用户信息的
session保存在服务端,用来维持与用户会话的
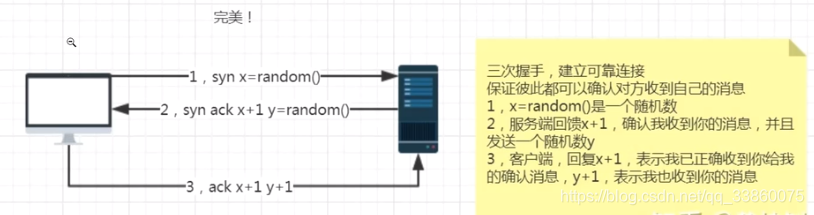
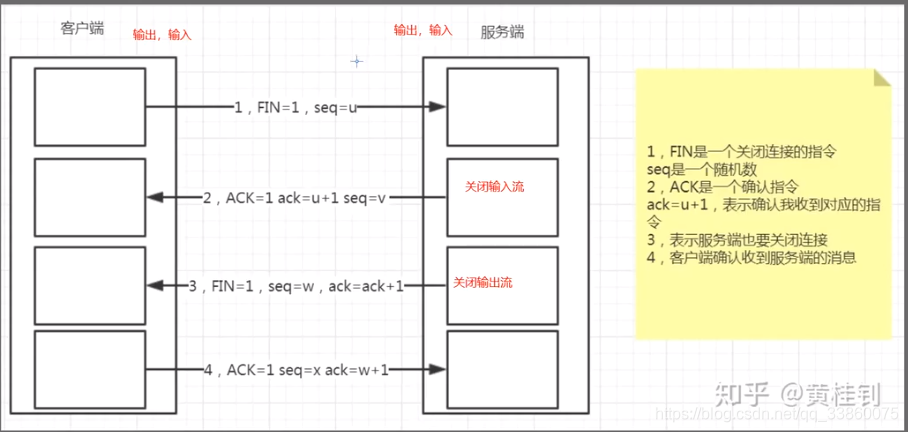
36.TCP三次握手和四次挥手
三次握手
客户端a和服务端b,a给b发一个数字X,b收到后,将X加1,发回,表示确认,再发送另一个数字y过去,a收到后将y加1,然后在发回确认
四次挥手
第一次:a表示想释放连接
第二次:b收到后确认,关闭输入流,这个时候是能发,不能收
第三次:b再次发送,表示自己关闭输出流,既不能发也不能收
第四次:a确认,然后自己再释放
37.jsp和servlet的区别
jsp的本质就是一个servlet,servlet
38.mybatis的一级缓存和二级缓存
一级缓存是当同一条sql第二次执行的时候会从缓存(用的是HashMap作为缓存工具)中获取数据,它的作用域是在同一个sqlsession中,这样可以提高效率,当sqlsession关闭和进行增删改操作的时候会清楚缓存,进行增删改的时候清楚是为了避免脏读。
如果出现同一条sql在不同的sqlsession中的话,这个时候就用到了二级缓存,它的作用域是在mapper.xml的namespace里面,它也是用HashMap作为缓存工具的
39.jdbc常见面试题
40.二叉树的三种遍历方式

思维:以根节点、左子树和右子树作为最小单元遍历
记忆:左右子树顺序不变,看根节点顺序
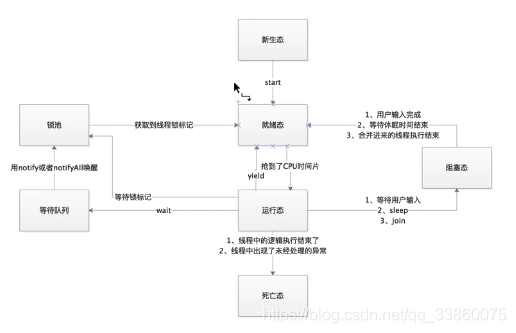
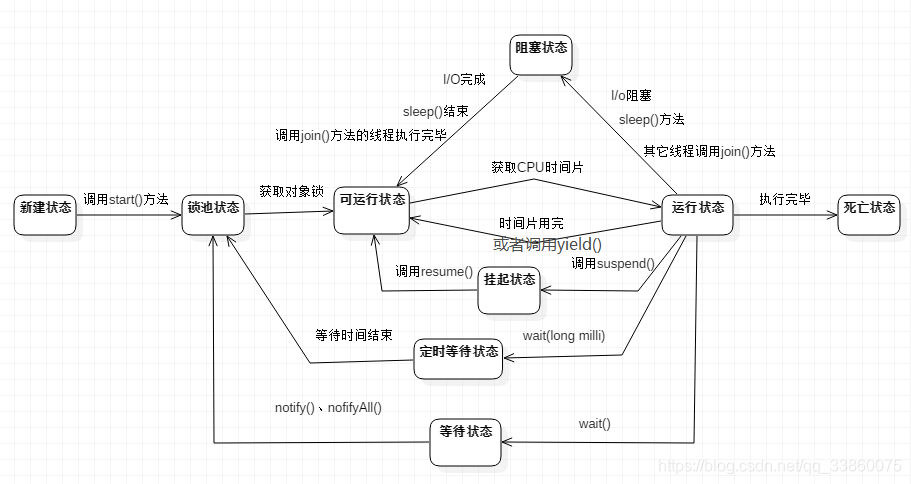
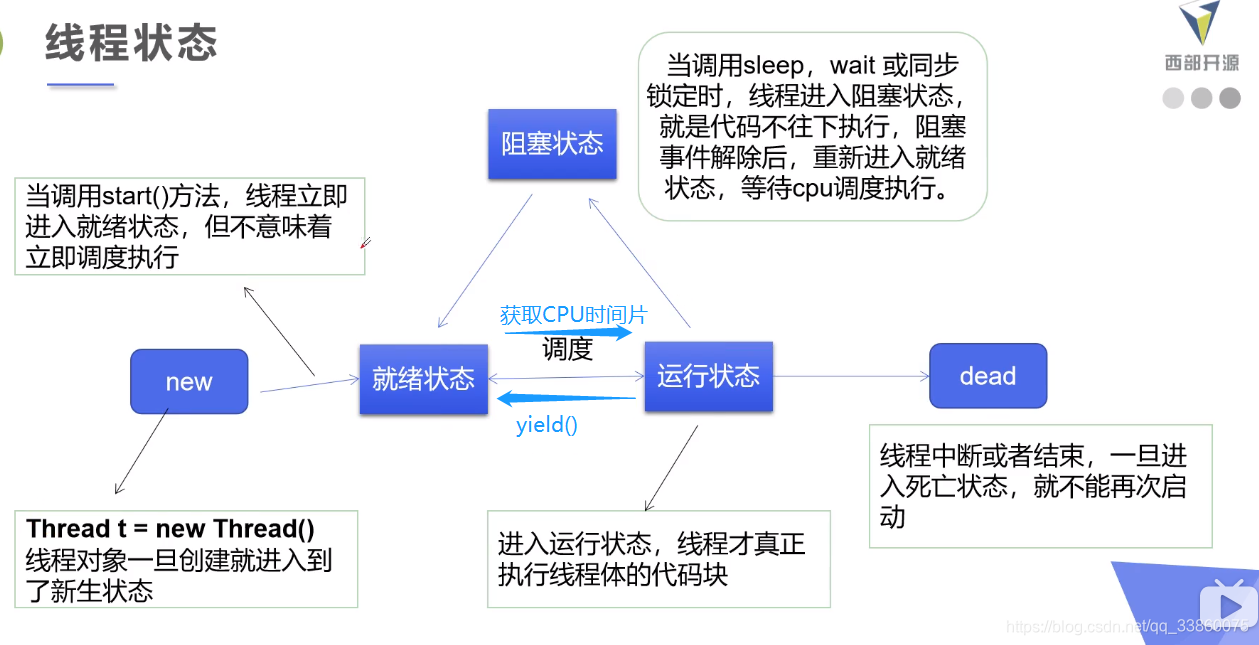
41.线程状态
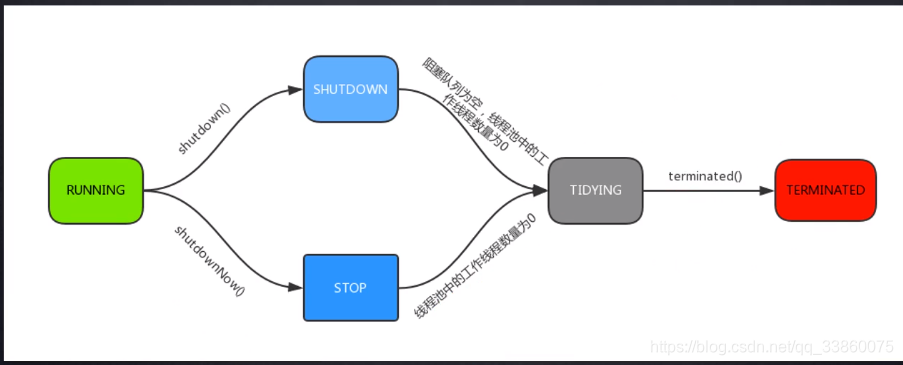
42.线程池的状态

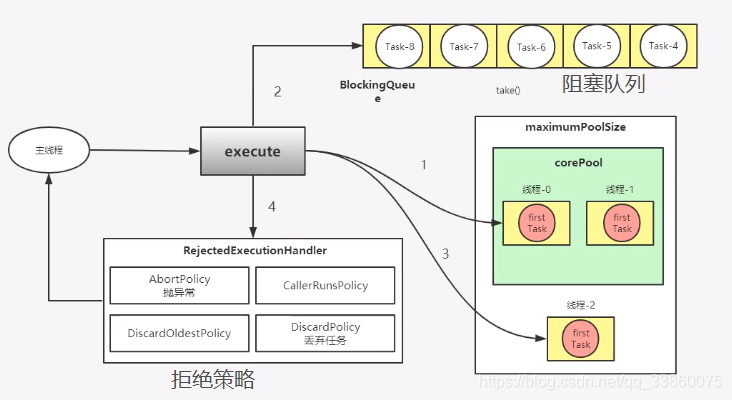
43.线程池的执行原理
44.分布式的条件
- 一个方法在同一时间只能被一个机器的一个线程执行;
- 获取锁和释放锁的性能要好
- 具备所失效机制:网络中断或宕机无法释放锁时,锁必须被清除,不然会发生死锁
- 锁具备可重入性:比如一个线程在执行一个带锁的方法,该方法中又调用了另一个需要相同锁的方法,则该线程可以直接执行调用的方法,而无需重新获得锁;
- 具备非阻塞锁特性:阻塞锁即没有获取到锁,则继续等待获取锁;非阻塞锁即没有获取到锁后,不继续等待,直接返回锁失败。
45.mysql读写分离
原理:读写分离就是在主服务器上修改,数据会同步到从服务器,从服务器只能提供读取数据,不能写入,实现备份的同时也实现了数据库性能的优化,以及提升了服务器安全。
46.数据库性能优化方式
建立索引,存储过程,分库分表,读写分离
springboot注解
@SpringBootApplication
@RestController
@GetMapping
@PostMapping
@PutMapping
@DeleteMapping
47.spring的注解
开启注解扫描的配置
初始化spring容器开启注解:<context:component-scan base-package="com.itheima"/>
AOP开启注解:<aop:aspectj-autoproxy proxy-target-class="true"/>
事务开启注解:<tx:annotation-driven transaction-manager="transactionManager"/>
rabbitMQ开启注解:<rabbit:annotation-driven/>
创建对象:
@Component:把资源让 spring 来管理。相当于在 xml 中配置一个 bean
@Controller
@Service
@Repository
注入数据
@Autowired:自动按照类型注入
@Qualifier:在自动按照类型注入的基础之上,再按照 Bean 的 id 注入。
@Resource:直接按照 Bean 的 id 注入。它也只能注入其他 bean 类型。
@Value:注入基本数据类型和 String 类型数据的
作用域
@Scope:取值:singleton, prototype, request, session, globalsession
生命周期
@PostConstruct:用于指定初始化方法
@PreDestroy:用于指定销毁方法。
[新注解](用于配置类的注解)
@Configuration:用于指定当前类是一个 spring 配置类,取代XML配置
@Bean:该注解只能写在方法上,表明将此方法的返回值放入 spring 容器中。
@PropertySource:用于加载.properties 文件中的配置
@Import:用于导入其他配置类,在引入其他配置类时,可以不用再写@Configuration 注解。
@ComponentScan:用于指定 spring 在初始化容器时要扫描的包(XML创建对象变成注解,要扫描注解)
spring与Junit整合
@RunWith:替换原有运行器(运行器指main函数入口)
@ContextConfiguration: 指定 spring 配置文件的位置
[AOP注解]
@Aspect:把当前类声明为切面类。
@Before:把当前方法看成是前置通知。
@AfterReturning:把当前方法看成是后置通知。
@AfterThrowing:把当前方法看成是异常通知。
@After:把当前方法看成是最终通知。
@Around:把当前方法看成是环绕通知。
@Pointcut:指定切入点表达式
**注意:*只用注解时,后置通知和最终通知在spring中的执行顺便会颠倒,因此最好只用环绕通知自己编写@Pointcut("execution( com.itheima.service.impl..(…))"),execution()为切入点表达式
[事务注解]
@Transactional(readOnly=true,propagation=Propagation.SUPPORTS)
属性:
isolation:用于指定事务的隔离级别。默认值是DEFAULT,表示使用数据库的默认隔离级别。
propagation:用于指定事务的传播行为。默认值是REQUIRED,表示一定会有事务,增删改的选择。查询方法可以选择SUPPORTS。
read-only:用于指定事务是否只读。只有查询方法才能设置为true。默认值是false,表示读写。
timeout:用于指定事务的超时时间,默认值是-1,表示永不超时。如果指定了数值,以秒为单位。
rollback-for:用于指定一个异常,当产生该异常时,事务回滚,产生其他异常时,事务不回滚。没有默认值。表示任何异常都回滚。
no-rollback-for:用于指定一个异常,当产生该异常时,事务不回滚,产生其他异常时事务回滚。没有默认值。表示任何异常都回滚。
注意:
-作用于方法上的优先级更高,
-需要配置事务管理器,
-在业务层使用
spring的事务传播
一定需要事务
- PROPAGATION_REQUIRED:使用当前事务,没有就新建事务
以当前事务为准
- PROPAGATION_SUPPORTS:使用当前事务,没有就非事务运行
- PROPAGATION_MANDATORY:使用当前事务,没有就非事务抛异常
以自己的事务为准
- PROPAGATION_REQUIRES_NEW:新建自己的事务,如果当前存在事务,把当前事务挂起
不使用事务
- PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
- PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。
嵌套事务
- PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务(也会新建自己的事务)内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作。
48锁
阻塞锁
内核态和用户态之间的切换进入阻塞挂起状态,消耗许多资源
public class Lock{
private boolean isLocked = false;
public synchronized void lock() throws InterruptedException{
while(isLocked){
//当其他线程进来,即处于等待阻塞状态
wait();
}
isLocked = true;
}
public synchronized void unlock(){
isLocked = false;
notify();
}
}
非阻塞锁
public class Lock{
private boolean isLocked = false;
public synchronized boolean lock() throws InterruptedException{
if(isLocked){
//当没有拿到锁,立即返回,线程不阻塞
return false;
}
isLocked = true;
return true;
}
public synchronized void unlock(){
isLocked = false;
}
}
自旋锁
不切换内核态和用户态,一直占着CPU,程序执行时间长了性能会降低,所以只适合程序执行时间短的
public class Lock{
private boolean isLocked = false;
public synchronized void lock() throws InterruptedException{
while(isLocked){
sout("继续不断的循环来判断是否可以拿到锁");
}
isLocked = true;
}
public synchronized void unlock(){
isLocked = false;
}
}
互斥锁
public class Lock{
private boolean isLocked = false;
public synchronized void lock() throws InterruptedException{
while(isLocked){
//当其他线程进来,直接让其进入等待状态,只有当最先拿到锁的资源,才能继续执行判断是否拿到锁
wait();
}
isLocked = true;
}
public synchronized void unlock(){
isLocked = false;
notify();
}
}
可重入锁
public class Lock{
boolean isLocked = false;
Thread lockedBy = null;
int lockedCount = 0;
public synchronized void lock()
throws InterruptedException{
Thread thread = Thread.currentThread();
while(isLocked && lockedBy != thread){
wait();
}
isLocked = true;
lockedCount++;
lockedBy = thread;
}
public synchronized void unlock(){
if(Thread.currentThread() == this.lockedBy){
lockedCount--;
if(lockedCount == 0){
isLocked = false;
notify();
}
}
}
}
不可重入锁
public class Lock{
private boolean isLocked = false;
public synchronized void lock() throws InterruptedException{
while(isLocked){
wait();
}
isLocked = true;
}
public synchronized void unlock(){
isLocked = false;
notify();
}
}
可中断锁
如果某一线程A正在执行锁中的代码,另一线程B正在等待获取该锁,可能由于等待时间过长,线程B不想等待了,想先处理其他事情,我们可以让它中断自己或者在别的线程中中断它,这种就是可中断锁。
乐观锁
每次去拿数据的时候都认为别人不会修改,所以总是不会上锁,java中的乐观锁基本都是通过CAS操作实现的
悲观锁
每次去拿数据的时候都认为别人会修改,所以每次在读写数据的时候都会上锁
公平锁
尽量以请求锁的顺序来获取锁
非公平锁
即无法保证锁的获取是按照请求锁的顺序进行的
---------
偏向锁
顾名思义,它会偏向于第一个访问锁的线程,如果在运行过程中,同步锁只有一个线程访问,不存在多线程争用的情况,则线程是不需要触发同步的,减少加锁/解锁的一些CAS操作(比如等待队列的一些CAS操作)
轻量级锁
轻量级锁是由偏向锁升级来的,偏向锁运行在一个线程进入同步块的情况下,当第二个线程加入锁争用的时候,偏向锁就会升级为轻量级锁;
重量级锁
总结
在所有的锁都启用的情况下线程进入临界区时会先去获取偏向锁,如果已经存在偏向锁了,则会尝试获取轻量级锁,如果以上两种都失败,则启用自旋锁,如果自旋也没有获取到锁,则使用重量级锁,没有获取到锁的线程阻塞挂起,直到持有锁的线程执行完同步块唤醒他们;
49Lock和synchronied区别
锁的特性:阻塞性,可中断性,乐观性和悲观性,可重入性,公平性
用户态和内核态:java的线程是映射到操作系统原生线程之上的,如果要阻塞或唤醒一个线程就需要操作系统介入,需要在用户态和内核态之间切换,这种切换会消耗大量的系统资源,因为用户态与内核态都有各自专用的内存空间,专用的寄存器等,用户态切换至内核态需要传递给许多变量、参数给内核,内核也需要保护好用户态在切换时的一些寄存器值、变量等,以便内核态调用结束后切换回用户态继续工作。
- 如果线程状态切换是一个高频操作时,这将会消耗很多CPU处理时间;
- 如果对于那些需要同步的简单的代码块,获取锁挂起操作消耗的时间比用户代码执行的时间还要长,这种同步策略显然非常糟糕的。
| 类别 | synchronied | ReentrantLock |
|---|---|---|
| 存在层次 | Java的关键字 字节码文件会加入两个指令 | 一个类,使用CAS |
| 锁的释放 | 1、以获取锁的线程执行完同步代码,释放锁 2、线程执行发生异常,jvm会让线程释放锁 | 发生异常不释放,在finally中必须释放锁,不然容易造成线程死锁 |
| 锁的获取 | 有锁获取,锁被占用会阻塞 | Lock有多个锁获取的方式,具体下面会说道,大致就是可以尝试获得锁,线程可以不用一直等 |
| 锁的状态 | 无法判断 | 可以判断 |
| 锁的类型 | 不可中断,悲观,可重入,非公平 | 可中断,乐观,可重入,默认非公平(可设置为公平) |
| 性能 | 少量同步 | 大量同步 |
spring事务原理
利用AOP,后置处理器包装代理对象,事务管理器进行回滚、提交操作
MyISAM和InnoDB区别
| MyISAM | InnoDB | |
|---|---|---|
| 索引结构 | 索引文件和数据文件分开的 主键索引和普通索引都是分开的 | 聚集索引,不是分开的 主键索引是聚集索引,普通索引data包含主键 |
| 事务 | 不支持事务 | 支持事务 |
| 锁 | 表锁 | 行锁 |
数组和ArrayList区别
1.数组长度是固定的,ArrayList可以扩容
2.数组可以存基本数据类型,ArrayList不能,因为ArrayList是在集合的元素都在堆和方法区中,基本数据类型在栈中,栈里的数据随时会被收回(容器所持有的其实是一个个reference指向Object,进而才能存储任意型别。当然这不包括基本型别,因为基本型别并不继承自任何classes)
List转数组:list.toArray
数组转List:Arrays.asList
建议:
基于效率和类型检验,应尽可能使用Array,无法确定数组大小时才使用ArrayList!
【重写equals时为什么必须重写hashCode方法】
在重写equals的时候就是比较对象内的属性是否一样,那么hashCode也要用对象的属性生成hash值,
因为equals相等的时候,hash值也要相等
另外重写equals时也重写hashCode还有一个好处就是,当数据量非常大的时候,比如一个数据要和一万数据进行比较,就可以像HashMap一样先比较他们的hash值,再比较equals,这样效率就提上来了