目录
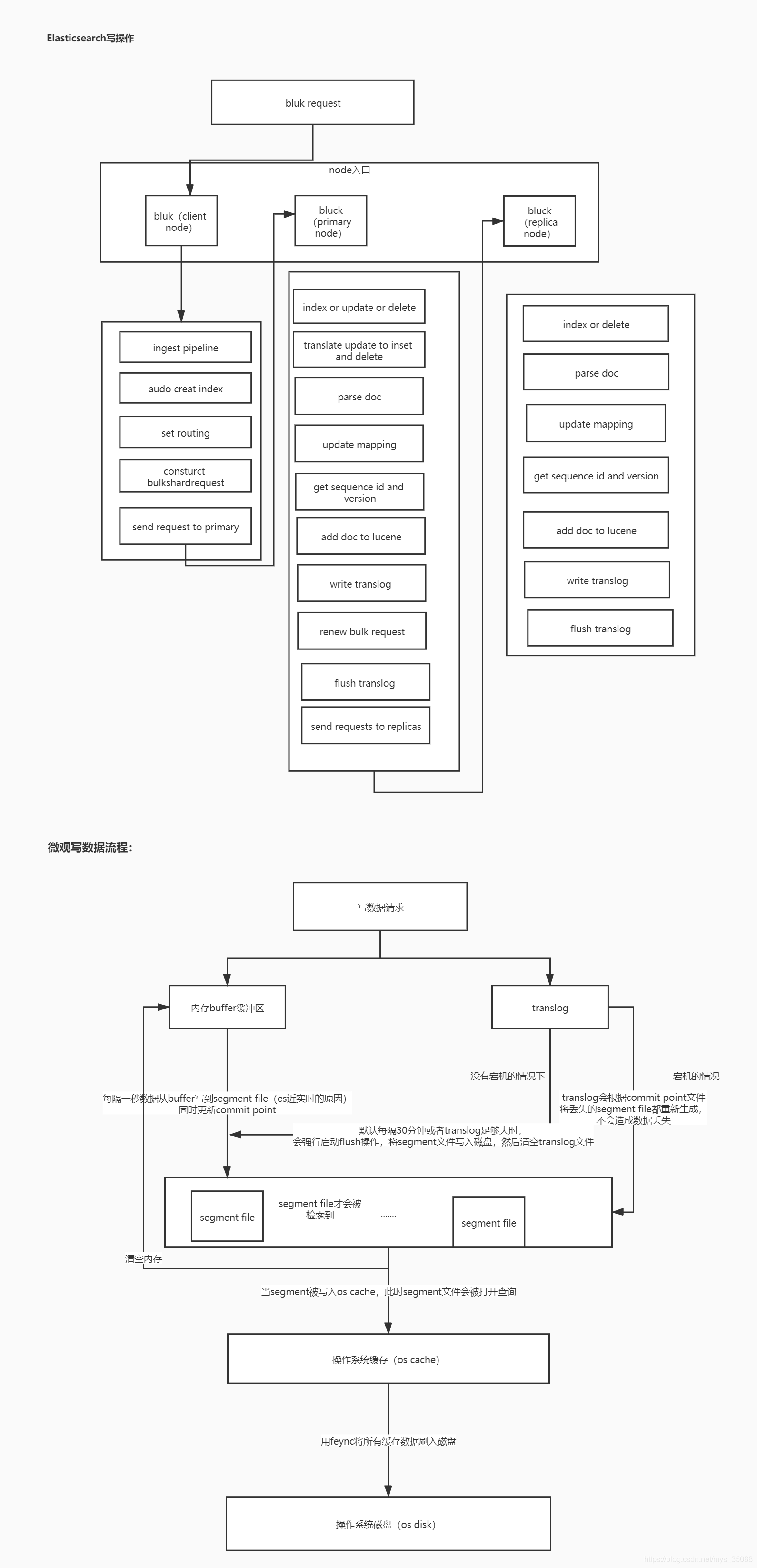
1.写数据流程
写数据路由规则:
1.每个index(类似于数据库中的表)由多个shard组成,每个shard有一个主节点(primary node)和多个副本节点(replica node)
2.每次写入的时候,写入请求会现根据routing(路由)规则选择发给哪个shard(即在找primary node)
路由规则:(1)index request 中可以设置使用哪一个field的值作为路由参数
(2)如果index没有设置,则使用mapping中的配置
(3)如果mapping中也没有设置,则使用id作为路由参数,然后通过id的hash值选出primary shard
3.请求会发数据到primary shard,在primary shard上执行成功后再从primary shard上将请求同时发给多个replica shard上将请求同时发给多个replic
写数据流程:
2.删除数据流程:
删除请求提交的时候会生成一个.del文件,里面将某个doc标识为delete状态,那么搜索的时候根据.del文件就知道doc被删除了,客户端搜索的时候发现数据在.del文件中标识为删除就不会搜索了
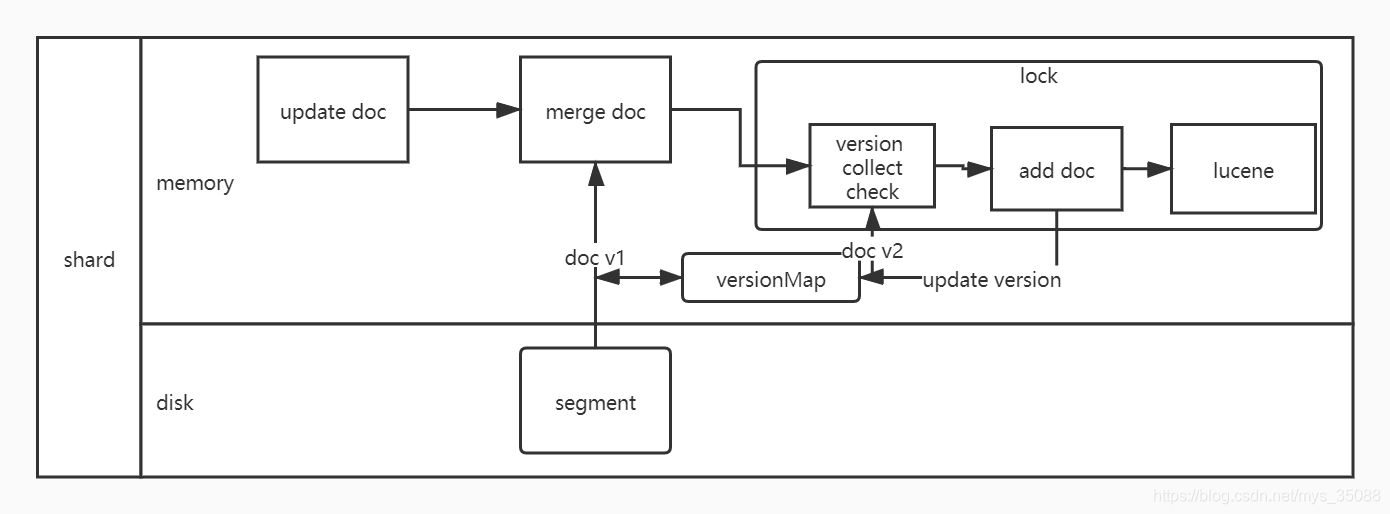
3.update数据流程:
1.更新数据的时候会把更新请求分为inset和delete请求
2.收到update后,从segment或者translog中读取同id的完整doc,记录版本号(例如:记录为v1=345)
3.将版本v1的全量doc和请求中的部分字段doc合并为一个完整的doc,同时更新内存中的versionMap
4.获取完整的doc后,update请求就变成了Post/Put请求
5.加锁(乐观锁)
6.再次从versionMap中读取该id的最大版本号V2=346
7.检查版本是否冲突(v1==v2)如果冲突,则回退到开始的“update doc”阶段,重新执行,如果不冲突,则执行最新的Add请求
8.在index doc阶段,首先将version +1 得到V3,再将doc加入到lucene中去,lucene中会删除同id下已存在的doc id,然后再增加新doc,写入lucene成功后,将当前V3更新到versionMap中
9.释放锁,部分更新的流程结束