1.已知data目录下由xls文件electricity_data.xls,其内容如下图:*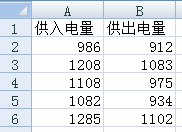
试在data并列的目录code中写出Python代码,计算出线损率,并对数据进行编号,并将结果写入到并列tmp目录下的electricity_data.xls中,使其内容如下图:****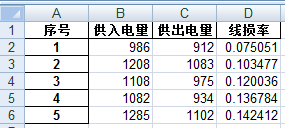
import numpy as np
import pandas as pd
dd = pd.read_excel("C:/v.xlsx")
dd.insert(0,"序号",range(1,6),allow_duplicates=True)
dd.insert(3,"线损率")
gr=dd["供入电量"]
gc=dd["供出电量"]
dd["线损率"]=(gr-gc)/gr
print(dd)
2. PCA算法(主成分分析)
总结一下PCA的算法步骤:
```python
设有m条n维数据。
1)将原始数据按列组成n行m列矩阵X
2)将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值
3)求出协方差矩阵C=1/M(xxt)
4)求出协方差矩阵的特征值及对应的特征向量
5)将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
6)Y=PX即为降维到k维后的数据
3. 已知银行用户的信用相关信息,如下图: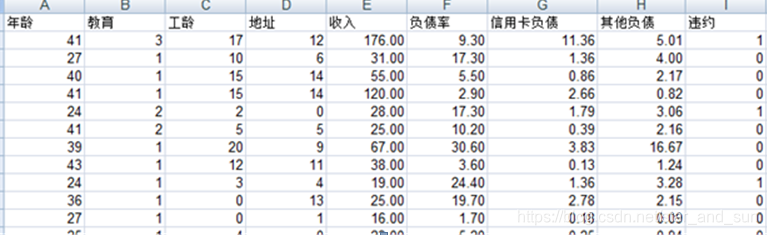
请用逻辑回归模型方法
(1)预测用户是否违约
(2)算出模型的平均正确率
import pandas as pd
filename = 'C:\Users\dell\Desktop\data.xlsx'
data = pd.read_excel(filename)
x = data.iloc[:, :8].as_matrix()
y = data.iloc[:, 8].as_matrix()
from sklearn.linear_model import LogisticRegression as LR
from sklearn.linear_model import RandomizedLogisticRegression as RLR
rlr = RLR() # 建立随机逻辑回归模型,筛选变量
rlr.fit(x, y) # 训练
rlr.get_support() # 获取特征结果
print(u'通过随机逻辑回归筛选特征结束')
print('有效特征为' + ','.join(list(data.columns[rlr.get_support()])))
x = data[data.columns[rlr.get_support()]].as_matrix() # 筛选好特征
lr = LR() # 建立逻辑回归模型
lr.fit(x, y) # 用筛选后的特征进行训练
print(u'通过逻辑回归训练结束')
print(u'模型的平均正确率:%s' % lr.score(x, y))
4. 写代码:
(1)创建helloworld.pdf文件;
(2)在文件中写入文字内容“Hellow,World”;
(3)在文件中画出一个圆圈。
from reportlab.pdfgen import canvas
def hello():
c = canvas.Canvas("helloworld.pdf")
c.drawString(100,500,"Hello,World")
c.circle(200, 600, 30, stroke=1, fill=0)
c.showPage()
c.save()
hello()
5. 写代码
(1)生成为平面上的随机点列;
(2)写出空间或者平面上两点间的距离计算函数;(以前作业;以后选作+20分)
(3)写出基于距离的聚类函数,实现平面或空间中点的聚类;
(4)对于平面上点的聚类,构造gif图像文件动态记录聚类的处理过程。
提示:
import numpy as np
import pylab as pl
import random as rd
import imageio
import math
#计算平面两点的欧氏距离
step=0
color=['.r','.g','.b','.y']#颜色种类
ecolor=['*','*','*','*']#类中心
frames = []
#两点间的距离平方公式:更改后可以计算n维空间中的距离,a,b类型可以是元祖、列表、向量、ndarray、
def distance(X1, X2):
if len(X1)!=len(X2):
print("维度数不同!")
return -1
s=0
for i in range(len(X1)):
s+=(X1[i]-X2[i])**2
return math.sqrt(s)
#K均值算法:
def k_means(x, y, k_count):
count = len(x) #点的个数
#随机选择k_count个点
k = rd.sample(range(count), k_count) #从0到count-1这count个数中抽取k_count个样本
k_point = [[x[i], y[i]] for i in k]#保证有序,记录中心点的位置
k_point.sort() #排序中心点,从左到右,从下到上
global frames
global step
while True:
km = [[] for i in range(k_count)] #存储每个簇的索引
#遍历所有点
for i in range(count):
cp = [x[i], y[i]] #当前点
#计算cp点到所有质心的距离
_sse = [distance(k_point[j], cp) for j in range(k_count)]
#cp点到那个质心最近
min_index = _sse.index(min(_sse))
#把cp点并入第i簇
km[min_index].append(i)
#更换质心
step+=1
k_new = []
for i in range(k_count):
_x = sum([x[j] for j in km[i]]) / len(km[i])
_y = sum([y[j] for j in km[i]]) / len(km[i])
k_new.append([_x, _y])
k_new.sort() #从左到右,从下到上
#使用Matplotlab画图:
pl.figure()
pl.title("N=%d,k=%d iteration:=%d"%(count,k_count,step))
for j in range(k_count):
pl.plot([x[i] for i in km[j]], [y[i] for i in km[j]], color[j%4])
pl.plot(k_point[j][0], k_point[j][1], ecolor[j%4])
pl.savefig("1.jpg")#存储文件
frames.append(imageio.imread('1.jpg'))#添加图形页面
if (k_new != k_point) :#一直循环直到聚类中心没有变化
k_point = k_new #更新记录
else:
frames.append(imageio.imread('1.jpg'))#添加图形页面
frames.append(imageio.imread('1.jpg'))#添加图形页面
break
x=np.random.randn(50)
y=np.random.randn(50)
k_count = 4 #分为4类
k_means(x, y, k_count) #聚类结果
imageio.mimsave('../tmp/k-means.gif', frames, 'GIF', duration = 1.0) #动画效果图片
6. 写代码
(1)生成为平面上的随机点列;
(2)写出空间或者平面上两点间的距离计算函数;
(3)写出基于距离的聚类函数,实现平面或空间中点的聚类;
(4)对于平面上点的聚类,构造gif图像文件动态记录聚类的处理过程。
与5一样
7. 写代码生成旋转的圆圈图标。
先找一个图标——旋转10度(一共36张)每张都储存为PNG图片——用上一道题的方法合并成gif格图片——结果就是了 #旋转度数越小,张数越多,看起来越清晰
def draw(a, b, r):
theta = np.arange(0, 2*np.pi, 0.01)
x = a + r * np.cos(theta)
y = b + r * np.sin(theta)
fig = plt.figure()
axes=fig.add_subplot(111)
axes.plot(x,y)
axes.axis('equal')
#旋转
frames = []
for i in range(180):
x = 5 * m.cos(m.radians(i)) - 5 * m.sin(m.radians(i))
y = 5 * m.sin(m.radians(i)) + 5 * m.cos(m.radians(i))##圆心变换
draw(x, y, 10)
pl.savefig("1.jpg") # 存储文件
frames.append(imageio.imread('1.jpg')
#frames.append(imageio.imread('1.jpg'))
imageio.mimsave('C:\\Users\\dell\\Desktop\\k-means.gif', frames, 'GIF', duration = 1.0)
‘’’
import numpy as np
import matplotlib.pyplot as plt
import math as m
path1 = 'C:\\Users\\HP\\Desktop\\python\\a'
path2 = '.png'
######################画一片树叶###########################
def drawLeaf(x0,y0,alpha0,size):
alphas=np.linspace(-m.pi/8,m.pi/8,100)
x=np.cos(4*alphas)*np.cos(alphas+alpha0)
y=np.cos(4*alphas)*np.sin(alphas+alpha0)
x*=size
y*=size
plt.plot(figsize=(8,6))
plt.plot(x,y,"g-")
myColor='#00FF00'
plt.fill(x,y,myColor,alpha=0.5)
plt.xlim(-30, 30)
plt.ylim(-30, 30)
# drawLeaf(30,30,0.4,30)
# plt.show()
##########################2.画一朵小花##############################
deltalpha=m.pi/18
n=1+int(eltalpha)
for i in range(n):
drawLeaf(30,30,deltalpha*i,30)
plt.savefig(path1+str(i)+path2)
plt.show()
8. 已知学生成绩表如下:
请用python代码完成学生成绩分析报告。
要求成绩得报告形式为
(1)各单科的平均成绩
(2)综合(班)平均成绩
(3)总平均成绩分布的直方图(根据一般要求,分组数为0,60,70,80,90,100)
import numpy as np
import pandas as pd
data=pd.read_excel('score.xlsx')#data.xls在代码的当前目录中
cols=data.columns
cols=cols[2:]
d2=data[cols]
s=d2.sum(axis=1)#行和就是是总分
data["总分"]=s #给总分命名
data=data.append(data.mean(),ignore_index=True)#增加一行均值
le=len(data)
data.iloc[le-1,0]=""
data.iloc[le-1,1]="单科平均"# 均值命名
plt.hist(data.iloc[3,9:10].T,【0,60,70,80,90,100】)
################方法二
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt #导入作图库
data=pd.read_excel("zxn.xlsx")#读取数据
col_max=data.iloc[:,2:].max()#求每一列的最大值
col_mean=data.iloc[:,2:].mean()#求每一列的平均值
#col_max['姓名']='最大值'#添加最大值
col_mean["姓名"]="单科平均"#添加单科平均
#stu=data.append(col_max,ignore_index=True)#将每列最大值添加在末尾行
data=data.append(col_mean,ignore_index=True)#将每列平均值添加在末尾行
d=data.iloc[:3,2:]#取分数区域
data["总平均分"]=d.mean(axis=1)#求每一行的平均
data["总成绩"]=d.sum(axis=1)#每一行加总
d7=data
d7.to_excel("newScores4.xls",index = False)
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.hist(data.iloc[:3,9:10].T)
#plt.xlim(0,100)
plt.ylabel('各科总成绩') #坐标轴标签
plt.xlabel("总平均成绩
9. 已知逻辑回归模型的预测处理代码如下:
x0=[41,3,16,13,176.00,9.30,11.36,5.01]#原始要预测的数据
a=np.array(x0).reshape(1,8) #变为1行8列矩阵数据
a=pd.DataFrame(a,columns=range(8)) #变为DataFrame数据
a=a.columns[rlr.get_support()] #DataFrame中选择列
b=map(lambda x:x0[x],a) #实现数据筛选
x=list(b)
x=lr.predict([np.array(x)])#上面二行合并报告错误!predict的参数为二维数组
print(x[0])
用for循环语句改写这里的代码,实现相同的功能。
import numpy as np
import pandas as pd
x0=[41,3,16,13,176.00,9.30,11.36,5.01]#原始要预测的数据
a=np.array(x0).reshape(1,8) #变为1行8列矩阵数据
a=pd.DataFrame(a,columns=range(8)) #变为DataFrame数据
print(a)
m=[]
n=list(rlr.get_support())
for i in range(8):
if n[i]:
m.append(i)
b=map(lambda x:x0[x],m)
x=list(b)
x=lr.predict([np.array(x)])#上面二行合并报告错误!predict的参数为二维数组
print(x[0])
10. 在LinearRegression.txt中有数据:
X Y
1 4
2 5
3 7
4 9
5 12
6 13
7 14
使用sklearn.linear_model 中的LinearRegression
(1)计算出回归系数;
(2)画出散点图和线性回归直线。
from openpyxl import Workbook,load_workbook
excelname="C:\\Users\\dell\\Desktop\\logistic.xlsx"
wb=Workbook()
wb.save(excelname)
sheet=wb.create_sheet('Sheet')
f=open('C:\\Users\\dell\\Desktop\\logistic.txt','r')
a=[]
for line in f.readlines():
data=line.split('\n\t')
for s in data:
se=s.split(' ')
a.append(se)
for i in range(len(a)):
sheet.append(a[i])
wb.save(excelname)
'''
data=pd.read_excel("C:\\Users\\dell\\Desktop\\logistic.xlsx")
cols=data.columns
x=data[cols[0]]
y=data[cols[1]]
x=np.array(x).reshape(-1,1)
y=np.array(y).reshape(-1,1)
from sklearn.linear_model import LinearRegression as LR
lr=LR()
lr.fit(x,y)###拟合
print(lr.coef_)
import matplotlib.pyplot as plt
plt.scatter(x,y,color='red',label=u'yuan shi zhi ')#画散点图
y_pre=lr.predict(x)
plt.plot(x,y_pre,color='black',label=u'hui gui qu xian',linewidth=3)##拟合曲线
plt.legend()
plt.show()
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
11.
data中保存了餐饮数据,写代码完成:
(1)请写一个函数mySort,完成餐饮数据基于任意列的排序;
(2)调用mySort,完成基于"百合酱蒸凤爪"的从小到大的排序。
from __future__ import print_function
import pandas as pd
import numpy as np
def mySort(data,ColumnName=None): #必须放在调用者前
if ColumnName==None:
print("ColumnName can not be empty!")
return None
data1=data[ColumnName]
data1=data1.unique()###提取原子
data1=np.sort(data1)##########排序
data2=data[data[ColumnName].isnull()]
for i in range(len(data1)):
x=data[data[ColumnName]==data1[i]]
data2=data2.append(x)
return data2
catering_sale = '../data/catering_sale_all.xls' #餐饮数据,含有其他属性
data = pd.read_excel(catering_sale, index_col = u'日期') #读取数据,指定“日期”列为索引列
data=mySort(data,ColumnName=u'百合酱蒸凤爪')
print(data)
12. catering_sale_all.xls中保存了餐饮数据,如下图:
写代码完成:
(1)对每天的销售额进行汇总,添加“合计”
(2)对各类菜品的销售额汇总,获得月销售额,在最后一行后添加各类菜品的总计,并将处理有的文件写入catering_sale.xls
(3)输出当期总销售额。
#餐饮销量数据相关性分析
from __future__ import print_function
import pandas as pd
import numpy as np
catering_sale = '../data/catering_sale_all.xls' #餐饮数据,含有其他属性
out_sale="catering_sale.xls"
data = pd.read_excel(catering_sale) #读取数据,指定“日期”列为索引列
data[u"合计"]=data.sum(axis=1)
data2=data.sum(axis=0)
data=data.append(data2,ignore_index=True)
data.iloc[len(data)-1,0]="总计"
data.to_excel(out_sale,index=None)
print(data.loc[len(data)-1,"合计"])
13. 写函数findSeat,求处矩阵中第一个最大元素的位置。
import pandas as pd
import numpy as np
x0=[41,16,13,17,9,41,11,36,6,8,11,24]
a=np.array(x0).reshape(3,4) #变为3行4列矩阵数据
def findSeat(x):
m=len(x) #矩阵行数
n=len(x[0]) #矩阵列数
Max=x.max()
for i in range(m):
for j in range(n):
if Max==x[i][j]:
return(i,j)
print(findSeat(a))
14. 写函数findSeat,求DataFrame表中第一个最大元素的位置
import pandas as pd
import numpy as np
d=pd.DataFrame({'a':[1,2,3],'b':[3,4,5],'c':[2,4,5]})
def findSeat(x):
m=x.shape[0] #dataframe行数
n=x.shape[1] #列数
Max=max(x.max()) #x.max()只可以找到每列的最大值 最大值的最大值就是最大值
for i in range(m):
for j in range(n):
if Max==x.iloc[i,j]:
return(i,j)
print(findSeat(d))
15. (1)写函数myFindSeat查找一个DataFrame类型的表中最值元素所在的行和列序数;
(2)写出测试语句测试(1)的正确性。
i
import pandas as pd
import numpy as np
d=pd.DataFrame({'a':[1,2,3],'b':[3,4,5],'c':[2,4,5]})
print(d)
def findSeat(x):
m=x.shape[0] #行数
n=x.shape[1] #列数
Max=max(x.max()) #最大值
for i in range(m):
for j in range(n):
if Max==x.iloc[i,j]:
print("行序数是",i)
print("列序数是",j)
return
findSeat(d)
17. import pandas as pd
import numpy as np
def myFindSeat(data):
coln=data.shape[1]
data=np.array(data)
data2=pd.DataFrame(data[0])
for i in range(1,coln+1):
data2=data2.append(pd.DataFrame(data[i]))
data=pd.Series(np.array(list(data2[0])))
data=pd.DataFrame(data)
print(data)
rowIndex=int(int(data[0].idxmax())/coln)
colIndex=int(data[0].idxmax())%coln
return rowIndex,colIndex
a=np.array([[6,2,1],[2,1,7],[3,1,6],[4,2,1]])
b=pd.DataFrame(a)
print(b)
r,c=myFindSeat(b)
print(a)
print(“最大值的行序数:%d 列序数%d”%(r,c))
使用axis参数,改写上面程序
import pandas as pd
import numpy as np
def myFindSeat(data):
coln=data.shape[1]
rown=data.shape[0]
data=np.array(data)
data2=pd.DataFrame(data[0])
for i in range(1,coln+1):
data2=data2.append(pd.DataFrame(data[i]))
data=pd.Series(np.array(list(data2[0])))
data=pd.DataFrame(data)
print(data)
colIndex=int(int(data[0].idxman())/rown)
rowIndex=int(data[0].idxman())%rown
return rowIndex,colIndex
a=np.array([[6,2,3],[2,3,5],[3,2,6],[4,2,1]])
b=pd.DataFrame(a)
print(b)
r,c=myFindSeat(b)
print(a)
print("行序数:%d 列序数%d"%(r,c))
18. 已知某个食店的菜品销售数据如下
设最大支持度是0.2,用apriori关联规则算法推导最大频繁项集。
19. d为DataFrame类型的表格数据,
(1)写程序计算其各个行的和,并在其后面添加一列,新列名为’s’;
(2)写程序计算d的各个列的和,并将结果记录到d的最后一行;
(3)将d的行序数改为1~n,其中n是数据的行数。
d=pd.DataFrame({'a':[1,2,3],'b':[3,4,5],'c':[2,4,5]})
d2=d.sum(axis=1)
d["s"]=d2
print(d)
#data=data.append(data.mean(),ignore_index=True)
d=d.append(d.sum(),ignore_index=True)
print(d)
le=len(d)
print(le)
20. d为DataFrame类型的表格数据,
(1)写程序求其各个行的最小值,并在其后面添加一列,新列名为’m’;
(2)写程序求d的各个列的最小值,并将结果记录到d的最后一行;
(3)将d的值按m列的值由大到小排序。
import pandas as pd
data=pd.DataFrame({"a":[1,23,6,9,8,5],"b":[5,6,9,2,4,8],"c":[6,2,4,8,7,6],"d":[1,3,6,2,5,8],"e":[3,6,2,5,8,4]})
print(data)
d1=data.min(axis=1)
print(d1)
data1=pd.concat([data,d1],axis=1)#行对齐,横向拼接
data1.columns=list(data.columns)+['m']
#也可以 data.insert(5,'m',d1)
print(data1) #(1)写程序求其各个行的最小值,并在其后面添加一列,新列名为'm';
d2=data1.min()
print(d2)
data2=data1.append(pd.DataFrame(list(d2),index=data1.columns).T)#index=data1.columns:a,b••e,m
data2.index=list(data1.index)+['n']
#也可以 data1.loc['n']=d2
print(data2) #(2)写程序求d的各个列的最小值,并将结果记录到d的最后一行;
data3=data2.sort_values(['m'],ascending=False) #ascending=False不上升,排序由大到小
print(data3)
###方法二简单些
d=pd.DataFrame({'a':[1,2,3],'b':[3,4,5],'c':[2,4,5]},index=range(1,4))
d2=d.min(axis=1)
d["m"]=d2
print(d)
#data=data.append(data.mean(),ignore_index=True)
d=d.append(d.min(),ignore_index=True)
print(d)
d=d.sort_values(['m'],ascending=False)
print(d)
21. 已知学生考试成绩如下:
(1)计算各学生的总成绩;
(2)计算各个学生的成绩的均匀程度;
(3)基于各个同学成绩均匀程度从小到大排序;
(4)基于成绩的均匀程度,作出均匀程度分布的直方图,显示学生成绩均匀程度的分布情况。
d=pd.read_excel('C:\\Users\\dell\\Desktop\\data7.xlsx')
cols=d.columns
cols=cols[2:-1]
d2=d[cols]
s=d2.sum(axis=1)
d["总成绩"]=s
m=d2.mean(axis=1)
d["平均"]=m
print(d)
d.sort_values(["平均"],ascending=False)
print(d)
plt.hist(m)
22. 已知学生的考试成绩记录,形如下图:
写代码形成各个等级学生的人数,形如下图: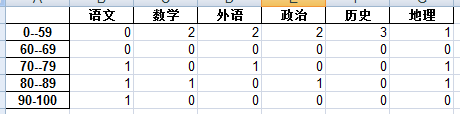
import pandas as pd
data=pd.read_excel("scores.xls")
oldColumns=list(data.columns)
headnames=list(data.columns)
Indexname=headnames[0:2]
del(headnames[0:2])
newColumns=headnames
del(headnames[len(headnames)-1])
data_zs=data[headnames]
subject=list(headnames)
import matplotlib.pyplot as plt
scounts=[]
scount=[]
outData=pd.DataFrame()
for sj in subject:
scount=[]
tmp=data_zs[sj]
tmp2=tmp[tmp<60]
count=len(tmp2)
scount =[count]
for k in range(6,10):
tmp2=tmp[tmp>=k*10]
tmp2=tmp2[tmp2<(k+1)*10]
count=len(tmp2)
scount +=[count]
#print(scount)
scounts+=[scount]
outData=pd.concat([outData,pd.Series(scount)],axis=1)
outData.index= ['0--59','60--69','70--79','80--89','90-100']
outData.columns=subject
outData.to_excel("countData.xls")
##########################
import pandas as pd
data=pd.read_excel('C:\\Users\\dell\\Desktop\\data7.xlsx')
cols=data.columns
cols=cols[2:-1]
data1=data[cols]
print(data1)
import matplotlib.pyplot as plt
scounts=[]
scount=[]
outData=pd.DataFrame()
for sj in cols:
scount=[]
tmp=data1[sj]
tmp2=tmp[tmp<60]
count=len(tmp2)
scount =[count]
for k in range(6,10):
tmp2=tmp[tmp>=k*10]
tmp2=tmp2[tmp2<(k+1)*10]
count=len(tmp2)
scount +=[count]
#print(scount)
scounts+=[scount]
outData=pd.concat([outData,pd.Series(scount)],axis=1)
outData.index= ['0--59','60--69','70--79','80--89','90-100']
outData.columns=cols
print(outData)
23. 已知学生的考试成绩记录,形如下图:
写代码形成各个等级学生人数的占比,形如下图: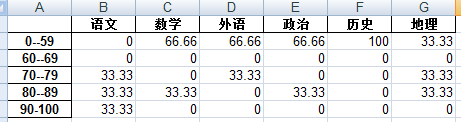
import pandas as pd
data=pd.read_excel("scores.xls")
oldColumns=list(data.columns)
headnames=list(data.columns)
Indexname=headnames[0:2]
del(headnames[0:2])
newColumns=headnames
del(headnames[len(headnames)-1])
data_zs=data[headnames]
meanScores=data_zs.mean()
data_zs=data_zs.append(meanScores,ignore_index=True)
total=pd.Series(data_zs.sum(axis=1))
data_zs=pd.concat([data[Indexname],data_zs,total],axis=1)
data_zs.columns=oldColumns
count=len(data_zs)
data_zs['姓名'][count-1]='单科平均' #data_zs.iloc[count-1,1]='单科平均' 可以去掉警告
data_zs.to_excel("newScores.xls",index = False)
#(2)
import matplotlib.pyplot as plt
count=len(data_zs)
colCount=len(newColumns)
dataview=data_zs[newColumns+['总成绩']]
sizes=dataview.iloc[count-1,:colCount]/dataview.iloc[count-1,colCount]
sizes=100*sizes
plt.pie(sizes,labels=newColumns,autopct='%1.1f%%')
plt.rcParams['font.sans-serif']=['SimHei']
plt.axis('equal')
plt.show()
################简单点的方法
import pandas as pd
data=pd.read_excel('C:\\Users\\dell\\Desktop\\data7.xlsx')
cols=data.columns
cols=cols[2:-1]
data1=data[cols]
print(data1)
import matplotlib.pyplot as plt
scounts=[]
scount=[]
outData=pd.DataFrame()
for sj in cols:
scount=[]
tmp=data1[sj]
tmp2=tmp[tmp<60]
count=len(tmp2)
scount =[count]
for k in range(6,10):
tmp2=tmp[tmp>=k*10]
tmp2=tmp2[tmp2<(k+1)*10]
count=len(tmp2)
scount +=[count]
#print(scount)
scounts+=[scount]
outData=pd.concat([outData,pd.Series(scount)],axis=1)
outData.index= ['0--59','60--69','70--79','80--89','90-100']
outData.columns=cols
print(outData)
d=outData.sum()
print(d)
d2=outData/d
print(d2)
**24. 已知学生成绩表如下:
请用python代码完成学生成绩分析报告。
要求成绩得报告形式为**
要求:
(1)各单科的平均成绩
(2)总成绩中各个学科的贡献率饼图,如下:
#(2)
import matplotlib.pyplot as plt
count=len(data_zs)
colCount=len(newColumns)
dataview=data_zs[newColumns+['总成绩']]
sizes=dataview.iloc[count-1,:colCount]/dataview.iloc[count-1,colCount]
sizes=100*sizes
plt.pie(sizes,labels=newColumns,autopct='%1.1f%%')
plt.rcParams['font.sans-serif']=['SimHei']
plt.axis('equal')
plt.show()
####3#
d=pd.read_excel('C:\\Users\\dell\\Desktop\\data7.xlsx')
cols=d.columns
cols=cols[2:-1]
d2=d[cols]
s=d2.sum(axis=1)
d["总成绩"]=s
d=d.append(d.mean(),ignore_index=True)
print(d)
meandata=d.iloc[3,2:-1]#
t=d.iloc[3,-1]###总的平均值
print(meandata)
l=list(meandata/t)
label=["语文","数学","外语","政治","历史"]
plt.pie(l,labels=label)
plt.rcParams['font.sans-serif']=['SimHei']
plt.axis('equal')
plt.show()
**25. 已知某个食店的菜品销售数据如下设最小支持度是0.3,
用apriori关联规则算法推导最大频繁项集。**
##############aapriori算法
#-*- coding: utf-8 -*-
from __future__ import print_function
import pandas as pd
#自定义连接函数,用于实现L_{k-1}到C_k的连接
def connect_string(x, ms):
x = list(map(lambda i:sorted(i.split(ms)), x))
l = len(x[0])
r = []
for i in range(len(x)):
for j in range(i+1,len(x)):
if x[i][:l-1] == x[j][:l-1] and x[i][l-1] != x[j][l-1]:
r.append(x[i][:l-1]+
sorted([x[j][l-1],x[i][l-1]]))
return r
#寻找关联规则的函数
def find_rule(d, support, confidence, ms = u'--'):
results=pd.DataFrame(index=['support', 'confidence'])
result = pd.DataFrame(index=['support', 'confidence']) #定义输出结果结构
support_series = 1.0*d.sum()/len(d) #支持度序列 按列求和
column = list(support_series[support_series >=
support].index) #初步根据支持度筛选
k = 0 #搜索序数
while len(column) > 1:
k = k+1
print(u'\n正在进行第%d次搜索...' %k)
column = connect_string(column, ms) #调用连接函数
print(column)
print(u'数目:%d...' %len(column))
sf = lambda i: d[i].prod(axis=1, numeric_only = True) #新一批支持度的计算函数
#创建连接数据,这一步耗时、耗内存最严重。当数据集较大时,可以考虑并行运算优化。
d_2 = pd.DataFrame(list(map(sf,column)),
index = [ms.join(i)
for i in column]).T
support_series_2 = 1.0*d_2[[ms.join(i) for i in column]].sum()/len(d) #计算连接后的支持度
column = list(support_series_2[support_series_2 > support].index) #新一轮支持度筛选
support_series = support_series.append(support_series_2)
column2 = []
for i in column:
#遍历可能的推理,如{A,B,C}究竟是A+B-->C还是B+C-->A还是C+A-->B?
i = i.split(ms)
for j in range(len(i)):
column2.append(i[:j]+i[j+1:]+i[j:j+1])
cofidence_series =pd.Series(index=[ms.join(i) for i in column2])
#定义置信度序列
for i in column2: #计算置信度序列
cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))]/support_series[ms.join(i[:len(i)-1])]
for i in cofidence_series[cofidence_series >= confidence].index: #置信度筛选
result[i] = 0.0
result[i]['confidence'] = cofidence_series[i]
result[i]['support'] =support_series[ms.join(sorted(i.split(ms)))]
'''
result = result.T.sort_values(['confidence',
'support'],
ascending = False) #结果整理,输出
'''
print(u'\n结果为:')
result=result.T
result['count']= [len(i) for i in result.index]
result = result.sort_values(['count',
'confidence',
'support'],
ascending = False) #结果整理,输出
result=result.iloc[:,:-1]
print(result)
return result
#第一种方法,老师的方法
#-*- coding: utf-8 -*-
#使用Apriori算法挖掘菜品订单关联规则
from __future__ import print_function
import pandas as pd
import numpy as np
from apriori import * #导入自行编写的apriori函数
#inputfile = '../data/menu_orders.xls'
inputfile = '../data/data.xls'
outputfile = '../tmp/apriori_rules.xls' #结果文件
data = pd.read_excel(inputfile, header = None)
print(data)
input()
print(u'\n转换原始数据至0-1矩阵...')
ct = lambda x : pd.Series(1, index = x[pd.notnull(x)]) #转换0-1矩阵的过渡函数
b = map(ct,np.array(data)) #用map方式执行 对于data中的所有行 不为空的
c=pd.DataFrame(list(b)).copy()
#实现矩阵转换,空值用0填充
print(c)
input()
data=c.fillna(0)
print(data)
input()
print(u'\n转换完毕。')
del b #删除中间变量b,节省内存
support = 0.3 #最小支持度
confidence = 0.5 #最小置信度
ms = '--' #连接符,默认'--',用来区分不同元素,如A--B。需要保证原始表格中不含有该字符
find_rule(data, support, confidence, ms).T.to_excel(outputfile) #保存结果 .T:转置变换
import pandas as pd
import numpy as np
data=pd.read_excel('data.xlsx',header=None)
#print(data)
a=np.array(data)
m=lambda x:pd.Series(1,index=x[pd.notnull(x)])#x非空值为1
n=map(m,a)#pd.Series(1,index=a[pd.notnull(a)])
data2=pd.DataFrame(list(n))#只有na和1
#print(data2)#转化为0—1矩阵
data2=data2.fillna(0)#用0填充缺失值
print('data2')
print(data2)
l=len(data)#行数
X11=data2.sum()/l #1项集
print('#1项候选集')
print(X11)#a,b,、、,频数
XP1=X11[X11>=0.2] #1项频繁集
print('1项频繁集')
print(XP1)
inX1=list(XP1.index) #['a', 'b', 'c', 'd', 'e']#
inX2=[]
X2=[]
for i in range(len(inX1)):
for j in range(i+1,len(inX1)):
inX2.append(inX1[i]+inX1[j])#X2的index列
X2.append(data2[inX1[i]]+data2[inX1[j]])
X2=pd.DataFrame(X2).T#转置
X2.columns=list(inX2) #inX2为X2候选项索引
X22=X2[X2==2].count()/l #2项集
print('2项候选集')
print(X22)
XP2=X22[X22>=0.2] #2项频繁集
print('2项频繁集')
print(XP2)
inX2=XP2.index
inX33=[]
for i in range(len(inX2)):
for j in range(i+1,len(inX2)):
y=sorted(list(set((list(inX2[i])+list(inX2[j])))))
inX33.append(y)
l2=len(inX33)
inX333=[]
for i in range(l2):
if len(inX33[i])==3:
inX333.append(inX33[i]) #删除4元素列表
#print(inX33)
inX3333=[]
for i in inX333:
if not i in inX3333:
inX3333.append(i) #删除重复项
#print(inX333)
X3=[]
inx3=[] #X3候选项索引
for i in inX3333:
X3.append(data2[i[0]]+data2[i[1]]+data2[i[2]])
inx3.append(i[0] + i[1] + i[2])
X3=pd.DataFrame(X3).T
#print(inx3)
X3.columns=inx3
#print(X3)
X33=X3[X3==3].count()/l #3项集
print('3项候选集')
print(X33)
XP3=X33[X33>=0.2] #3项频繁集
print('3项频繁集')
print(XP3)
inX3=XP3.index
inX44=[]
for i in range(len(inX3)):
for j in range(i+1,len(inX3)):
y=sorted(list(set((list(inX3[i])+list(inX3[j])))))
inX44.append(y)
l3=len(inX44)
inX444=[]
for i in range(l3):
if len(inX44[i])==4:
inX444.append(inX44[i]) #删除5元素列表
#print(inX33)
inX4444=[]
for i in inX444:
if not i in inX4444:
inX4444.append(i) #删除重复项
#print(inX333)
X4=[]
inx4=[] #X4候选项索引
for i in inX4444:
X4.append(data2[i[0]]+data2[i[1]]+data2[i[2]]+data2[i[3]])
inx4.append(i[0] + i[1] + i[2]+i[3])
X4=pd.DataFrame(X4).T
#print(inx3)
X4.columns=inx4
#print(X3)
X44=X4[X4==4].count()/l #4项集
print('4项候选集')
print(X44)
XP4=X44[X44>=0.2] #4项频繁集
print('4项频繁集')
print(XP4)
27. 写出两点间的距离的计算函数(要求适应二维和三维空间)
import numpy as np
def distance(a,b):
x=np.array(a)
b=np.array(b)
d=np.sqrt(np.sum(np.square(x-y)))
return d
28. 写代码实现
(1)myInput函数完成百分制成绩输入功能;
(2)changeScore函数完成百分制成绩转换为等级制成绩;
(3)循环调用函数(1)(2)直到输入q或Q结束输入和转换工作。
def myInput():
a=int(input("输入一个百分制成绩:"))
if a.isdigit==True:
return a
def changeScore(x):
#while(Ture)
if(x>=60):
if(x<90):
print("还好,成绩良好!")
else:
print("恭喜你,你的成绩为优秀!")
else:
print("你的成绩不合格!")
while(True):
i=1
if(i<5):
changeScore(myInput())
else:
break
i=i+1
###########################
def myInput():
s=input()
if s=="q":
return False
if s=="Q":
return False
while not s.replace(".","",1).isdigit():
print(s+" is not a number")
s=input()
if(s=="q"):
return False;
s=eval(s) #s=int(s) s=float(s)
return s
def changeScore(s):
if 90<=s<=100:
return("A")
elif 80<=s<90:
return("B")
elif 60<=s<80:
return("C")
elif 0<=s<60:
return("D")
else:
return("数字范围错误!")
while True:
s=myInput()
if s==False:
break
print(changeScore(s))
29. 写代码实现加法口诀表的输出
#############第一种方法
for i in range(1,10):
for j in range(1,i+1):
print("%d+%d=%d"%(j,i,i+j),end=' ')
print()
##第二种
i=1
while i<=9:
s=1
while s<=i:
print("%d+%d=%d"%(s,i,s+i),end=’\t’)
s+=1
print()
i+=1
30. 生成pdf文件,并写入文本内容(文件中添加文本内容和图形内容)
f=pd.read_table("C:\\Users\\dell\\Desktop\\data.txt",'r')
print(f)
for line in f:
print(line)
from reportlab.pdfgen import canvas
def hello():
c=canvas.Canvas("hello.pdf")
c.drawString(100,100,"hello word")
c.showPage()
c.save
hello()
31. 已知学生考试成绩记录在score.xls文件中
(1)计算各学生的总成绩;
(2)计算各个学科的平均成绩;
(3)画出饼图,显示各课平均成绩对总平均成绩的贡献率;
(4)画出"外语"考试成绩分布的直方图。
import pandas as pd
data=pd.read_excel("score.xls",index_col=u"学号")
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif']='simhei'
plt.rcParams['axes.unicode_minus']=False
(1)
data=pd.read_excel('scores.xls')#data.xls在代码的当前目录中
cols=data.columns
cols=cols[2:]
d2=data[cols]
s=d2.sum(axis=1)
data["总分"]=s #给总分命名
(2)
data=data.append(data.mean(),ignore_index=True)
le=len(data)
data.iloc[le-1,0]=""
data.iloc[le-1,1]="平均"# 均值命名
data.iloc[le-1,8]=""
(3)
m=data.iloc[le-1,-1]###总分的平均值
p=data.iloc[le-1,:-1]##最后一行是每科的平均成绩
l=p/m
list1=list(l)
biaoqian=['语文','数学','外语','政治','历史','地理']
size=list1
colors='gray','green','pink','purple','yellow','blue'
plt.pie(size,labels=biaoqian,explode=exp,
colors=colors,autopct='%1.1f%%')
plt.show()
(4)
d=data[‘外语’]
plt.hist(d,10,color=”blue”)
plt.xlable(“外语成绩区间”)
plt.ylable(“频数”)
plt.show()
32. 计算空气污PM25染日均值;
画出空气污染的变化曲线。
```python
import pandas as pd
import matplotlib.pyplot as plt
data=pd.read_excel("pm25")
plt.scatter(data,color='red',label=u'pm2.5 ')#画散点图
y_pre=lr.predict(x)
plt.plot(x,y_pre,color='black',label=u'hui gui qu xian',linewidth=3)##拟合曲线
plt.legend()
plt.show()
plt.plot(data)
33. 已知数据的Excel文件data2.xls形式如下: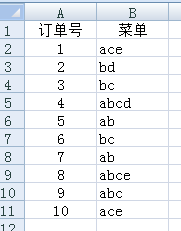
要用apriori方法进行关联规则挖掘,请写出python代码,将原来数据转换为0-1矩阵。
import pandas as pd
import numpy as np
data=pd.read_excel('data.xlsx',header=None)
#print(data)
a=np.array(data)
m=lambda x:pd.Series(1,index=x[pd.notnull(x)])#x非空值为1
n=map(m,a)#pd.Series(1,index=a[pd.notnull(a)])
data2=pd.DataFrame(list(n))#只有na和1
#print(data2)#转化为0—1矩阵
data2=data2.fillna(0)#用0填充缺失值
print('data2')
print(data2)
34. 已知某食店食品销售数据为EXCEL文件data2.xls,格式如下: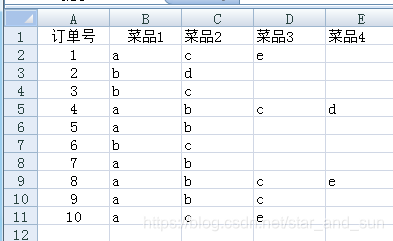
现需用apriori算法进行数据关联挖掘,请写Python代码对数据进行规范化,得到0-1矩阵,并要求各列按英文字母顺序排列。
import pandas as pd
import numpy as np
data=pd.read_excel('data.xlsx',header=None)
#print(data)
a=np.array(data)
m=lambda x:pd.Series(1,index=x[pd.notnull(x)])#x非空值为1
n=map(m,a)#pd.Series(1,index=a[pd.notnull(a)])
data2=pd.DataFrame(list(n))#只有na和1
#print(data2)#转化为0—1矩阵
data2=data2.fillna(0)#用0填充缺失值
print('data2')
print(data2)
35. 写代码两个输入正整数,并求最大公因素。
```csharp
a = int(input("请输入一个整数: "))
b = int(input("请输入一个整数: "))
if a < b:
c = a # 是交换而不是赋值
a = b
b = c
while b != 0:
c = a % b
a = b
b = c
print('这两个整数的最大公约数:', a)
36. 用二分法,求方程 在[1,3]上的近似根,要求精度达到0.000001。
def f(x):
return x**3-4*x**2+7
def func(a,b):
m=(a+b)/2
while m>=0.000001:
if f(m)==0:
break
elif(f(m)*f(a)<0):
b=m
elif(f(m)*f(a)<0):
a=m
return m
a=1
b=3
print(func(a,b))
37. 写程序将输入1-99999的数转换为大写中文形式。
问题发现:不完全正确
def func(a):
dic_unit={0:"",1:u"拾",2:u"伯",3:u"仟",4:u"万"}
dic_num={"0":u"零","1":u"壹","2":u"贰","3":u"叁","4":u"肆","5":u"伍","6":u"陆","7":u"柒","8":u"扒","9":u"玖"}
flag=True
#daxie=''
while flag:
fs=[]
daxie=''
num=a
if num=='q' or num=='Q':
flag=False
elif int(num)<1 or int(num)>99999:
print("错误!请输入1-99999之间的数字!")
continue
else:
listnum=list(num)
lennum=len(listnum)-1
for item in listnum:
fs.append(dic_num[item])
fs.append(dic_unit[lennum])
lennum-=1
daxie=''.join(fs)
flag=False
print(daxie)
x=input("请输入数字:")
func(x)
38. 写程序将输入1-99999的数转化为大写中文形式。与37一样
39. 写函数myDisplay,将给定的链表中的原子成员全部显示出来。
例:对于a=[1,2,3,[4,5,6],[7,8]],可以输出:1,2,3,4,5,6,7,8
39.def myDisplay(l):
if isinstance(l,int): #判断是不是int类型#
print(l)
else:
for i in l:
myDisplay(i)
a=[1,2,3,[4,5,6],[7,8]]
myDisplay(a)
40. 写函数myDisplay,将给定的链表中的原子成员全部显示出来。
例:对于a=(1,2,3,(4,5,6),(6,7,8)),可以输出:1,2,3,4,5,6,6,7,8
40def myDisplay(l):
if isinstance(l,int): #判断是不是int类型#
print("the element is:",l)
else:
for i in l:
myDisplay(i)
a=(1,2,3,(4,5,6),(6,7,8))
myDisplay(a)
41. 写函数myDisplay,将给定的链表或元组中的原子成员全部显示出来。
例:对于a=([‘a’,‘b’],[1,2,3],(4,5,6),(7,8)),可以输出:a,b,1,2,3,4,5,6,7,8
def myDisplay(l):
if isinstance(l,int) or isinstance(l,str): #判断是不是int类型#
print(l)
else:
for i in l:
myDisplay(i)
a=[‘a’,‘b’,1,2,3,(4,5,6),[7,8]]
myDisplay(a)
def mydisplay(tuple_or_list):
b = list(tuple_or_list)
i = 0
list_new0 = []
list_new1 = []
for i in b:
if type(i) ==tuple
c = list(i)
list_new0 += c
list_new1 += list_new0
if type(i) == list:
list_new1 += i
for i in list_new1:
print(i, end='')
mydisplay((['a','b'],[1,2,3],(4,5,6),(7,8)))
42. 写函数myDisplay,将给定的链表或元组中的原子成员全部显示出来,顺序按照字符的两种排序方法显示。
例:对于a=([‘a’,‘b’],[1,2,3],(3,4,5,6),(6,7,8)),可以输出:12345678ab和ab12345678
def mydisplay(tuple_or_list):
b = list(tuple_or_list)
i = 0
list_new0 = []
list_new1 = []
for i in b:
if type(i) == tuple:
c = list(i)
list_new0 += c
list_new1 += list_new0
if type(i) == list:
list_new1 += i
str1 = ''
for i in list_new1:
str1 += str(i)
print(str1[::])
print(str1[::-1])
mydisplay(([3,2],[2,9,5]))
43. 写函数myDisplay,将给定的链表或元组中的原子成员全部显示出来,重复的元素不重复显示,顺序为原来的顺序不变。
例:对于a=([‘a’,‘b’],[1,2,3],(3,4,5,6),(6,7,8)),可以输出:a,b,1,2,3,4,5,6,7,8
def myDisplay(a):
list_a =list()
for i in a:
for j in list(i):
if j not in list_a:
list_a.append(j)
for i in list_a:
print(i,end=" ")
a=(['a','b'],[1,2,3],(3,4,5,6),(6,7,8))
myDisplay(a)
44. 数字理解与测试
1.写程序将用中文描述的数转换为阿拉伯数(数的范围1~99999);
2.创建测试数据,并保存到test.txt中;
如:
一十二
一万
一万零三十
…
3.用2中的测试数据,对1中的程序进行测试;
4.将测试的结果写入到result.txt中。例如:
一十二:12
一万:10000
一万零三十:10030
…
#1
dic_num={"一":1,u"二":2,"三":3,"四":4,
"五":5,"六":6,"七":7,"八":8,"九":9}
dic_unit={"万":10000,"千":1000,"百":100,"十":10}
dic_num={"一":1,u"二":2,"三":3,"四":4,
"五":5,"六":6,"七":7,"八":8,"九":9}
dic_unit={"万":10000,"千":1000,"百":100,"十":10}
def getNum(s):
s=s.replace("零","")
sum=0
for i,v in dic_num.items():
if s[-1]==i:
sum+=v
break
for i,v in dic_num.items():
s=s.replace(i,str(v))
for i,v in dic_unit.items():
index=s.find(i)
if index!=-1:
sum+=int(s[index-1])*v
return sum
3;
f=open("test3.txt","r")
while True:
s=f.readline()
s=s.strip()
if len(s)==0:
break;
print(getNum(s))
4,
dic_num={"一":1,u"二":2,"三":3,"四":4,
"五":5,"六":6,"七":7,"八":8,"九":9}
dic_unit={"万":10000,"千":1000,"百":100,"十":10}
def getNum(s):
s=s.replace("零","")
sum=0
for i,v in dic_num.items():
if s[-1]==i:
sum+=v
break
for i,v in dic_num.items():
s=s.replace(i,str(v))
for i,v in dic_unit.items():
index=s.find(i)
if index!=-1:
sum+=int(s[index-1])*v
return sum
f=open("test3.txt","r")
sumstr=[]
while True:
s=f.readline()
s=s.strip()
if len(s)==0:
break;
sumstr.append(s+":"+str(getNum(s)))
print(sumstr)
f.close()
f=open("result.txt","w")
f.write("\n".join(sumstr))
f.close()
45:与44一样
46. 已知某个食店的各菜品销售数据catering_sale_all.xls。
1.计算各个菜品的相关系数矩阵;
2.计算相关系数最大和最小的值及这两个菜品名称;
3.计算相程度最高和最低的值及这两个菜品名称。
import pandas as pd
# 餐饮数据,含有其他属性
catering_sale = 'D:/catering_sale_all.csv'
# 读取数据,指定'日期'列为索引列
data = pd.read_csv(catering_sale, encoding='GBK')
print("数据矩阵:\n", data)
# 相关系数矩阵,即给出了任意两款菜式之间的相关系数
data_corr = data.corr()
print("相关系数矩阵:\n", data_corr, "\n\n\n\n")
## 计算相关系数的最大值和最小值,并输出它们的菜品名称
print("最大值及菜品名称:")
print(data_corr.max())
print(data_corr.idxmax(), "\n\n\n\n")
print("最小值及菜品名称:")
print(data_corr.min())
print(data_corr.idxmin())
47. 写程序画出正弦函数在【0,2π】 上的图像。
Import numpy as np
Import matplotlib.pyplot as plt
X=np.arrange(0,2*np.pi,0.01)
Y=np.sin(x)
Plt.plot(x,y)
Plt.show()
48. 写程序画出函数 sinx^2在 【0,2π】上的图像。
Import numpy as np
Import matplotlib.pyplot as plt
X=np.arrange(0,2*np.pi,0.01)
Y=np.sin(x)*sin(x)
Plt.plot(x,y)
Plt.show()
49. 已知data.txt内容如下:
1.ace
2.bd
3.bc
4.abcd
5.ab
6.bc
7.ab
8.abce
9.abc
10.ace
写代码完成apiori算法关联规则挖掘的数据预处理。
Import pandas as pd
df=pd.read_excel(“C:\\Users\\ASUS\\Desktop\\1.xlsx”)
df
df.info()
df.dropna()
df.fillna(0)
50. 已知data.txt文件中的数据如下:
2009111518,刘君平,机械设计制造及其自动化,11机制三,男,22,
2012114104,王迪,汽车服务工程,12汽车服务,男,20,
2012114105,韩玉,汽车服务工程,12汽车服务,男,23,
2012114106,何丝雨,汽车服务工程,12汽车服务,男,22,
2012114124,陈姚,汽车服务工程,12汽车服务,女,21,
…
2012126142,高毅,材料科学与工程,12材料,男,20,
2016104136,#,null,null,null,null,
2016104133,李倩,应用统计,应用统计班,女,20,
2016104128,丽娜,应用统计,应用统计班,女,20,
2016104119,王芳,应用统计,应用统计班,女,20,
2016102122,张三,统计,统计班,男,20,
2016096031,李四,统计,统计班,男,20,
2016084022,王五,统计,统计班,男,20,
试生成studentTab.xls,包含标题头Sno,Sname,Subject,className,Sex,Age和data.txt中的数据
import openpyx1
workbook=openpyx1.workbook()
sheet=workbook.active
sheet.title="studentTab.xls"
sheet['A1']="Sno"
sheet['B1']="Sname"
sheet['C1']="Subject"
sheet['D1']="Classname"
sheet['E1']="Sex"
sheet['F1']="Age"
f=open("data.txt","r")
list=f.readlines()
new_list=[]
for number in range(0,len(list),1):
list[number]=list[number].replace("\n","")
list[number+1]=list[number+1].replace("\n","")
if len(list)!=13:
str=list[number]+list[number+1]+list[number+2]
new_list.append(str)
else:
str=list[number]+list[number+1]
new_list.append(str)
for i in new_list:
i=i.split(",")
sheet.append(i[0],i[1],i[2],i[3],i[4],i[5],i[6],i[7])
workbook.save("studentTab.xls")
#3#####################################这种方法好懂一些
from openpyxl import Workbook, load_workbook
book_name_xlsx = r'C:\\Users\\dell\\Desktop\\data.xlsx' # 文件路径,把文档路径复制过来即可
wb = Workbook()
wb.save(book_name_xlsx)
# 打开Excel
wb = load_workbook(book_name_xlsx)
# 创建工作簿,导入的新数据会存在当前excel文件下新建一个‘s’的sheet里
sheet = wb.create_sheet('s')
sheet['A1']="Sno"
sheet['B1']="Sname"
sheet['C1']="Subject"
sheet['D1']="Classname"
sheet['E1']="Sex"
sheet['F1']="Age"
aa = []
f = open(r"C:\\Users\\dell\\Desktop\\data.txt", encoding='utf-8') # 将从文献上的表格数据贴到txt文档中,将txt文档路径复制到此,encoding='utf-8'——编码格式
for line in f.readlines():
data = line.split('\n\t')
for str in data:
sub_str = str.split(',') # 每个数据间是按什么划分的,我的是两个空格符
aa.append(sub_str)
for i in range(len(aa)):
sheet.append(aa[i])
# 保存文件
wb.save(book_name_xlsx)
print("题目写入数据成功!")
**51. 已知data.txt的数据格式如下:
Sno Sname Subject className Sex Age
2009111518 刘君平 机械设计制造及其自动化 11机制三 男 22
2012114104 王迪 汽车服务工程 12汽车服务 男 20
2012114105 韩玉 汽车服务工程 12汽车服务 男 23
2012114106 何丝雨 汽车服务工程 12汽车服务 男 22
2012114107 徐爽 汽车服务工程 12汽车服务 男 21
2012114108 李幸雯 汽车服务工程 12汽车服务 女 20
2016104136 # null null null null
2016104133 李倩 应用统计 应用统计班 女 20
2016104128 丽娜 应用统计 应用统计班 女 20
2016104119 王芳 应用统计 应用统计班 女 20
2016102122 张三 统计 统计班 男 20
2016096031 李四 统计 统计班 男 20
试生成studentTab.xls,包含标题头数据**
import xlwt
import pandas as pd
wb=xlwt.Workbook(encoding='utf-8')
ws=wb.add_sheet('sheet1')
f=open('data.txt',encoding='utf-8')
r=0
for line in f:
line=line.strip('/n')
line=line.split(" ")
print(line)
c=0
l=len(line)
for j in range(l):
print(line[j])
ws.save('data.xls')
r+=1
f.close()
#运行成功的:
from openpyxl import Workbook, load_workbook
book_name_xlsx = r'C:\\Users\\dell\\Desktop\\data.xlsx' # 文件路径,把文档路径复制过来即可
wb = Workbook()
wb.save(book_name_xlsx)
# 打开Excel
wb = load_workbook(book_name_xlsx)
# 创建工作簿,导入的新数据会存在当前excel文件下新建一个‘s’的sheet里
sheet = wb.create_sheet('s')
aa = []
f = open(r"C:\\Users\\dell\\Desktop\\data.txt", encoding='utf-8') # 将从文献上的表格数据贴到txt文档中,将txt文档路径复制到此,encoding='utf-8'——编码格式
for line in f.readlines():
data = line.split('\n\t')
for str in data:
sub_str = str.split(',') # 每个数据间是按什么划分的,我的是两个空格符
aa.append(sub_str)
for i in range(len(aa)):
sheet.append(aa[i])
# 保存文件
wb.save(book_name_xlsx)
print("题目写入数据成功!")
52. 已知d.txt内容如下:
1.ace 11.abce
2.bd 12.bde
3.bc 13.abc
4.abcd 14.abcde
5.ab 15.abe
6.bc 16.abc
7.ab 17.abd
8.abce 18.abce
9.abc 19.abd
10.ace 20.acd
写代码:
(1)计算二项集{a,c}的支持度support;
(2)查找支持度support最高的二项集。
```python
import numpy as np
dataset_filename="data.txt"
x=np.loadtxt(dataset_filename)
n_samples,n_features=x.shape
print("this dataset has {0} samples and {1} features".format(n_samples,n_features)
print(x[:10])
features=["abcde"]
num_ac = 0
for sample in X:
if sample[1] == 1:
num_ac += 1
print("支持度为 ".format(num))