1.sleuth概述
微服务跟踪(sleuth)其实是一个工具,它在整个分布式系统中能跟踪一个用户请求的过程(包括数据采集,数据传输,数据存储,数据分析,数据可视化),捕获这些跟踪数据,就能构建微服务的整个调用链的视图,这是调试和监控微服务的关键工具。
Spring Cloud Sleuth为Spring Cloud的分布式跟踪解决方案提供API。它与OpenZipkin Brave集成
Spring Cloud Sleuth能够跟踪您的请求和消息,以便您可以将该通信与相应的日志条目相关联。您还可以将跟踪信息导出到外部系统以可视化延迟。Spring Cloud Sleuth直接支持OpenZipkin兼容系统。
2.术语
Span(跨度):基本工作单元。例如,发送 RPC 是一个新跨度,就像向 RPC 发送响应一样。跨度还具有其他数据,例如描述、带时间戳的事件、键值注释(标记)、导致它们的时间跨度的 ID 以及进程 ID(通常是 IP 地址)。
跨度可以启动和停止,并且它们会跟踪其计时信息。创建跨度后,必须在将来的某个时间点停止它。
Trace(跟踪):一系列 Span 组成的一个树状结构。请求一个微服务系统的 API 接口, 这个 API 接口,需要调用多个微服务,调用每个微服务都会产生一个新的 Span,所有 由这个请求产生的 Span 组成了这个 Trace。
Annotation/Event(注释/事件):用来及时记录一个事件的,一些核心注解用来定义一个请求的开 始和结束 。这些注解包括以下:
- cs:客户端已发送。客户端已发出请求。此注释指示范围的开始。
- sr:服务器已接收:服务器端已收到请求并开始处理它。从此时间戳中减去时间戳可显示网络延迟。cs
- ss:服务器已发送。在请求处理完成时(当响应发送回客户端时)进行批注。从此时间戳中减去时间戳可显示服务器端处理请求所需的时间。
- cr:收到客户。表示跨度的结束。客户端已成功接收到来自服务器端的响应。从此时间戳中减去时间戳可显示客户端从服务器接收响应所需的全部时间。
2.官方文档
https://docs.spring.io/spring-cloud-sleuth/docs/current/reference/html/getting-started.html#getting-started-terminology
Span 之间的父子关系如下:
3.整合sleuth
1.导入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
2、在配置文件打开 debug 日志
logging:
level:
org.springframework.cloud.openfeign: debug
org.springframework.cloud.sleuth: debug
3、发起一次远程调用,观察控制台
DEBUG [user-service,541450f08573fff5,541450f08573fff5,false]
user-service:服务名
541450f08573fff5:是 TranceId,一条链路中,只有一个 TranceId
541450f08573fff5:是 spanId,链路中的基本工作单元 id
false:表示是否将数据输出到其他服务,true 则会把信息输出到其他可视化的服务上观察
4.整合Zipkin可视化观察
4.1 概述
Zipkin是一个分布式跟踪系统。它有助于收集解决服务体系结构中的延迟问题所需的计时数据。功能包括此数据的收集和查找。
如果日志文件中有跟踪 ID,则可以直接跳转到该 ID。否则,您可以根据服务、操作名称、标签、持续时间等属性进行查询。将为您汇总一些有趣的数据,例如在服务中花费的时间百分比以及操作是否失败。
Zipkin UI 还提供了一个依赖关系图,显示通过每个应用程序跟踪的请求数。这对于识别聚合行为(包括错误路径或对已弃用服务的调用)很有帮助。
应用程序需要“检测”才能向 Zipkin 报告跟踪数据。这通常意味着配置跟踪器或检测库。向 Zipkin 报告数据的最常用方式是通过 HTTP 或 Kafka,尽管存在许多其他选项,例如 Apache ActiveMQ、gRPC 和 RabbitMQ。提供给UI的数据存储在内存中,或者永久存储在受支持的后端(如Apache Cassandra或Elasticsearch)中。
体系结构概述
跟踪器位于您的应用程序中,并记录有关所发生操作的时间和元数据。它们通常对库进行仪器处理,以便它们的使用对用户是透明的。例如,受检测的 Web 服务器记录何时收到请求以及何时发送响应。收集的跟踪数据称为 Span。
仪器被编写为在生产中是安全的,并且开销很小。因此,它们仅在带内传播ID,以告诉接收器有一条正在进行中的跟踪。完成的跨度将报告给 Zipkin 带外,类似于应用程序异步报告指标的方式。
例如,当跟踪操作并且需要发出传出 http 请求时,会添加一些标头来传播 ID。标头不用于发送操作名称等详细信息。
检测应用中向 Zipkin 发送数据的组件称为报告器。报告器通过几种传输之一将跟踪数据发送到 Zipkin 收集器,Zipkin 收集器将跟踪数据保存到存储中。稍后,API 会查询存储以向 UI 提供数据。
4.2 Zipkin官网
https://zipkin.io/pages/quickstart
4.3 下载安装
Docker Zipkin项目能够构建Docker镜像,提供脚本和docker-compose.yml,用于启动预构建的镜像。最快的开始是直接运行最新的映像:
docker run -d -p 9411:9411 openzipkin/zipkin
4.4 整合Zipkin
导入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
添加 zipkin 相关配置
spring:
application:
name: user-service
zipkin:
base-url: http://192.168.56.10:9411/ # zipkin 服务器的地址
# 关闭服务发现,否则 Spring Cloud 会把 zipkin 的 url 当做服务名称
discoveryClientEnabled: false
sender:
type: web # 设置使用 http 的方式传输数据
sleuth:
sampler:
probability: 1 # 设置抽样采集率为 100%,默认为 0.1,即 10%
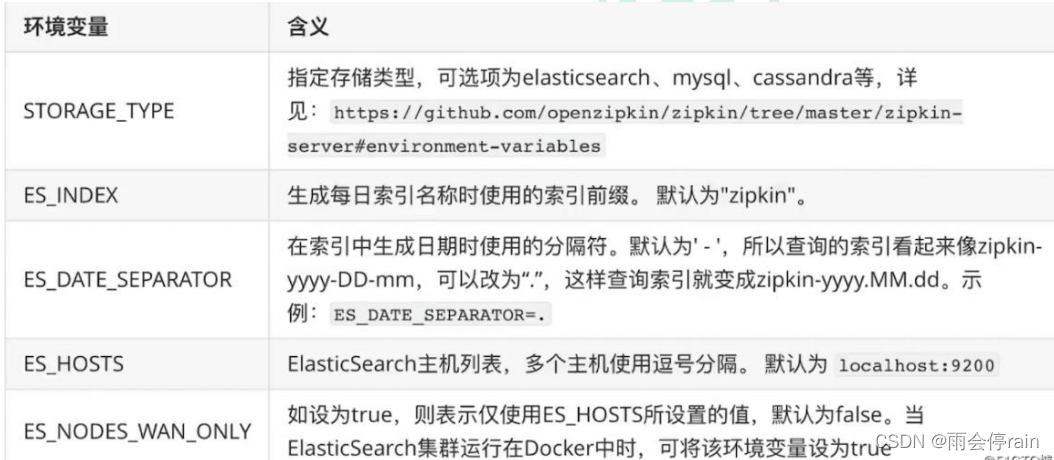
5. Zipkin持久化
Zipkin 默认是将监控数据存储在内存的,如果 Zipkin 挂掉或重启的话,那么监控数据就会丢 失。所以如果想要搭建生产可用的 Zipkin,就需要实现监控数据的持久化。而想要实现数据 持久化,自然就是得将数据存储至数据库。好在 Zipkin 支持将数据存储至:
- 内存(默认)
- MySQL
- Elasticsearch
- Cassandra Zipkin
数据持久化相关的官方文档地址如下:
https://github.com/openzipkin/zipkin#storage-component
Zipkin 支持的这几种存储方式中,内存显然是不适用于生产的,这一点开始也说了。而使用 MySQL 的话,当数据量大时,查询较为缓慢,也不建议使用。Twitter 官方使用的是 Cassandra 作为 Zipkin 的存储数据库,但国内大规模用 Cassandra 的公司较少,而且 Cassandra 相关文 档也不多。
综上,故采用 Elasticsearch 是个比较好的选择,关于使用 Elasticsearch 作为 Zipkin 的存储数 据库的官方文档如下:
elasticsearch-storage:
https://github.com/openzipkin/zipkin/tree/master/zipkin-server#elasticsearch-storage
zipkin-storage/elasticsearch
https://github.com/openzipkin/zipkin/tree/master/zipkin-storage/elasticsearch
通过 docker 的方式
docker run --env STORAGE_TYPE=elasticsearch --env
ES_HOSTS=192.168.56.10:9200 openzipkin/zipkin-dependencies

使用 es 时 Zipkin Dependencies 支持的环境变量