储备知识—IOU
定义
在目标检测的评价体系中,有一个参数叫做 IoU ,简单来讲就是模型预测的目标窗口和原来标记窗口的交叠率。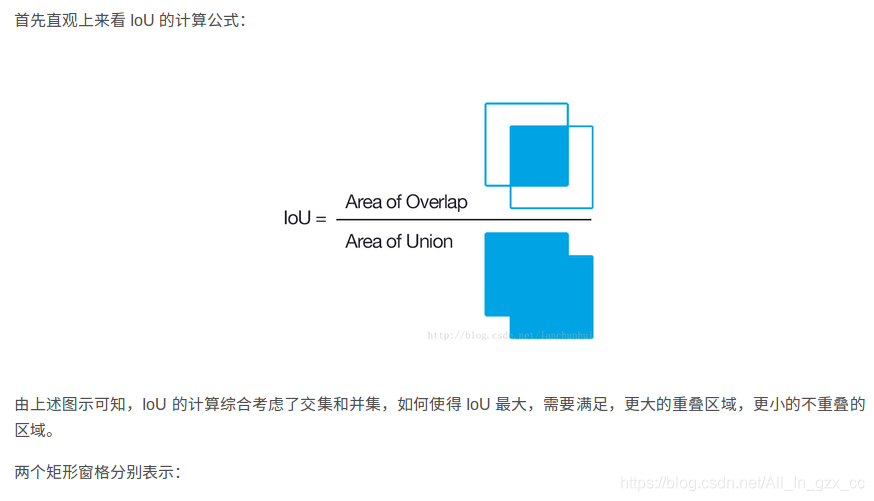
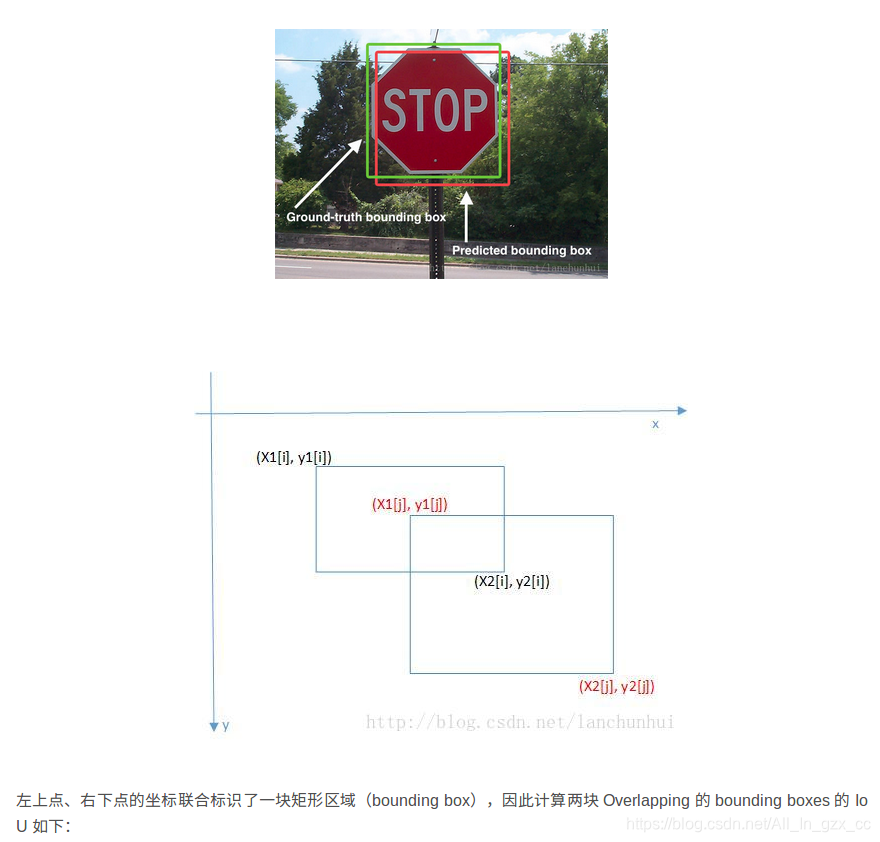
# ((x1[i], y1[i]), (x2[i], y2[i]))
areai = (x2[i]-x1[i]+1)*(y2[i]-y1[i]+1)
areaj = (x2[j]-x1[j]+1)*(y2[j]-y1[j]+1)
xx1 = max(x1[i], x1[j])
yy1 = max(y1[i], y1[j])
xx2 = min(x2[i], x2[j])
yy2 = min(y2[i], y2[j])
h = max(0, yy2-yy1+1)
w = max(0, xx2-xx1+1)
intersection = w * h#相交的面积
iou = intersection / (areai + areaj - intersection)#(2面积之和-相交面积)
参考 https://blog.csdn.net/lanchunhui/article/details/71190055
NMS
应用背景
非极大值抑制(NMS)非极大值抑制顾名思义就是抑制不是极大值的元素,搜索局部的极大值。
例如在对象检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分类及分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。这时就需要用到NMS来选取那些邻域里分数最高(是某类对象的概率最大),并且抑制那些分数低的窗口。
理论介绍
在物体检测中NMS(Non-maximum suppression)非极大抑制应用十分广泛,其目的是为了消除多余的框,找到最佳的物体检测的位置。
在RCNN系列算法中,会从一张图片中找出很多个候选框(可能包含物体的矩形边框),然后为每个矩形框为做类别分类概率
就像上面的图片一样,定位一个车辆,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。
非极大值抑制:先假设有6个候选框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A、B、C、D、E、F。
1、从最大概率矩形框(即面积最大的框)F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
2、假设B、D与F的重叠度超过阈值,那么就扔掉B、D(因为超过阈值,说明D与F或者B与F,已经有很大部分是重叠的,那我们保留面积最大的F即可,其余小面积的B,D就是多余的,用F完全可以表示一个物体了,所以保留F丢掉B,D);并标记第一个矩形框F,是我们保留下来的。
3、从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
4、一直重复这个过程,找到所有曾经被保留下来的矩形框。
算法流程
NMS 对检测得到的全部 boxes 进行局部的最大搜索,以搜索某邻域范围内的最大值,从而滤出一部分 boxes,提升最终的检测精度.
NMS :
- 输入:检测到的Boxes(同一个物体可能被检测到很多Boxes,每个box均有分类score)
- 输出:最优的Box.
- 过程:去除冗余的重叠 Boxes,对全部的 Boxes 进行 迭代-遍历-消除.
将所有框的得分排序,选中最高分及其对应的框;
遍历其余的框,如果和当前最高分框的重叠面积(IOU)大于一定阈值,则将框删除;
从未处理的框中继续选一个得分最高的,重复上述过程.
具体示例及代码
假设某物体检测到 4 个 Boxes,每个 Box 分别对应一个类别 Score,根据 Score 从小到大排列依次为,(B1, S1), (B2, S2), (B3, S3), (B4, S4). S4 > S3 > S2 > S1.
- Step 1. 根据Score 大小,从 Box B4 框开始;
- Step 2. 分别计算 B1, B2, B3 与 B4 的重叠程度 IoU,判断是否大于预设定的阈值;如果大于设定阈值,则舍弃该
Box;同时标记保留的 Box. 假设 B3 与 B4 的阈值超过设定阈值,则舍弃 B3,标记 B4 为要保留的 Box; - Step 3. 从剩余的 Boxes 中 B1, B2 中选取 Score 最大的 B2, 然后计算 B2 与 剩余的 B1 的重叠程度
IoU;如果大于设定阈值,同样丢弃该 Box;同时标记保留的 Box. - 重复以上过程,直到找到全部的保留 Boxes.
# --------------------------------------------------------
# Fast R-CNN
# Copyright (c) 2015 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ross Girshick
# --------------------------------------------------------
import numpy as np
# dets: 检测的 boxes 及对应的 scores;
# thresh: 设定的阈值
def nms(dets, thresh):
# boxes 位置
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
# boxes scores
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1) # 各 box 的面积
order = scores.argsort()[::-1] # boxes 的按照 score 排序
keep = [] # 记录保留下的 boxes
while order.size > 0:
i = order[0] # score 最大的 box 对应的 index
keep.append(i) # 将本轮 score 最大的 box 的 index 保留
# 计算剩余 boxes 与当前 box 的重叠程度 IoU
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1) # IoU
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter)
# 保留 IoU 小于设定阈值的 boxes
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1]
return keep
参考https://blog.csdn.net/shuzfan/article/details/52711706