
1.动态注意网络(DCN):

1.1 encoder
查询术语序列向量表示(GloVe): (x xxQ ^QQ1 _11,x xxQ ^QQ2 _22,…,x xxQ ^QQn _nn)
文档术语序列向量表示(GloVe):(x xxD ^DD1 _11,x xxD ^DD2 _22,…,x xxD ^DDm _mm)
使用LSTM编码文档:d ddt _tt=L LLS SST TTM MMe _een _nnc _cc(d ddt _tt− _-−1 _11,x xxD ^DDt _tt)。文档编码矩阵:D DD = [d 1 d_1d1…d m d_mdm,d ∅ d_∅d∅] ∈ R RRl ^ll× ^××( ^((m ^mm+ ^++1 ^11) ^))。d ∅ d_∅d∅为哨兵向量,它允许模型不关注输入中的任何特定单词。
question编码:q qqt _tt=L LLS SST TTM MMe _een _nnc _cc(q qqt _tt− _-−1 _11,x xxQ ^QQt _tt)。question编码矩阵:Q QQ’ ^’’= [q 1 q_1q1…q n q_nqn,q ∅ q_∅q∅] ∈ R RRl ^ll× ^××( ^((n ^nn+ ^++1 ^11) ^)),考虑到question编码空间和文档编码空间之间的差异,引入了非线性投影层映射question: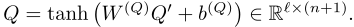
1.2coattention encoder

1.计算相似度矩阵: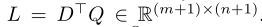
2.document-to-question (行)注意力权重A AAQ ^QQ: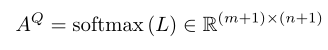
3.question-to-document(列)注意力权重A D A^DAD: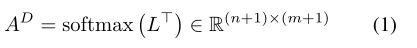
4.接下来,根据question的每个单词计算文档的摘要或注意上下文:
5.同样根据文档中的每个单词来计算问题的摘要:C D C^DCD = Q QQA AAD ^DD,还根据文档中的每个单词计算先前注意上下文的摘要C Q C^QCQA AAD ^DD。这两个操作可以并行完成: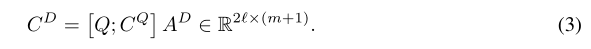
6.最后的C D C^DCD就为共同感知的question和document表示,然后通过bi-lstm融合时间信息: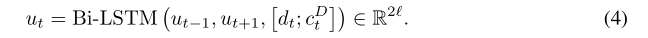
所以有:
这为选择哪个跨度可能是最好的可能答案提供了基础。
1.3动态指向解码器
给定一个问题-文档对,文档中可能存在几个直观的答案区间,每个对应于一个局部最大值。本文提出了一种迭代技术,通过在预测起点和预测终点之间交替来选择答案跨度。如图三所示 它类似于一个状态机,其状态由基于LSTM的顺序模型来维护。在每次迭代期间,解码器考虑到对应于开始和结束位置的当前估计的潜在编码来更新其状态,并通过多层神经网络产生开始和结束位置的新估计。让h i h_ihi、s i s_isi和e i e_iei分别表示为迭代i ii期间LSTM的隐藏状态、初始位置的估计和结束位置的估计。然后LSTM状态更新为:
它类似于一个状态机,其状态由基于LSTM的顺序模型来维护。在每次迭代期间,解码器考虑到对应于开始和结束位置的当前估计的潜在编码来更新其状态,并通过多层神经网络产生开始和结束位置的新估计。让h i h_ihi、s i s_isi和e i e_iei分别表示为迭代i ii期间LSTM的隐藏状态、初始位置的估计和结束位置的估计。然后LSTM状态更新为: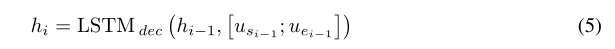
其中u uus _ssi _ii− _-−1 _11和u uue _eei _ii− _-−1 _11是对应于前一次估计的编码u uu的开始和结束位置的表示,给定当前隐藏状态h i h_ihi、先前开始位置u uus _ssi _ii− _-−1 _11和先前结束位置u uue _eei _ii− _-−1 _11,我们估计当前开始位置和结束位置: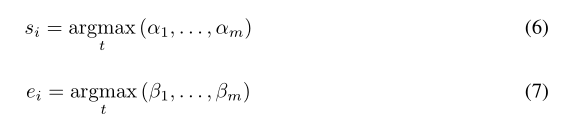
其中α αα和β ββ代表对应于文档中第一个单词的开始分数和结束分数。用单独的神经网络计算α αα和β ββ。这些网络具有相同的体系结构,但不共享参数。
本文提出了Highway Maxout Network (HMN)来计算由等式描述的α αα和β ββ: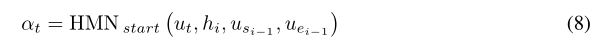
这里,u uut _tt对应于文档中第t tt个单词的字符编码。结束分数β t β_tβt的计算类似于开始分数α t α_tαt,但使用单独的H HHM MMN NNe _een _nnd _dd。
HMN模型:
结果
SQuAD:
1.DCN
EM:66.2 F1:75.9
2.BiDAF:
EM:73.3 F1: 81.1
BiDAF的双向attention
1.建立相似度矩阵S SS∈R RRT ^TT× ^××J ^JJ(H HH:context(T TT长) U UU:question(J JJ长)):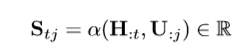
2.Context-to-query Attention.:
a aat _tt = softmax(S t S_tSt: _::)∈R J R^JRJ
U ’ U^’U’=a aaU UU∈R RRd ^dd× ^××T ^TT
3.Query-to-context Attention:
b bb = softmax(m mma aax xxc _cco _ool _ll(S SS)) ∈ R T R^TRT
H ’ H^’H’=b bbH HH∈R RRd ^dd
最后扩展为T TT行: H ’ H^’H’∈R RRd ^dd× ^××T ^TT
4.融合上下文: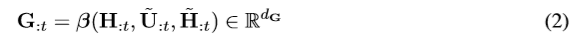
β ββ计算为: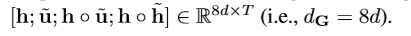

model

encoder
1.300维的GloVe+200维的char。
2.连接送入两层高速公路网络
Embedding Encoder Layer
上图右:
总共一个block:[convolution-layer×n nn + self-attention-layer + feed-forward-layer]
Context-Query Attention Layer
1.构建相似度矩阵(方法同BiDAF)
2.计算attention(方法同DCN)
Model Encoder Layer
3个Model encoder block ,每个Model encoder block 由7个encoder block堆叠而成。
output layer
与BiDAF相同
结果
速度更快,EM/F1更高。