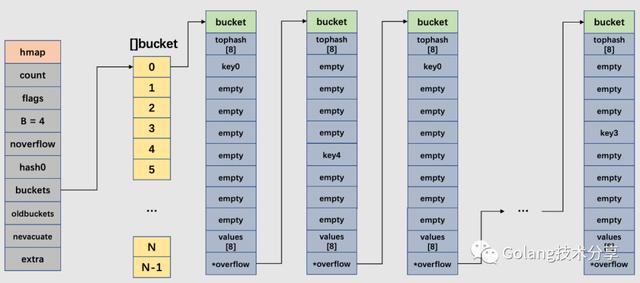
map扩容
在文中讲解装载因子时,我们提到装载因子是决定哈希表是否进行扩容的关键指标。在go的map扩容中,除了装载因子会决定是否需要扩容,溢出桶的数量也是扩容的另一关键指标。
为了保证访问效率,当map将要添加、修改或删除key时,都会检查是否需要扩容,扩容实际上是以空间换时间的手段。在之前源码mapassign中,其实已经注释map扩容条件,主要是两点:
- 判断已经达到装载因子的临界点,即元素个数 >= 桶(bucket)总数 * 6.5,这时候说明大部分的桶可能都快满了(即平均每个桶存储的键值对达到6.5个),如果插入新元素,有大概率需要挂在溢出桶(overflow bucket)上。
func overLoadFactor(count int, B uint8) bool { return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)}- 判断溢出桶是否太多,当桶总数 < 2 ^ 15 时,如果溢出桶总数 >= 桶总数,则认为溢出桶过多。当桶总数 >= 2 ^ 15 时,直接与 2 ^ 15 比较,当溢出桶总数 >= 2 ^ 15 时,即认为溢出桶太多了。
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool { if B > 15 { B = 15 } return noverflow >= uint16(1)<对于第2点,其实算是对第 1 点的补充。因为在装载因子比较小的情况下,有可能 map 的查找和插入效率也很低,而第 1 点识别不出来这种情况。表面现象就是计算装载因子的分子比较小,即 map 里元素总数少,但是桶数量多(真实分配的桶数量多,包括大量的溢出桶)。
在某些场景下,比如不断的增删,这样会造成overflow的bucket数量增多,但负载因子又不高,未达不到第 1 点的临界值,就不能触发扩容来缓解这种情况。这样会造成桶的使用率不高,值存储得比较稀疏,查找插入效率会变得非常低,因此有了第 2 点判断指标。这就像是一座空城,房子很多,但是住户很少,都分散了,找起人来很困难。
如上图所示,由于对map的不断增删,以0号bucket为例,该桶链中就造成了大量的稀疏桶。
两种情况官方采用了不同的解决方案
- 针对 1,将 B + 1,新建一个buckets数组,新的buckets大小是原来的2倍,然后旧buckets数据搬迁到新的buckets。该方法我们称之为增量扩容。
- 针对 2,并不扩大容量,buckets数量维持不变,重新做一遍类似增量扩容的搬迁动作,把松散的键值对重新排列一次,以使bucket的使用率更高,进而保证更快的存取。该方法我们称之为等量扩容。
对于 2 的解决方案,其实存在一个极端的情况:如果插入 map 的 key 哈希都一样,那么它们就会落到同一个 bucket 里,超过 8 个就会产生 overflow bucket,结果也会造成 overflow bucket 数过多。移动元素其实解决不了问题,因为这时整个哈希表已经退化成了一个链表,操作效率变成了 O(n)。但 Go 的每一个 map 都会在初始化阶段的 makemap时定一个随机的哈希种子,所以要构造这种冲突是没那么容易的。
在源码中,和扩容相关的主要是hashGrow()函数与growWork()函数。hashGrow() 函数实际上并没有真正地“搬迁”,它只是分配好了新的 buckets,并将老的 buckets 挂到了 oldbuckets 字段上。真正搬迁 buckets 的动作在 growWork() 函数中,而调用 growWork() 函数的动作是在mapassign() 和 mapdelete() 函数中。也就是插入(包括修改)、删除 key 的时候,都会尝试进行搬迁 buckets 的工作。它们会先检查 oldbuckets 是否搬迁完毕(检查 oldbuckets 是否为 nil),再决定是否进行搬迁工作。
hashGrow()函数
func hashGrow(t *maptype, h *hmap) { // 如果达到条件 1,那么将B值加1,相当于是原来的2倍 // 否则对应条件 2,进行等量扩容,所以 B 不变 bigger := uint8(1) if !overLoadFactor(h.count+1, h.B) { bigger = 0 h.flags |= sameSizeGrow } // 记录老的buckets oldbuckets := h.buckets // 申请新的buckets空间 newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil) // 注意&^ 运算符,这块代码的逻辑是转移标志位 flags := h.flags &^ (iterator | oldIterator) if h.flags&iterator != 0 { flags |= oldIterator } // 提交grow (atomic wrt gc) h.B += bigger h.flags = flags h.oldbuckets = oldbuckets h.buckets = newbuckets // 搬迁进度为0 h.nevacuate = 0 // overflow buckets 数为0 h.noverflow = 0 // 如果发现hmap是通过extra字段 来存储 overflow buckets时 if h.extra != nil && h.extra.overflow != nil { if h.extra.oldoverflow != nil { throw("oldoverflow is not nil") } h.extra.oldoverflow = h.extra.overflow h.extra.overflow = nil } if nextOverflow != nil { if h.extra == nil { h.extra = new(mapextra) } h.extra.nextOverflow = nextOverflow }}growWork()函数
func growWork(t *maptype, h *hmap, bucket uintptr) { // 为了确认搬迁的 bucket 是我们正在使用的 bucket // 即如果当前key映射到老的bucket1,那么就搬迁该bucket1。 evacuate(t, h, bucket&h.oldbucketmask()) // 如果还未完成扩容工作,则再搬迁一个bucket。 if h.growing() { evacuate(t, h, h.nevacuate) }}从growWork()函数可以知道,搬迁的核心逻辑是evacuate()函数。这里读者可以思考一个问题:为什么每次至多搬迁2个bucket?这其实是一种性能考量,如果map存储了数以亿计的key-value,一次性搬迁将会造成比较大的延时,因此才采用逐步搬迁策略。
在讲解该逻辑之前,需要读者先理解以下两个知识点。
- 知识点1:bucket序号的变化
前面讲到,增量扩容(条件1)和等量扩容(条件2)都需要进行bucket的搬迁工作。对于等量扩容而言,由于buckets的数量不变,因此可以按照序号来搬迁。例如老的的0号bucket,仍然搬至新的0号bucket中。

但是,对于增量扩容而言,就会有所不同。例如原来的B=5,那么增量扩容时,B就会变成6。那么决定key值落入哪个bucket的低位哈希值就会发生变化(从取5位变为取6位),取新的低位hash值得过程称为rehash。
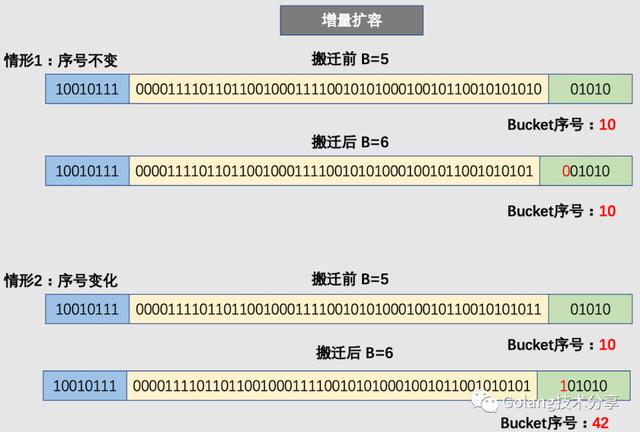
因此,在增量扩容中,某个 key 在搬迁前后 bucket 序号可能和原来相等,也可能是相比原来加上 2^B(原来的 B 值),取决于低 hash 值第倒数第B+1位是 0 还是 1。
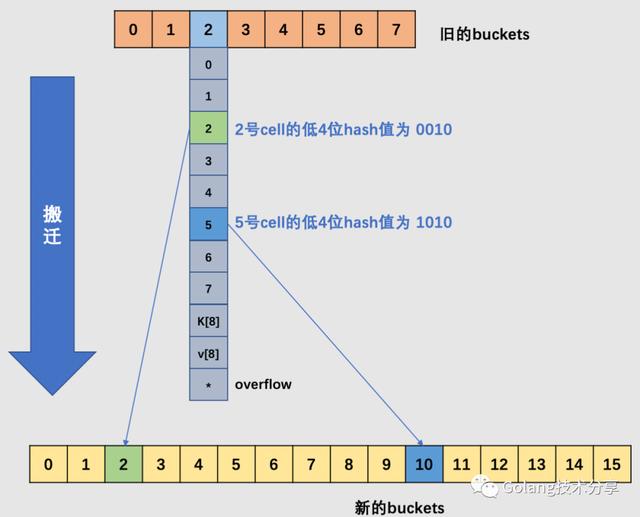
如上图所示,当原始的B = 3时,旧buckets数组长度为8,在编号为2的bucket中,其2号cell和5号cell,它们的低3位哈希值相同(不相同的话,也就不会落在同一个桶中了),但是它们的低4位分别是0010、1010。当发生了增量扩容,2号就会被搬迁到新buckets数组的2号bucket中去,5号被搬迁到新buckets数组的10号bucket中去,它们的桶号差距是2的3次方。
- 知识点2:确定搬迁区间
在源码中,有bucket x 和bucket y的概念,其实就是增量扩容到原来的 2 倍,桶的数量是原来的 2 倍,前一半桶被称为bucket x,后一半桶被称为bucket y。一个 bucket 中的 key 可能会分裂到两个桶中去,分别位于bucket x的桶,或bucket y中的桶。所以在搬迁一个 cell 之前,需要知道这个 cell 中的 key 是落到哪个区间(而对于同一个桶而言,搬迁到bucket x和bucket y桶序号的差别是老的buckets大小,即2^old_B)。
这里留一个问题:为什么确定key落在哪个区间很重要?
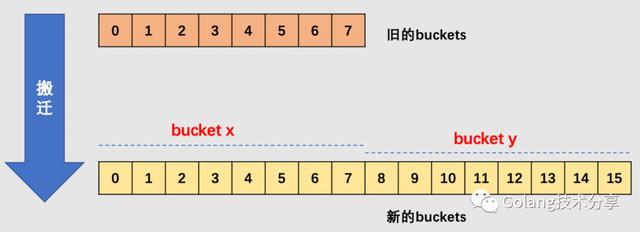
确定了要搬迁到的目标 bucket 后,搬迁操作就比较好进行了。将源 key/value 值 copy 到目的地相应的位置。设置 key 在原始 buckets 的 tophash 为 evacuatedX 或是 evacuatedY,表示已经搬迁到了新 map 的bucket x或是bucket y,新 map 的 tophash 则正常取 key 哈希值的高 8 位。
下面正式解读搬迁核心代码evacuate()函数。
evacuate()函数
func evacuate(t *maptype, h *hmap, oldbucket uintptr) { // 首先定位老的bucket的地址 b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))) // newbit代表扩容之前老的bucket个数 newbit := h.noldbuckets() // 判断该bucket是否已经被搬迁 if !evacuated(b) { // 官方TODO,后续版本也许会实现 // TODO: reuse overflow buckets instead of using new ones, if there // is no iterator using the old buckets. (If !oldIterator.) // xy 包含了高低区间的搬迁目的地内存信息 // x.b 是对应的搬迁目的桶 // x.k 是指向对应目的桶中存储当前key的内存地址 // x.e 是指向对应目的桶中存储当前value的内存地址 var xy [2]evacDst x := &xy[0] x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize))) x.k = add(unsafe.Pointer(x.b), dataOffset) x.e = add(x.k, bucketCnt*uintptr(t.keysize)) // 只有当增量扩容时才计算bucket y的相关信息(和后续计算useY相呼应) if !h.sameSizeGrow() { y := &xy[1] y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize))) y.k = add(unsafe.Pointer(y.b), dataOffset) y.e = add(y.k, bucketCnt*uintptr(t.keysize)) } // evacuate 函数每次只完成一个 bucket 的搬迁工作,因此要遍历完此 bucket 的所有的 cell,将有值的 cell copy 到新的地方。 // bucket 还会链接 overflow bucket,它们同样需要搬迁。 // 因此同样会有 2 层循环,外层遍历 bucket 和 overflow bucket,内层遍历 bucket 的所有 cell。 // 遍历当前桶bucket和其之后的溢出桶overflow bucket // 注意:初始的b是待搬迁的老bucket for ; b != nil; b = b.overflow(t) { k := add(unsafe.Pointer(b), dataOffset) e := add(k, bucketCnt*uintptr(t.keysize)) // 遍历桶中的cell,i,k,e分别用于对应tophash,key和value for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) { top := b.tophash[i] // 如果当前cell的tophash值是emptyOne或者emptyRest,则代表此cell没有key。并将其标记为evacuatedEmpty,表示它“已经被搬迁”。 if isEmpty(top) { b.tophash[i] = evacuatedEmpty continue } // 正常不会出现这种情况 // 未被搬迁的 cell 只可能是emptyOne、emptyRest或是正常的 top hash(大于等于 minTopHash) if top < minTopHash { throw("bad map state") } k2 := k // 如果 key 是指针,则解引用 if t.indirectkey() { k2 = *((*unsafe.Pointer)(k2)) } var useY uint8 // 如果是增量扩容 if !h.sameSizeGrow() { // 计算哈希值,判断当前key和vale是要被搬迁到bucket x还是bucket y hash := t.hasher(k2, uintptr(h.hash0)) if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) { // 有一个特殊情况:有一种 key,每次对它计算 hash,得到的结果都不一样。 // 这个 key 就是 math.NaN() 的结果,它的含义是 not a number,类型是 float64。 // 当它作为 map 的 key时,会遇到一个问题:再次计算它的哈希值和它当初插入 map 时的计算出来的哈希值不一样! // 这个 key 是永远不会被 Get 操作获取的!当使用 m[math.NaN()] 语句的时候,是查不出来结果的。 // 这个 key 只有在遍历整个 map 的时候,才能被找到。 // 并且,可以向一个 map 插入多个数量的 math.NaN() 作为 key,它们并不会被互相覆盖。 // 当搬迁碰到 math.NaN() 的 key 时,只通过 tophash 的最低位决定分配到 X part 还是 Y part(如果扩容后是原来 buckets 数量的 2 倍)。如果 tophash 的最低位是 0 ,分配到 X part;如果是 1 ,则分配到 Y part。 useY = top & 1 top = tophash(hash) // 对于正常key,进入以下else逻辑 } else { if hash&newbit != 0 { useY = 1 } } } if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY { throw("bad evacuatedN") } // evacuatedX + 1 == evacuatedY b.tophash[i] = evacuatedX + useY // useY要么为0,要么为1。这里就是选取在bucket x的起始内存位置,或者选择在bucket y的起始内存位置(只有增量同步才会有这个选择可能)。 dst := &xy[useY] // 如果目的地的桶已经装满了(8个cell),那么需要新建一个溢出桶,继续搬迁到溢出桶上去。 if dst.i == bucketCnt { dst.b = h.newoverflow(t, dst.b) dst.i = 0 dst.k = add(unsafe.Pointer(dst.b), dataOffset) dst.e = add(dst.k, bucketCnt*uintptr(t.keysize)) } dst.b.tophash[dst.i&(bucketCnt-1)] = top // 如果待搬迁的key是指针,则复制指针过去 if t.indirectkey() { *(*unsafe.Pointer)(dst.k) = k2 // copy pointer // 如果待搬迁的key是值,则复制值过去 } else { typedmemmove(t.key, dst.k, k) // copy elem } // value和key同理 if t.indirectelem() { *(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e) } else { typedmemmove(t.elem, dst.e, e) } // 将当前搬迁目的桶的记录key/value的索引值(也可以理解为cell的索引值)加一 dst.i++ // 由于桶的内存布局中在最后还有overflow的指针,多以这里不用担心更新有可能会超出key和value数组的指针地址。 dst.k = add(dst.k, uintptr(t.keysize)) dst.e = add(dst.e, uintptr(t.elemsize)) } } // 如果没有协程在使用老的桶,就对老的桶进行清理,用于帮助gc if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 { b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)) // 只清除bucket 的 key,value 部分,保留 top hash 部分,指示搬迁状态 ptr := add(b, dataOffset) n := uintptr(t.bucketsize) - dataOffset memclrHasPointers(ptr, n) } } // 用于更新搬迁进度 if oldbucket == h.nevacuate { advanceEvacuationMark(h, t, newbit) }}func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) { // 搬迁桶的进度加一 h.nevacuate++ // 实验表明,1024至少会比newbit高出一个数量级(newbit代表扩容之前老的bucket个数)。所以,用当前进度加上1024用于确保O(1)行为。 stop := h.nevacuate + 1024 if stop > newbit { stop = newbit } // 计算已经搬迁完的桶数 for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) { h.nevacuate++ } // 如果h.nevacuate == newbit,则代表所有的桶都已经搬迁完毕 if h.nevacuate == newbit { // 搬迁完毕,所以指向老的buckets的指针置为nil h.oldbuckets = nil // 在讲解hmap的结构中,有过说明。如果key和value均不包含指针,则都可以inline。 // 那么保存它们的buckets数组其实是挂在hmap.extra中的。所以,这种情况下,其实我们是搬迁的extra的buckets数组。 // 因此,在这种情况下,需要在搬迁完毕后,将hmap.extra.oldoverflow指针置为nil。 if h.extra != nil { h.extra.oldoverflow = nil } // 最后,清除正在扩容的标志位,扩容完毕。 h.flags &^= sameSizeGrow }}代码比较长,但是文中注释已经比较清晰了,如果对map的扩容还不清楚,可以参见以下图解。
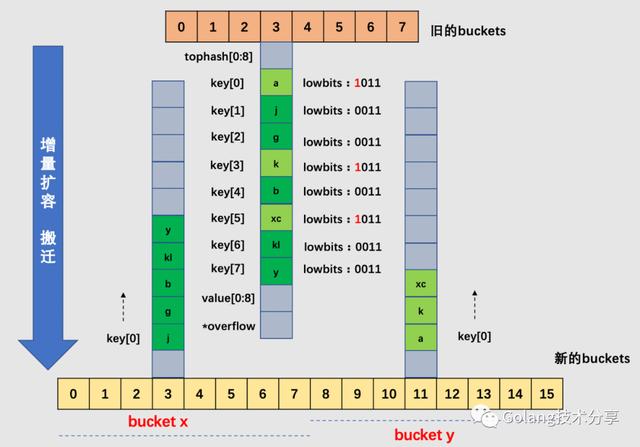
针对上图的map,其B为3,所以原始buckets数组为8。当map元素数变多,加载因子超过6.5,所以引起了增量扩容。
以3号bucket为例,可以看到,由于B值加1,所以在新选取桶时,需要取低4位哈希值,这样就会造成cell会被搬迁到新buckets数组中不同的桶(3号或11号桶)中去。注意,在一个桶中,搬迁cell的工作是有序的:它们是依序填进对应新桶的cell中去的。
当然,实际情况中3号桶很可能还有溢出桶,在这里为了简化绘图,假设3号桶没有溢出桶,如果有溢出桶,则相应地添加到新的3号桶和11号桶中即可,如果对应的3号和11号桶均装满,则给新的桶添加溢出桶来装载。
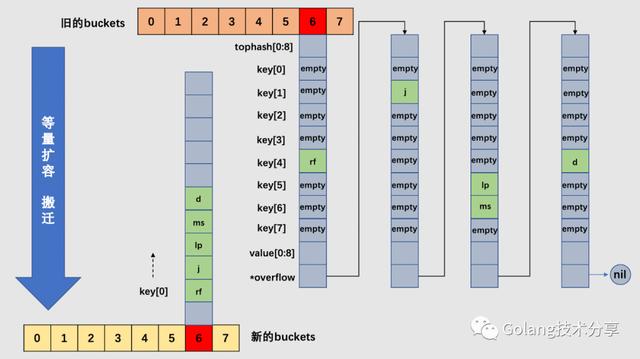
对于上图的map,其B也为3。假设整个map中的overflow过多,触发了等量扩容。注意,等量扩容时,新的buckets数组大小和旧buckets数组是一样的。
以6号桶为例,它有一个bucket和3个overflow buckets,但是我们能够发现桶里的数据非常稀疏,等量扩容的目的就是为了把松散的键值对重新排列一次,以使bucket的使用率更高,进而保证更快的存取。搬迁完毕后,新的6号桶中只有一个基础bucket,暂时并不需要溢出桶。这样,和原6号桶相比,数据变得紧密,使后续的数据存取变快。
最后回答一下上文中留下的问题:为什么确定key落在哪个区间很重要?因为对于增量扩容而言,原本一个bucket中的key会被分裂到两个bucket中去,它们分别处于bucket x和bucket y中,但是它们之间存在关系 bucket x + 2^B = bucket y (其中,B是老bucket对应的B值)。假设key所在的老bucket序号为n,那么如果key落在新的bucket x,则它应该置入 bucket x起始位置 + n*bucket 的内存中去;如果key落在新的bucket y,则它应该置入 bucket y起始位置 + n*bucket的内存中去。因此,确定key落在哪个区间,这样就很方便进行内存地址计算,快速找到key应该插入的内存地址。
总结
Go语言的map,底层是哈希表实现的,通过链地址法解决哈希冲突,它依赖的核心数据结构是数组加链表。
map中定义了2的B次方个桶,每个桶中能够容纳8个key。根据key的不同哈希值,将其散落到不同的桶中。哈希值的低位(哈希值的后B个bit位)决定桶序号,高位(哈希值的前8个bit位)标识同一个桶中的不同 key。
当向桶中添加了很多 key,造成元素过多,超过了装载因子所设定的程度,或者多次增删操作,造成溢出桶过多,均会触发扩容。
扩容分为增量扩容和等量扩容。增量扩容,会增加桶的个数(增加一倍),把原来一个桶中的 keys 被重新分配到两个桶中。等量扩容,不会更改桶的个数,只是会将桶中的数据变得紧凑。不管是增量扩容还是等量扩容,都需要创建新的桶数组,并不是原地操作的。
扩容过程是渐进性的,主要是防止一次扩容需要搬迁的 key 数量过多,引发性能问题。触发扩容的时机是增加了新元素, 桶搬迁的时机则发生在赋值、删除期间,每次最多搬迁两个 桶。查找、赋值、删除的一个很核心的内容是如何定位到 key 所在的位置,需要重点理解。一旦理解,关于 map 的源码就可以看懂了。
使用建议
从map设计可以知道,它并不是一个并发安全的数据结构。同时对map进行读写时,程序很容易出错。因此,要想在并发情况下使用map,请加上锁(sync.Mutex或者sync.RwMutex)。其实,Go标准库中已经为我们实现了并发安全的map——sync.Map,我之前写过文章对它的实现进行讲解,详情可以查看公号:Golang技术分享——《深入理解sync.Map》一文。
遍历map的结果是无序的,在使用中,应该注意到该点。
通过map的结构体可以知道,它其实是通过指针指向底层buckets数组。所以和slice一样,尽管go函数都是值传递,但是,当map作为参数被函数调用时,在函数内部对map的操作同样会影响到外部的map。
另外,有个特殊的key值math.NaN,它每次生成的哈希值是不一样的,这会造成m[math.NaN]是拿不到值的,而且多次对它赋值,会让map中存在多个math.NaN的key。不过这个基本用不到,知道有这个特殊情况就可以了。
参考链接
https://en.wikipedia.org/wiki/Associative_array
https://blog.golang.org/maps
https://mp.weixin.qq.com/s/OHROn0ya_nWR6qkaSFmacw
https://www.cse.cuhk.edu.hk/irwin.king/_media/teaching/csc2100b/tu6.pdf
https://github.com/cch123/golang-notes/blob/master/map.md
https://zhuanlan.zhihu.com/p/66676224
https://draveness.me/golang/docs/part2-foundation/ch03-datastructure/golang-hashmap/
https://github.com/talkgo/night/issues/332
https://my.oschina.net/renhc/blog/2208417