原文地址:https://dreamhomes.github.io/posts/202007261112.html
背景
现实中的复杂系统大体可以抽象为两类:第一类是同质信息网络(Homogeneous
information network),这种建模方法仅抽取网络中部分信息并且没有区分对象或者关系间的差异性;第二类是异质信息网络(Heterogeneous information network),网络中包含多种类型的关系和对象,具有全面的结构信息和丰富的语义信息。
目前同质信息网络中节点排序方法较多且应用较广,例如Personalized PageRank ,其计算公式如下所示:
P P R q = ( 1 − α ) M T × P P R q + α q \mathbf{P P R}_{q}=(1-\alpha) M^{T} \times \mathbf{P P R}_{q}+\alpha \mathbf{q}PPRq=(1−α)MT×PPRq+αq
但是其不适用于异质信息网络。因此介绍当前的两种适用于异质信息网络中节点排序的方法 ObjectRank和PopRank,主要思想借鉴PageRank。
ObjectRank
ObjectRank 主要用于数据库中查询内容,根据输入的关键字对内容进行排序输出。
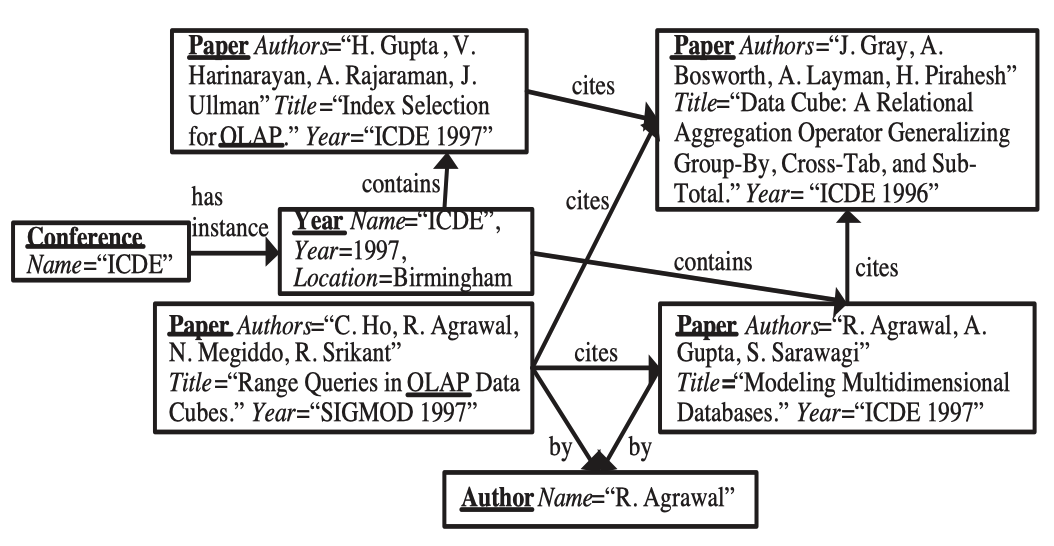
以 DBLP 数据库说明下术语及其含义,并给出算法过程。
- Label / Data Graph
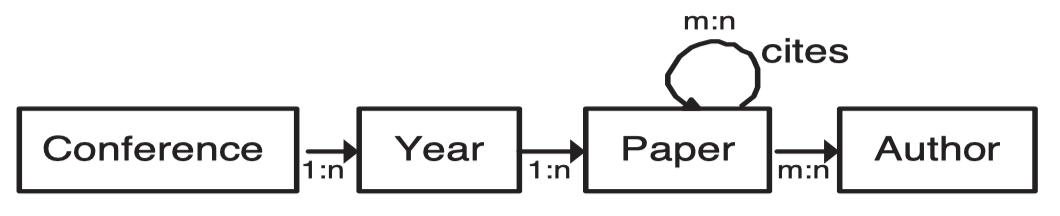
- Schema Graph
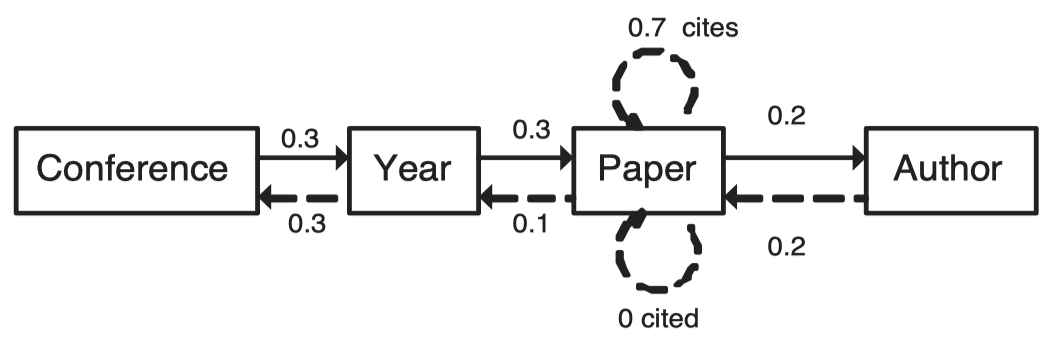
- Authority transfer schema graph
- Authority Transfer Data Graph
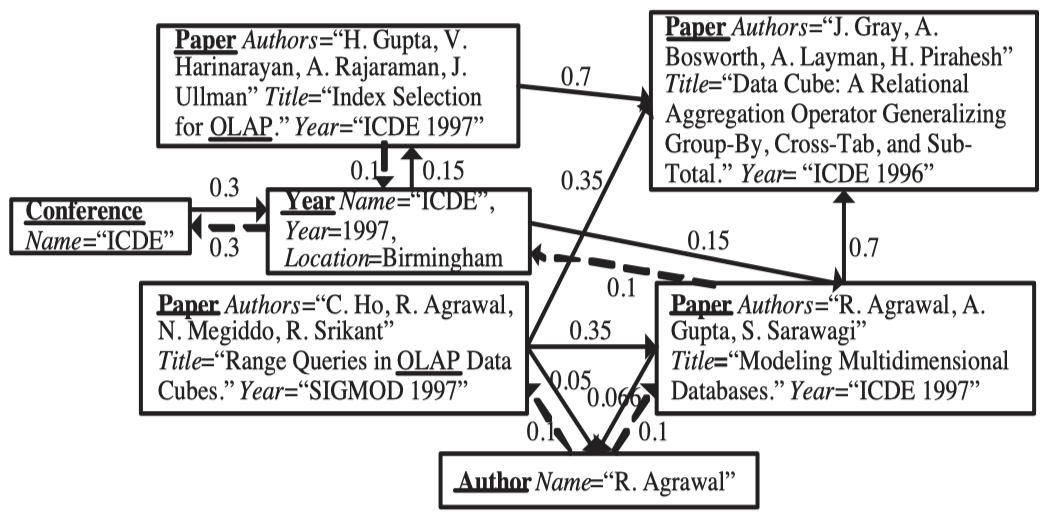
- 对于关键字 “OLAP” 的查询结果

算法过程
以给定的模式图(Schema Graph) G ( V G , E G ) G(V_G, E_G)G(VG,EG) 来建模复杂系统,每个对象包含多个属性-值对。根据模式图需要定义一个权威概率转移模式图(authority transfer schema graph)G A ( V G , E G A ) G^A(V_G, E_G^{A})GA(VG,EGA),图中每条边的转移概率是依据专家知识定义的。给定数据图(data graph)D ( V D , E d ) D(V_D, E_d)D(VD,Ed)可以根据G ( V G , E G ) G(V_G, E_G)G(VG,EG)和G A ( V G , E G A ) G^A(V_G, E_G^{A})GA(VG,EGA)可以得到一个权威性转移数据图D A ( V D , E D A ) D^A(V_D, E_D^A)DA(VD,EDA)。
对于图中任意两个对象 u uu 和 v vv间的转移概率可以定义为:
M ( u , v ) = { w ( T ) d o u t ( u , T ) if d o u t ( u , T ) > 0 0 if d o u t ( u , T ) = 0 M(u, v)=\left\{\begin{array}{ll} \frac{w(T)}{d_{o u t}(u, T)} & \text { if } d_{o u t}(u, T)>0 \\ 0 & \text { if } d_{o u t}(u, T)=0 \end{array}\right.M(u,v)={dout(u,T)w(T)0 if dout(u,T)>0 if dout(u,T)=0
式中 T TT表示边( u , v ) (u, v)(u,v)的类型,w ( T ) w(T)w(T)表示边类型为T TT的权威转移概率,d o u t ( u , T ) d_{out}(u, T)dout(u,T)表示节点u uu所有出边类型为 T TT 的边数量。
在定义权威性转移数据图并得到节点带你转移概率矩阵 M MM 之后,其在线查询过程与Personalized PageRank 类似。
对于一个查询关键字 k kk ,系统将会根据包含该关键字的对象准备一个查询向量 q \mathbf{q}q,如果一个对象 u uu 包含关键字 k kk,那么 q ( u ) = 1 / N k q(u)=1/N_kq(u)=1/Nk,否则q ( u ) = 0 q(u)=0q(u)=0, 其中N k N_kNk表示所有包含该关键字的对象数量。那么对于给定的关键字 k kk其 ObjectRank vector为:
O R q = ( 1 − α ) M T × O R q + α q \mathrm{OR}_{q}=(1-\alpha) M^{T} \times \mathrm{OR}_{q}+\alpha \mathrm{q}ORq=(1−α)MT×ORq+αq
其中α \alphaα阻尼参数。
PopRank
PopRank主要用于网页排序,考虑了网页流行度和其它类型对象的影响,计算公式如下:
R X = ϵ R E X + ( 1 − ϵ ) ∑ Y γ Y X M Y X T R Y \mathbf{R}_{X}=\epsilon \mathbf{R}_{E X}+(1-\epsilon) \sum_{Y} \gamma_{Y X} M_{Y X}^{T} \mathbf{R}_{Y}RX=ϵREX+(1−ϵ)Y∑γYXMYXTRY
其中 ϵ \epsilonϵ 为加权参数,γ Y X \gamma_{Y X}γYX 表示从类型为Y YY的对象到类型为X XX的对象的流行度传播因子(PPF),∑ Y γ Y X = 1 \sum_{Y} \gamma_{Y X}=1∑YγYX=1;M Y X M_{YX}MYX是类型Y YY和类型X XX间的邻接矩阵;R Y R_YRY 是类型 Y 的PopRank vector。
论文中还提出了模拟退火算法来学习流行传播因子 γ Y X \gamma_{Y X}γYX,想了解可以阅读原论文。Object-Level Ranking: Bringing Order to Web Objects