字符串转成 数组, 可以随机访问
- 核心思想:
select Usercol BULK COLLECT INTO Userarr from UserTable - 关键字: BULK COLLECT INTO
- 例子
CREATE OR REPLACE PROCEDURE P_WindsTest(psViceUSNList IN VARCHAR2) AS
TYPE Type_Varchar30_Array IS VARRAY(1000) of varchar(30);
--TYPE Type_Varchar30_Array IS TABLE OF SFCUSNREPAIR.USN%TYPE;
arrUSN Type_Varchar30_Array;
BEGIN
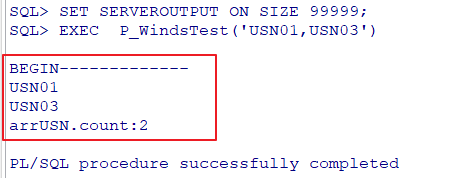
dbms_output.put_line('BEGIN-------------');
-- 字符串 转为 数组
select regexp_substr(psViceUSNList,'[^,]+',1, rownum) AS USN BULK COLLECT INTO arrUSN from dual
connect by rownum<=length(psViceUSNList)-length(replace(psViceUSNList,','))+1;
-- 使用数组 arrUSN.first, arrUSN(i), arrUSN.count 等
FOR i IN arrUSN.first .. arrUSN.last LOOP
dbms_output.put_line(arrUSN(i));
END LOOP;
dbms_output.put_line('arrUSN.count:' || arrUSN.count);
END;
-- 命令窗口执行
SET SERVEROUTPUT ON SIZE 99999;
EXEC P_WindsTest('USN01,USN03');
字符串转成 Table
- 核心思想:
regexp_substr('str1,abc,efg,str4', '[^,]+', 1, rownum)
--****************************************************************
-- regexp_substr(string, pattern, position, occurrence, modifier)
-- string : 要处理的字符串
-- pattern :正则表达式,[^,]+ : 至少有一个 ','
-- position : 起始位置,默认 1
-- occurrence: 获取第几个分隔出来的组(字符串分隔后排列成组)
-- modifier : 模式('i': 不区分大小写,'c': 区分大小写, 默认 'c')
--****************************************************************
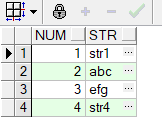
select rownum AS NUM,
regexp_substr('str1,abc,efg,str4', '[^,]+', 1, rownum) AS str
from dual
connect by rownum <= length('str1,abc,efg,str4') -
length(replace('str1,abc,efg,str4', ',', '')) + 1;
版权声明:本文为IT_wind007原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。