1、新建maven工程
步骤:File–>New–>Project–>Maven



2、下载jdk,junit,Spark相关的jar包
jdk,junit修改版本号
jdk,junit的相关信息原本就有,根据实际修改版本号即可,我用的是jdk1.8和junit4.12
在此提供jdk,junit的相关信息,方便复制
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
Spark的jar包信息百度搜索复制
Spark的jar包信息怎么来?也就是这个中间的信息怎么来,不用死记硬背,百度搜索。
百度搜索maven,进maven repository:maven,搜索Spark,按需要点进去,找到对应的版本号复制即可。
该网站比较难进,在此提供一下网址,
网址:https://mvnrepository.com/artifact/org.apache.spark
在此演示scala的jar包查找,Spark和log4j自己查找复制。
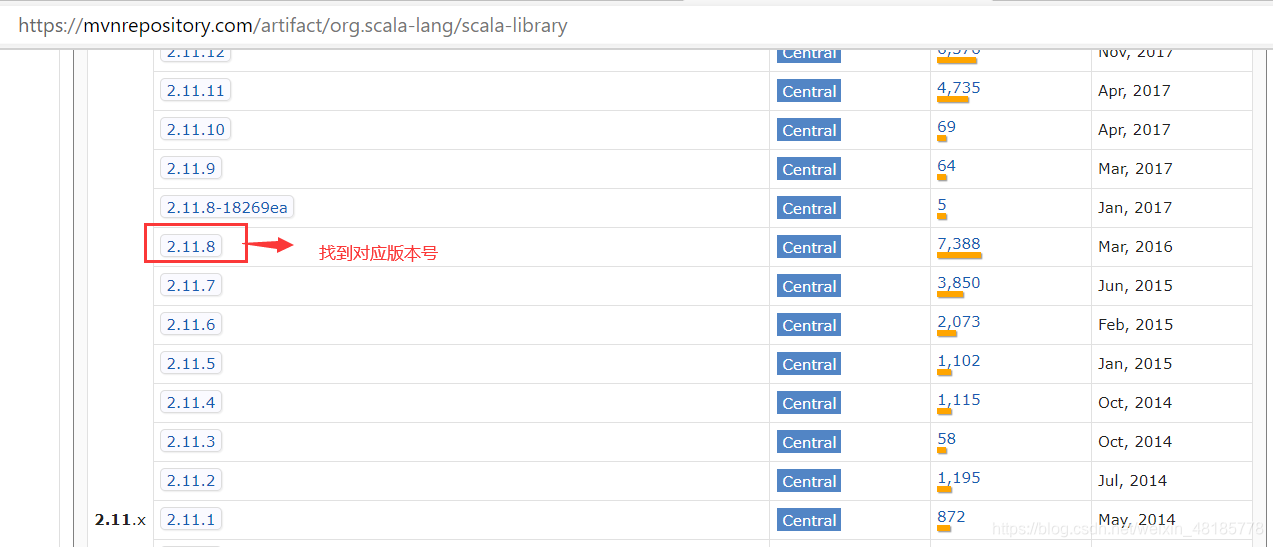
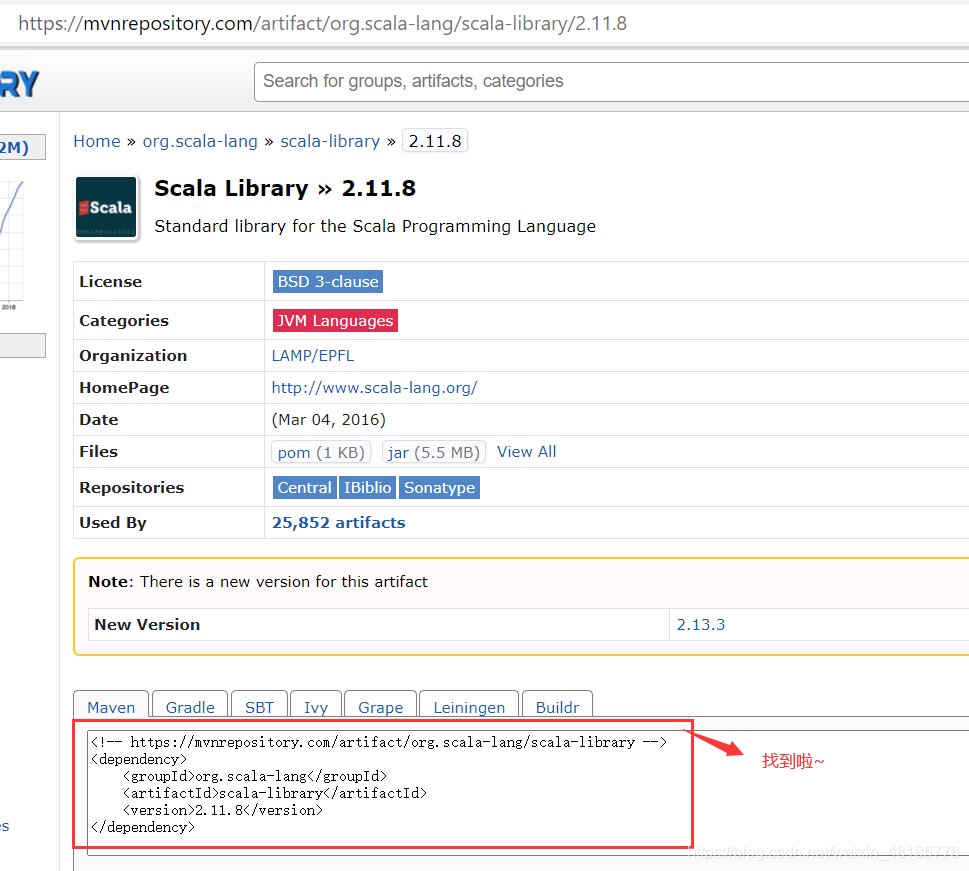
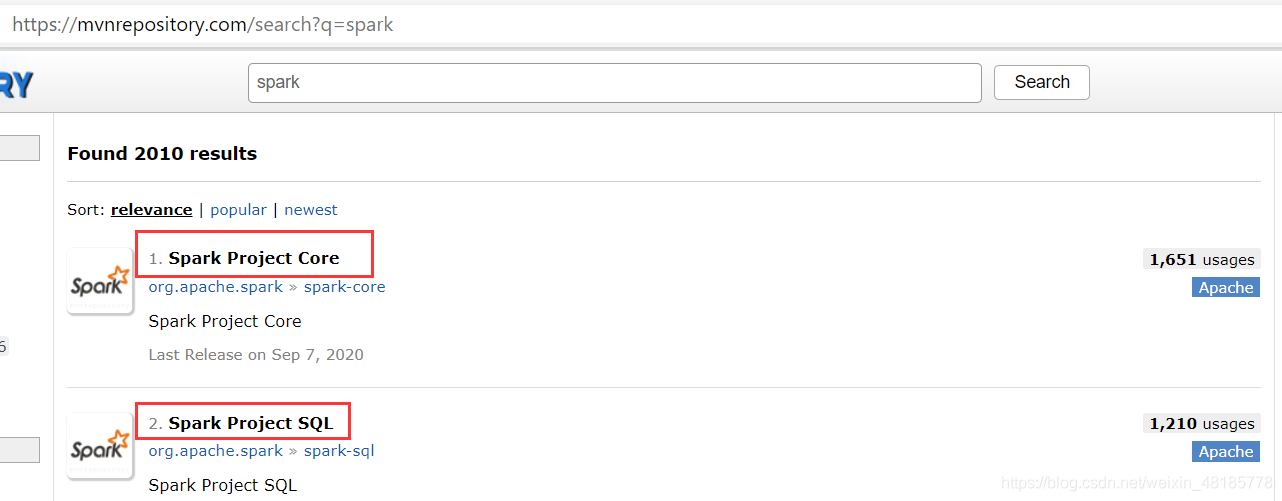
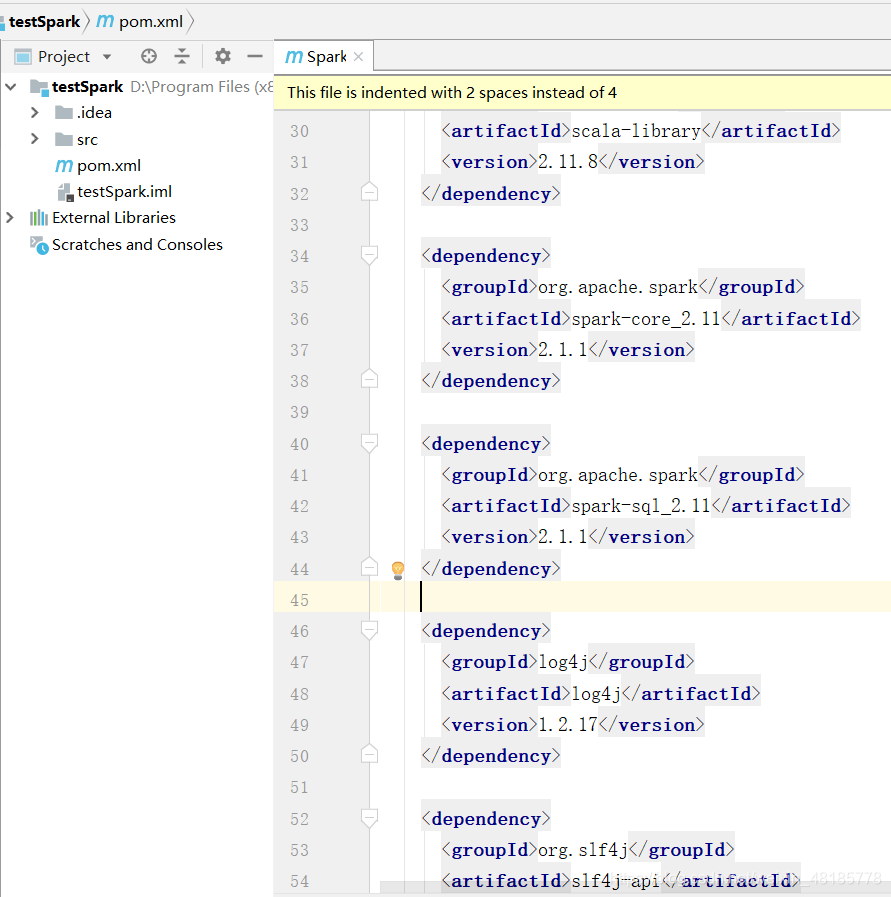
在此提供一下所需依赖包信息:
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.21</version>
</dependency>
右下角点击下载jar包,Enable Auto-Import是自动下载,随便点哪个都可以~
以上下载好之后,我们需要干活了,先new一个scala吧。
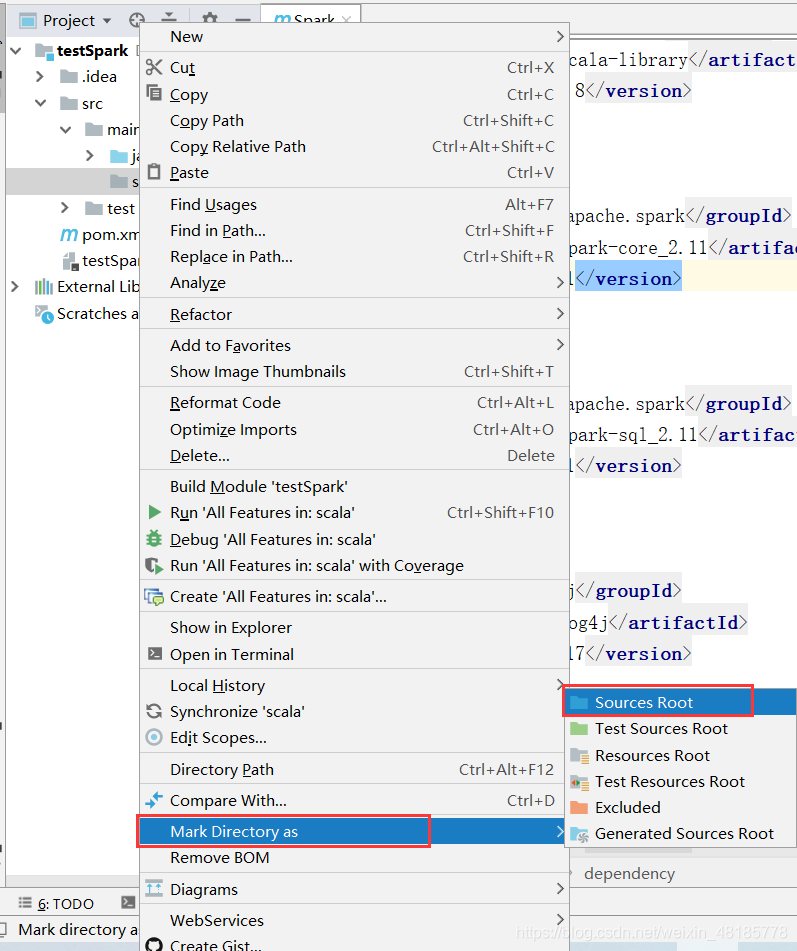
我们发现,src下任何一个文件夹没办法new出scala,需要我们设置。
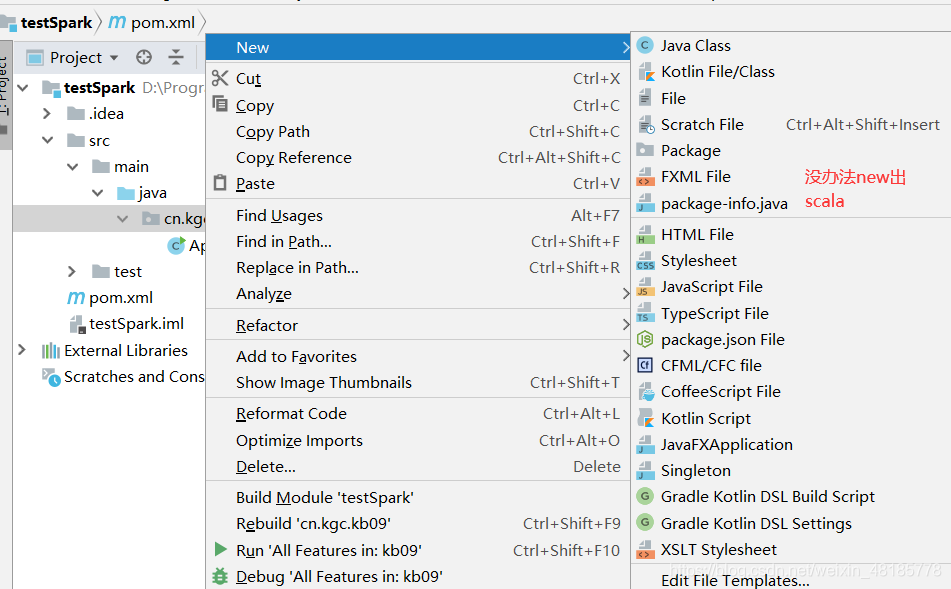
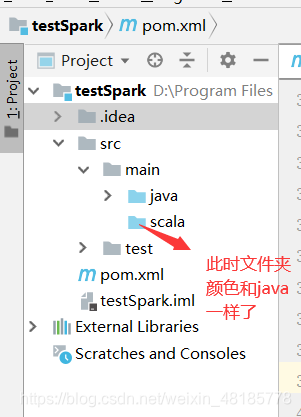
在main文件夹下新建一个scala目录(目录名随便起哈),与java平级,并将scala设置为Sources root。
(说明一下Sources root的用处:通过这个类指定一个文件夹,你告诉IntelliJ IDEA,这个文件夹及其子文件夹中包含的源代码,可以编译为构建过程的一部分。)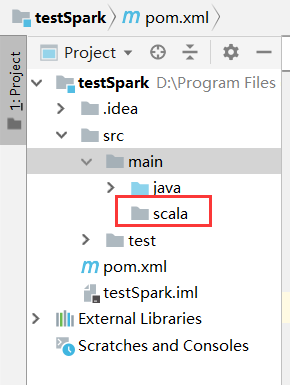
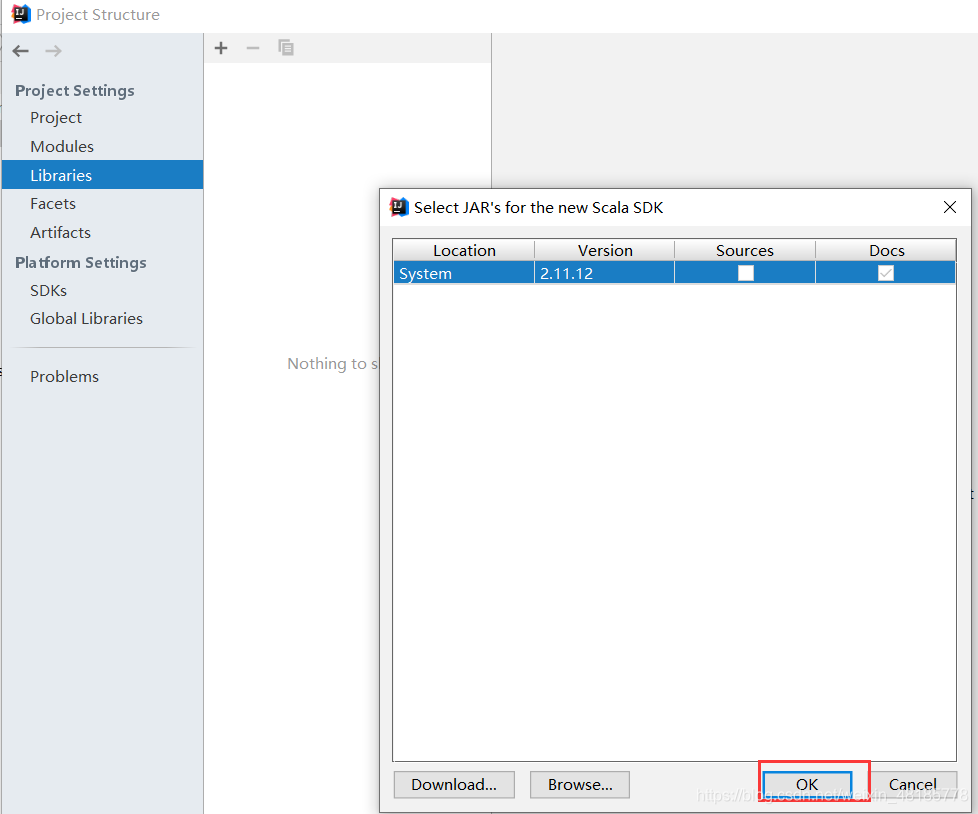
进入File–>Project Structure–>Libraries–>±->Scala SDK–>选中–>OK–>OK–>OK(一直Ok就行了)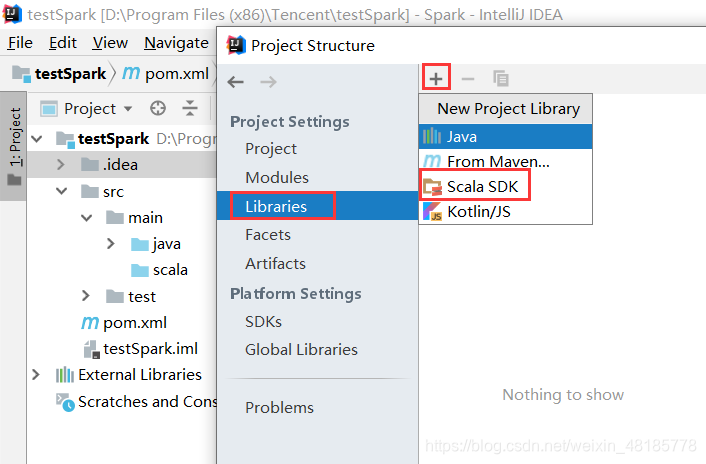
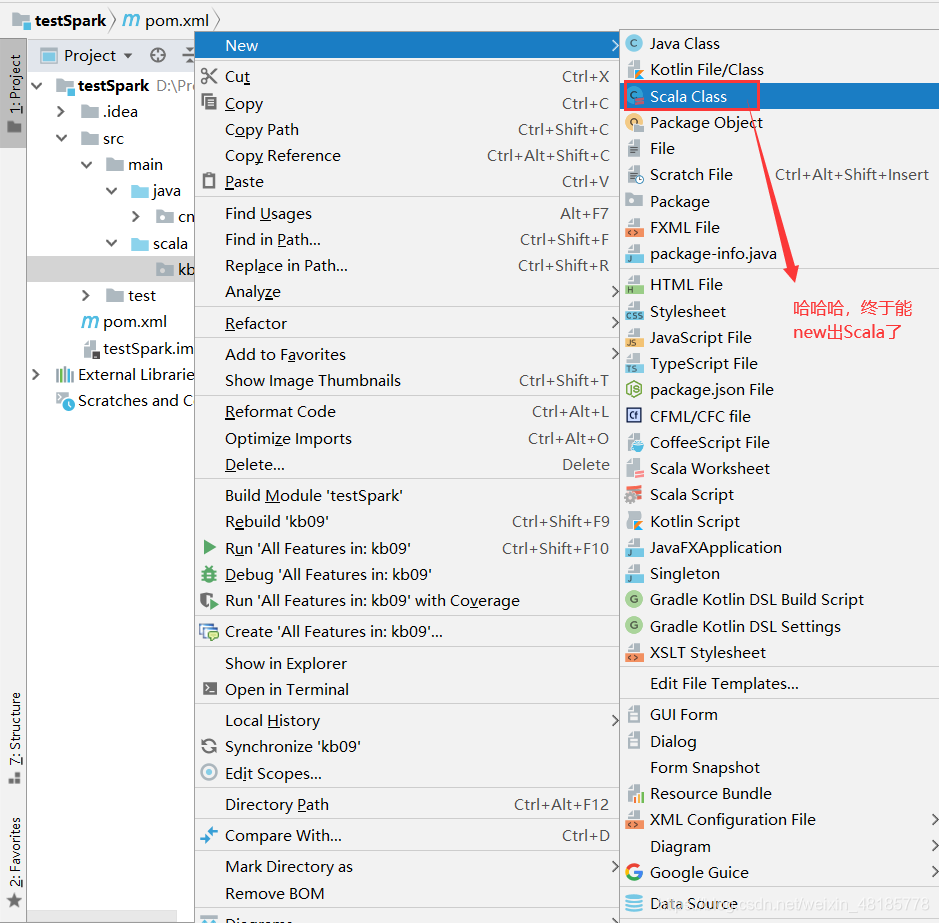
另一种Maven中新增scala的方法:工程名右击–>AddFramework Support–>选择Scala即可。
3、实现wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf:SparkConf=new SparkConf().setMaster("local[2]").setAppName("wordcount")
val sc:SparkContext = SparkContext.getOrCreate(conf)
val rdd1:RDD[String]=sc.parallelize(List("hello world","hello java","hello scala"))
rdd1.flatMap(x=>x.split(" ")).map((_,1)).reduceByKey(_+_).collect.foreach(println)
}
}
结果如下: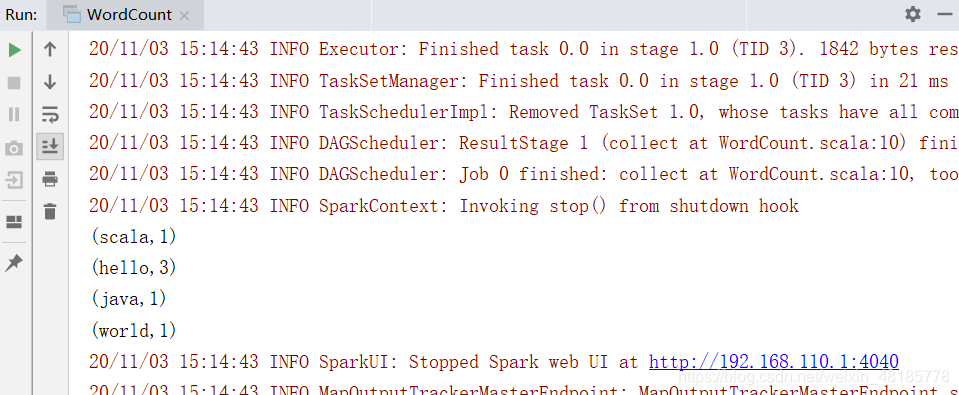
日志也一并打出来了,看着很累赘,可以将日志部分去掉:
- 步骤1:建一个与src平级的目录resource,将其设置为资源文件夹(设置方式:右击–>Mark Directory as–>source root)
- 步骤2:找到log4j(全称:log4j-defaults.properties),把它复制到刚刚新建的resource资源文件夹中,改名为log4j.properties(必须要改)。
log4j的位置:
External Libraries–>maven:org.apache.spark:spark-core_2.11:2.1.1–>spark-core_2.11-2.1.1.jar–>org–>apache.spark–>log4j-defaults.properties。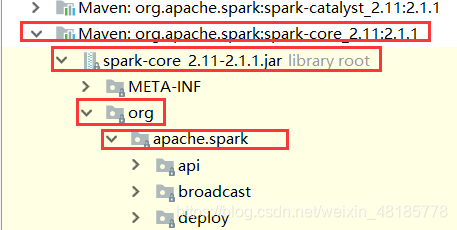
- 步骤3:将log4j文件第一行的INFO修改为ERROR。

这个时候再运行WordCount,结果如下: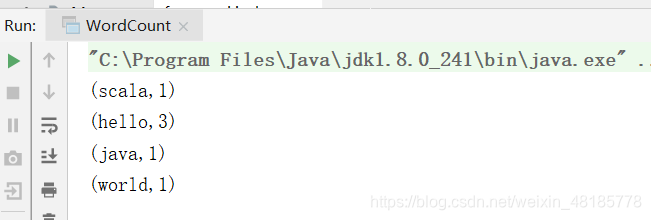
4、RDD两种创建方式
1、使用集合创建RDD
2、加载文件创建RDD(包括加载本地文件和加载HDFS文件)
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf:SparkConf=new SparkConf().setMaster("local[2]").setAppName("wordcount")
val sc:SparkContext=SparkContext.getOrCreate(conf)
//使用集合创建RDD
val rdd1:RDD[String]=sc.parallelize(List("hello world","hello java","hello scala"),3) //第二个参数设置的是分区,不设置默认是上面的local[2]
//sc.makeRDD(List("hello world","hello java","hello scala"),3)
rdd1.flatMap(x=>x.split(" ")).map((_,1)).reduceByKey(_+_).collect.foreach(println)
val partitions = rdd1.partitions
println("rdd分区:"+partitions.length) //可以试着打印出分区数
//通过加载本地文件产生RDD
println("--------------------------------------")
val lines:RDD[String] = sc.textFile("D:\\test\\a.txt ") //本地目录
lines.collect().foreach(println)
//通过加载HDFS文件产生RDD
println("--------------------------------------")
val linesHDFS:RDD[String] = sc.textFile("hdfs://hadoop20:9000/wctest/a.txt") //HDFS目录
linesHDFS.collect().foreach(println)
}
}