在Flask中,并没有把Model类封装好,需要使用一个扩展包,Flask-SQLAlchemy。
倒入第三方数据库扩展包:from flask_sqlalchemy import SQLAlchemy
一、ORM
1. ORM的全称是:Object Relationship Map:对象-关系映射。主要的功能是实现模型对象到关系型数据库数据的映射。说白了就是使用通过对象去操作数据库。
2. 操作过程图:
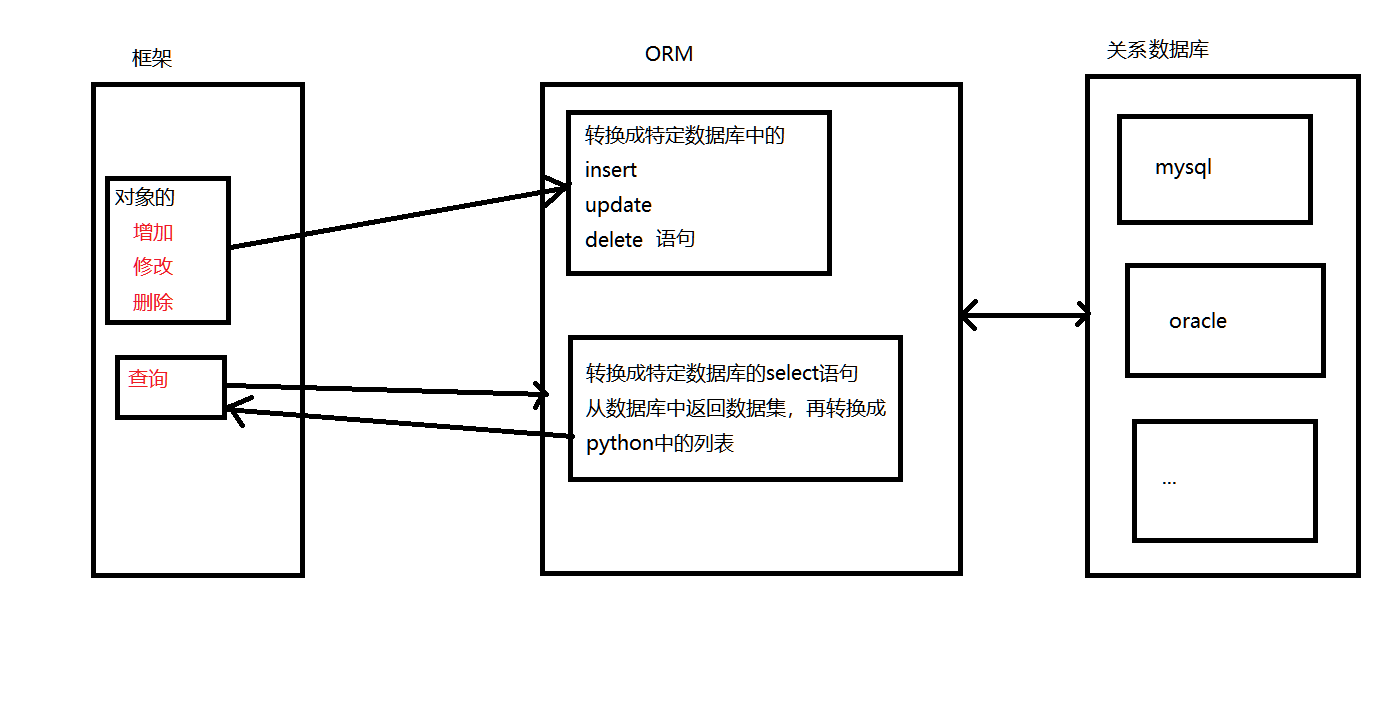
3. 优点:
(1). 不需要编写SQL代码,这样可以把精力放在业务逻辑处理上。
(2). 使用对象的方式去操作数据库。实现数据模型与数据库的解耦,利于开发。
4. 缺点:
性能较低。
Flask-SQLAlchemy设置配置信息
SQLALCHEMY_DATABASE_URI = 'myslq://root:meiyou@127.0.0.1:3306/test'
SQLALCHEMY_POOL_RECYCLE:设置多少秒后自动回收连接,对MySQL来说,默认是2小时
SQLALCHEMY_ECHO:设置True的话,查询时会显示原始SQL语句。
SQLALCHEMY_TRACK_MODIFICATIONS:True 动态追踪修改设置。
SQLALCHEMY_COMMIT_ON_TEARDOWN = True 设置每次请求结束后会自动提交数据库中的改动
创建数据库的操作对象 db = SQLAlchemy(app)
数据库基本操作
在Flask-SQLAlchemy中,插入、修改、删除操作,均由数据库会话管理。会话用db.session表示。在准备把数据写入数据库前,要先将数据添加到会话中然后调用commit()方法提交会话。
数据库会话是为了保证数据的一致性,避免因部分更新导致数据不一致。提交操作把会话对象全部写入数据库,如果写入过程发生错误,整个会话都会失效。
数据库会话也可以回滚,通过db.session.rollback()方法,实现会话提交数据前的状态。
在Flask-SQLAlchemy中,查询操作是通过query对象操作数据。最基本的查询是返回表中所有数据,可以通过过滤器进行更精确的数据库查询。
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# url的格式为:数据库的协议://用户名:密码@ip地址:端口号(默认可以不写)/数据库名
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:mysql@localhost/first_flask"
# 动态追踪数据库的修改. 性能不好. 且未来版本中会移除. 目前只是为了解决控制台的提示才写的
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
# 创建数据库的操作对象
db = SQLAlchemy(app)
class Role(db.Model):
__tablename__ = "roles"
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String(16),unique=True)
# 给Role类创建一个uses属性,关联users表。
# backref是反向的给User类创建一个role属性,关联roles表。这是flask特殊的属性。
users = db.relationship('User',backref="role")
# 相当于__str__方法。
def __repr__(self):
return "Role: %s %s" % (self.id,self.name)
class User(db.Model):
# 给表重新定义一个名称,默认名称是类名的小写,比如该类默认的表名是user。
__tablename__ = "users"
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String(16),unique=True)
email = db.Column(db.String(32),unique=True)
password = db.Column(db.String(16))
# 创建一个外键,和django不一样。flask需要指定具体的字段创建外键,不能根据类名创建外键
role_id = db.Column(db.Integer,db.ForeignKey("roles.id"))
def __repr__(self):
return "User: %s %s %s %s" % (self.id,self.name,self.password,self.role_id)
@app.route('/')
def hello_world():
return 'Hello World!'
if __name__ == '__main__':
# 删除所有的表
db.drop_all()
# 创建表
db.create_all()
ro1 = Role(name = "admin")
# 先将ro1对象添加到会话中,可以回滚。
db.session.add(ro1)
ro2 = Role()
ro2.name = 'user'
db.session.add(ro2)
# 最后插入完数据一定要提交
db.session.commit()
us1 = User(name='wang', email='wang@163.com', password='123456', role_id=ro1.id常用的SQLAlchemy查询过滤器
| 过滤器 | 说明 |
|---|---|
| filter() | 把过滤器添加到原查询上,返回一个新查询 |
| filter_by() | 把等值过滤器添加到原查询上,返回一个新查询 |
| limit | 使用指定的值限定原查询返回的结果 |
| offset() | 偏移原查询返回的结果,返回一个新查询 |
| order_by() | 根据指定条件对原查询结果进行排序,返回一个新查询 |
| group_by() | 根据指定条件对原查询结果进行分组,返回一个新查询 |
常用的SQLAlchemy查询执行器
| 方法 | 说明 |
|---|---|
| all() | 以列表形式返回查询的所有结果 |
| first() | 返回查询的第一个结果,如果未查到,返回None |
| first_or_404() | 返回查询的第一个结果,如果未查到,返回404 |
| get() | 返回指定主键对应的行,如不存在,返回None |
| get_or_404() | 返回指定主键对应的行,如不存在,返回404 |
| count() | 返回查询结果的数量 |
| paginate() | 返回一个Paginate对象,它包含指定范围内的结果 |
数据库的增删改查:
1.以下的方法都是返回一个新的查询,需要配合执行器使用。
filter(): 过滤,功能比较强大。
filter_by():过滤,用在一些比较简单的过滤场景。
order_by():排序。默认是升序,降序需要导包:from sqlalchemy import * 。然后引入desc方法。比如order_by(desc("email")).按照邮箱字母的降序排序。
group_by():分组。
2.以下都是一些常用的执行器:配合上面的过滤器使用。
get():获得id等于几的函数。比如:查询id=1的对象。get(1)。切记:括号里没有“id=”,直接传入id的数值就ok。因为该函数的功能就是查询主键等于几的对象。
all():查询所有的数据。
first():查询第一个数据。
count():返回查询结果的数量。
paginate():分页查询,返回一个分页对象。paginate(参数1,参数2,参数3)
参数1:当前是第几页,参数2:每页显示几条记录,参数3:是否要返回错误。
返回的分页对象有三个属性:items:获得查询的结果,pages:获得一共有多少页,page:获得当前页。
3.常用的逻辑符:
需要倒入包才能用的有:from sqlalchemy import *
not_ and_ or_ 还有上面说的排序desc。
常用的内置的有:in_ 表示某个字段在什么范围之中。
4.其他关系的一些数据库查询:
endswith():以什么结尾。
startswith():以什么开头。
contains():包含
1. 查询所有用户数据
User.query.all()
2. 查询有多少个用户
User.query.count()
3. 查询第1个用户
User.query.first()
4. 查询id为4的用户[3种方式]
User.query.get(4)
User.query.filter_by(id=4).first()
User.query.filter(User.id==4).first()
filter:(类名.属性名==)
filter_by:(属性名=)
filter_by: 用于查询简单的列名,不支持比较运算符
filter比filter_by的功能更强大,支持比较运算符,支持or_、in_等语法。
5. 查询名字结尾字符为g的所有数据[开始/包含]
User.query.filter(User.name.endswith('g')).all()
User.query.filter(User.name.contains('g')).all()
6. 查询名字不等于wang的所有数据[2种方式]
from sqlalchemy import not_
注意了啊:逻辑查询的格式:逻辑符_(类属性其他的一些判断)
User.query.filter(not_(User.name=='wang')).all()
User.query.filter(User.name!='wang').all()
7. 查询名字和邮箱都以 li 开头的所有数据[2种方式]
from sqlalchemy import and_
User.query.filter(and_(User.name.startswith('li'), User.email.startswith('li'))).all()
User.query.filter(User.name.startswith('li'), User.email.startswith('li')).all()
8. 查询password是 `123456` 或者 `email` 以 `itheima.com` 结尾的所有数据
from sqlalchemy import or_
User.query.filter(or_(User.password=='123456', User.email.endswith('itheima.com'))).all()
9. 查询id为 [1, 3, 5, 7, 9] 的用户列表
User.query.filter(User.id.in_([1, 3, 5, 7, 9])).all()
10. 查询name为liu的角色数据
关系引用
User.query.filter_by(name='liu').first().role.name
11. 查询所有用户数据,并以邮箱排序
排序
User.query.order_by('email').all() 默认升序
User.query.order_by(desc('email')).all() 降序
12. 查询第2页的数据, 每页只显示3条数据
help(User.query.paginate)
三个参数: 1. 当前要查询的页数 2. 每页的数量 3. 是否要返回错误
pages = User.query.paginate(2, 3, False)
pages.items # 获取查询的结果
pages.pages # 总页数
pages.page # 当前页数使用迁移命令如下:
比如上面的代码所在的文件名称为database.py。
1.python database.py db init 生成管理迁移文件的migrations目录
2.python database.py db migrate -m "注释" 在migrations/versions中生成一个文件,该文件记录数据表的创建和更新的不同版本的代码。
3.python database.py db upgrade 在数据库中生成对应的表格。
4.当需要改表格的时候,改完先执行第二步,然后再执行第三步。
5.需要修改数据表的版本号的时候需要做的操作如下:
python database.py db upgrade 版本号 向上修改版本号
python database.py db downgrade 版本号 向下修改版本号
可能用到的其他的语句:
python database.py db history 查看历史版本号
python database.py db current 查看当前版本号