从网上找了多个编码转换工具,自己也尝试写、从网上找python脚本,对文件进行批量转换,但转换结果都不理想,大部分文件都可以正常转换成UTF8,但少量文件转换后可能出现中文乱码的情况。
经过多次尝试,发现使用notepad++程序进行编码转换,可以保证文件不乱码的情况下将文件转换为UTF8。
Notepad++程序并未提供对外的编程接口,想控制该程序进行批量转换就需要使用其提供的Python Script插件,且只支持python2的写法。
经过探索之后,将notepad++程序进行打包,大家可以直接使用。使用步骤略微繁琐,需要大家按下面步骤进行使用。
1、解压文件
将“Notepad++.zip”拷贝到某个位置,进行解压。
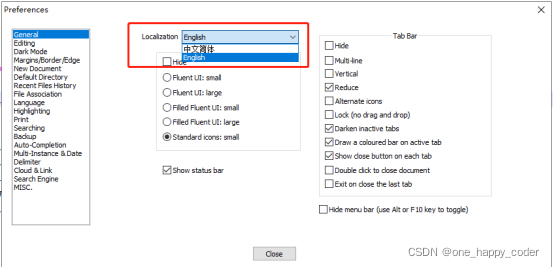
2、将语言修改为英文
双击解压出文件夹里的“notepad++.exe”程序,修改程序界面为英文。
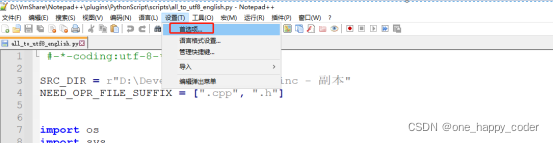
3、打开脚本文件
如果本机原来就安装了notepad程序,必须通过解压文件中打开的“notepad++.exe”去打开脚本文件,文件路径如下图所示:
4、手动修改要转换的文件路径
手动修改脚本中要处理的文件路径,如下图所示:
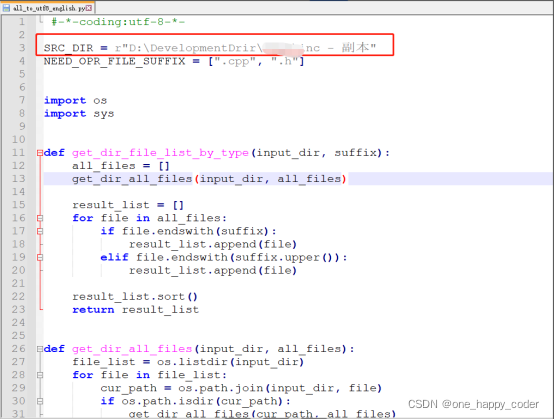
将该路径复制粘贴到脚本中即可(需要是r”...”的格式):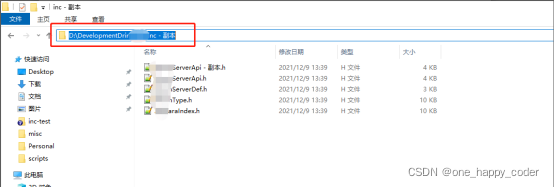
5、打开notepad中的python终端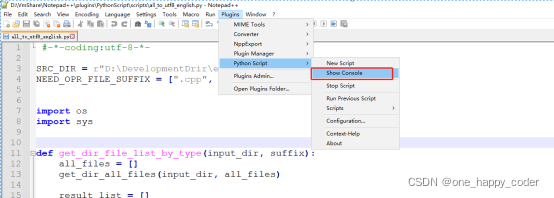
6、执行脚本
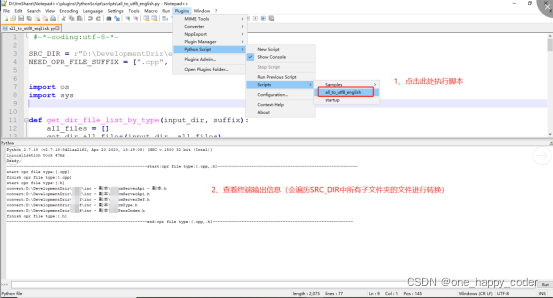
7、验证转换结果是否正确
使用“WinMerge”可以查看转换结果是否正确。
附件:
all_to_gbk_english.py
#-*-coding:utf-8-*-
SRC_DIR = r"D:\DevDrir\src\test-20211229-2"
NEED_OPR_FILE_SUFFIX = [".cpp", ".h"]
import os
import sys
def get_dir_file_list_by_type(input_dir, suffix):
all_files = []
get_dir_all_files(input_dir, all_files)
result_list = []
for file in all_files:
if file.endswith(suffix):
result_list.append(file)
elif file.endswith(suffix.upper()):
result_list.append(file)
result_list.sort()
return result_list
def get_dir_all_files(input_dir, all_files):
file_list = os.listdir(input_dir)
for file in file_list:
cur_path = os.path.join(input_dir, file)
if os.path.isdir(cur_path):
get_dir_all_files(cur_path, all_files)
else:
all_files.append(cur_path)
return all_files
def convert(file):
if not os.path.exists(file):
print("not find file:%s" % file)
return
print("convert:%s" % file)
notepad.open(file.encode('utf8'))
notepad.runMenuCommand("Encoding", "Convert to ANSI")
notepad.save()
notepad.close()
bak_file_name = file + ".bak"
if os.path.exists(bak_file_name):
os.remove(bak_file_name)
def file_list_convert(file_list, out_enc="UTF-8"):
for file_name in file_list:
convert(file_name)
opr_src_dir = unicode(SRC_DIR, 'utf-8')
opr_file_type_info = "opr file type:[%s]" % ",".join(NEED_OPR_FILE_SUFFIX)
PRINT_INFO_PREFIX = "----------------------------------------------------------"
print("%sstart:%s%s" % (PRINT_INFO_PREFIX, opr_file_type_info, PRINT_INFO_PREFIX))
#opr_src_dir = os.getcwd()
#opr_src_dir = r"D:\svn\5.0\edpf\inc-test"
for suffix in NEED_OPR_FILE_SUFFIX:
print("start opr file type:[%s]" % suffix)
file_list = get_dir_file_list_by_type(opr_src_dir, suffix)
file_list_convert(file_list)
print("finish opr file type:[%s]" % suffix)
print("%send:%s%s" % (PRINT_INFO_PREFIX, opr_file_type_info, PRINT_INFO_PREFIX))all_to_utf8_english.py
#-*-coding:utf-8-*-
SRC_DIR = r"D:\DevelopmentDrir\src\test-20211215\"
NEED_OPR_FILE_SUFFIX = [".cpp", ".h"]
import os
import sys
def get_dir_file_list_by_type(input_dir, suffix):
all_files = []
get_dir_all_files(input_dir, all_files)
result_list = []
for file in all_files:
if file.endswith(suffix):
result_list.append(file)
elif file.endswith(suffix.upper()):
result_list.append(file)
result_list.sort()
return result_list
def get_dir_all_files(input_dir, all_files):
file_list = os.listdir(input_dir)
for file in file_list:
cur_path = os.path.join(input_dir, file)
if os.path.isdir(cur_path):
get_dir_all_files(cur_path, all_files)
else:
all_files.append(cur_path)
return all_files
def convert(file):
if not os.path.exists(file):
print("not find file:%s" % file)
return
print("convert:%s" % file)
notepad.open(file.encode('utf8'))
notepad.runMenuCommand("Encoding", "Convert to UTF-8")
notepad.save()
notepad.close()
bak_file_name = file + ".bak"
if os.path.exists(bak_file_name):
os.remove(bak_file_name)
def file_list_convert(file_list, out_enc="UTF-8"):
for file_name in file_list:
convert(file_name)
opr_src_dir = unicode(SRC_DIR, 'utf-8')
opr_file_type_info = "opr file type:[%s]" % ",".join(NEED_OPR_FILE_SUFFIX)
PRINT_INFO_PREFIX = "----------------------------------------------------------"
print("%sstart:%s%s" % (PRINT_INFO_PREFIX, opr_file_type_info, PRINT_INFO_PREFIX))
#opr_src_dir = os.getcwd()
#opr_src_dir = r"D:\svn\5.0\edpf\inc-test"
for suffix in NEED_OPR_FILE_SUFFIX:
print("start opr file type:[%s]" % suffix)
file_list = get_dir_file_list_by_type(opr_src_dir, suffix)
file_list_convert(file_list)
print("finish opr file type:[%s]" % suffix)
print("%send:%s%s" % (PRINT_INFO_PREFIX, opr_file_type_info, PRINT_INFO_PREFIX))备注:notepad中的python脚本自动化操作notepad是通过描述文字找到的菜单项,比如这个脚本中写的notepad.runMenuCommand("Encoding", "Convert to UTF-8"),为什么使用英文呢?因为如果是中文菜单,在不同的机器上名称可能不一样,有的叫“转换为UTF-8”,有的叫“转换为UTF-8 without Bom”。如果能确定自己机器上的中文菜单是什么,那修改为中文菜单的也可以。