1. import numpy as np 矩阵操作的库
| 操作 | 描述 |
|---|---|
| X * Y | 两个矩阵对应位置元素相乘 |
| X.dot(Y) | 矩阵的内积(一行乘以一列) |
| np.random.random((3,4)) | 生成一个三行四列的随机数(-1,1)矩阵 |
| np.floor(a) | 将数值a向下取整 |
| np.array([1,2,3]) | Python list转成ndarray |
| X.reshape((m,n)) | 将原矩阵改成m*n矩阵 |
| X[:,0:2] | 表示取第0,1列的所有行 |
| X.min()或X.max() | 返回矩阵中的最小值或最大值 |
| X.sum(axis=0) | 返回对每一列求和的结果 |
| X.sum(axis=1) | 返回对每一行求和的结果 |
| np.zeros((3,4)) | 返回一个值全为0的3*4的矩阵 |
| np.ones((3,4)) | 返回一个值全为1的3*4的矩阵 |
| np.full((3,4),6) | 返回一个值全为6的3*4的矩阵 |
| X.ravel() | 将一个矩阵铺成一行输出 |
| np.hstack((X,Y)) | 将矩阵X和Y水平拼接,增加了列数 |
| np.vstack((X,Y)) | 将矩阵X和Y竖直拼接,增加了行数 |
| np.hsplilt((X,3)) | 将矩阵在水平方向等分成3份,返回三个矩阵 |
| np.hsplilt((x,(3,5))) | 将矩阵水平切成0~2列,3~4列,5~n列 |
| X.argmax(axis=0) | 返回矩阵中每列最大元素的下标 |
| X.argmax(axis=1) | 返回矩阵中每行最大元素的下标 |
| X.argmax() | 返回矩阵中最大元素的下标 |
| np.tile(X,(3,4)) | 把矩阵X整体扩增3行、4列 |
| np.sort(X,axis=1) | 将矩阵每一行递增排序 |
最后聊聊关于拷贝赋值的几种做法的区别:(b=a,b=a.view(),b=a.copy())
> a = np.ones((3,3))
> b = a
> c = a.view()
> d = a.copy()
# 三种做法,得到的元素值都是相等的
> print(a == b)
array([[ True, True, True],
[ True, True, True],
[ True, True, True]])
> print(a == c)
array([[ True, True, True],
[ True, True, True],
[ True, True, True]])
# 三种做法,新对象引用的对象不同
> print(a is b)
True
> print(a is c)
False
> print(a is d)
False
# 看看它们在内存中的id,来核实上面的结果
> print(id(a))
140384952264624
> print(id(b))
140384952264624
> print(id(c))
140384921209632
> print(id(d))
140384921208992
# 【重要】修改b,c,d中的某个元素,检查原矩阵a中的元素是否发生变化
> print(a)
array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
> b[0][0] = 2
> c[1][1] = 3
> d[2][2] = 4
> print(a)
array([[2., 1., 1.],
[1., 3., 1.],
[1., 1., 1.]])
# 发现b,c都还是操作的原矩阵,而d操作的是新矩阵。
2. import pandas as pd 数据处理的库
pandas对象是一个DataFrame对象(data),data的每一列取出来,是一个Series对象(ss),ss.values又是一个numpy.ndarray对象
| 操作 | 描述 |
|---|---|
| data = pd.read_cdv(’**.csv’) | 读取数据集,返回的是DataFrame对象 |
| data.columns | 返回数据的列名 |
| data.shape | 返回数据的行和列 |
| data.head(4) | 返回data的前4行 |
| data.tail(3) | 返回data的后3行 |
| data.loc[0] | 取第1行的数据 |
| data.loc[:5] | 取前5行的数据 |
| data[‘c1’] | 取列名为’c1’的该列数据 |
| data[[‘c1’,‘c2’,‘c3’]] | 取列名为’c1’,‘c2’,'c3’的三列数据 |
| del data[‘c1’] | 删除data中的’c1’列 |
| data = data.drop(‘c1’,axis=1) | 删除data中的’c1’列 |
| data.drop(‘c1’,axis=1, inplace=True) | 删除data中的’c1’列 |
| data[‘new_column’] = columns | 增加新的一列特征值 |
| data.sort_values(‘c1’,inplace=True,ascending=True) | 数据集按照’c1’列的值升序排序 |
| data.reset_index(drop=True) | 排序后原index还在,重新生成 |
| pd.isnull(data[‘c1’]) | 判断’c1‘列是否存在缺失值 |
| data[‘c1’].mean() | 返回’c1’列的均值 |
| data.dropna(axis=0, subset=[‘c1’,’c2’]) | 'c1’与’c2’两列有缺失值的话删除该行 |
| data.loc[83,’c1’] | 定位第83行,列名为c1的元素 |
3.import matplotlib.pyplot as plt 绘制图像的库
| 操作 | 描述 |
|---|---|
| plt.plot(data[‘c1’],data[‘c2’]) | X轴的数据为’c1’列,Y轴数据为’c2’列 |
| plt.show() | 显示图像 |
| plt.xticks(rotation=45) | X轴倾斜45度 |
| plt.xlabel(‘this is aixs = 0’) | X轴添加标签 |
| plt.ylabel(‘this is aixs = 1’) | Y轴添加标签 |
| plt.title(‘this is title’) | 绘图添加标题 |
| fig = plt.figure() | 返回默认画图的区域 |
| fig = plt.figure(figsize = (3,4)) | 设置画图的大小(宽、高) |
| ax1 = fig.add_subplot(1,3,1) | 画布等分为一行三列,这是第一个子图 |
| ax2 = fig.add_subplot(1,3,2) | 画布等分为一行三列,这是第二个子图 |
| ax3 = fig.add_subplot(1,3,3) | 画布等分为一行三列,这是第三个子图 |
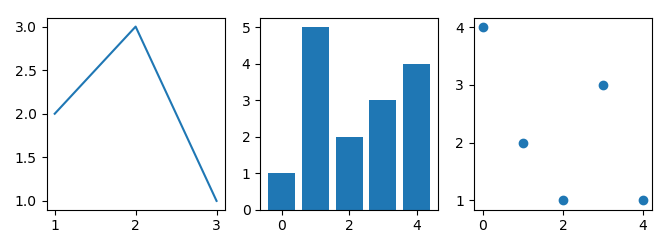
| ax1.plot([1,2,3],[2,3,1]) | 子图一绘制折线图 |
| ax2.bar([0,1,2,3,4],[1,5,2,3,4]) | 子图二绘制柱形图 |
| ax3.scatter([0,1,2,3,4],[4,2,1,3,1], c=‘blue’) | 子图三绘制散点图 |
版权声明:本文为jh1137921986原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。