yolov3-spp深度剖析
1 网络结构
yolov3-spp网络结构如下图:
spp模块结构如下图:
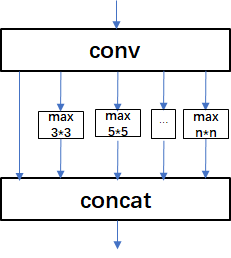
网络结构中spp的具体实现:
#darknet中的cfg文件
...
### SPP ###
[maxpool]
stride=1
size=5
[route]
layers=-2
[maxpool]
stride=1
size=9
[route]
layers=-4
[maxpool]
stride=1
size=13 #pool核的大小不能大于img_size/2**5(尽可能接近或者等于,原因请看自家之言环节,哈哈)
[route]
layers=-1,-3,-5,-6
### End SPP ###2 spp的前世今生
前世:
yolov3中的spp结构,受spp-net的启发而来,接下来我们将一探究竟:
SPP-net全名为Spatial Pyramid Pooling(空间金字塔池化结构),2015年由微软研究院的何恺明提出(没错,又是他)。
主要解决两个问题:
- 有效避免了R-CNN算法对图像区域剪裁、缩放操作导致的图像物体剪裁不全以及形状扭曲等问题。
- 解决了卷积神经网络对图像重复特征提取的问题,大大提高了产生候选框的速度,且节省了计算成本。
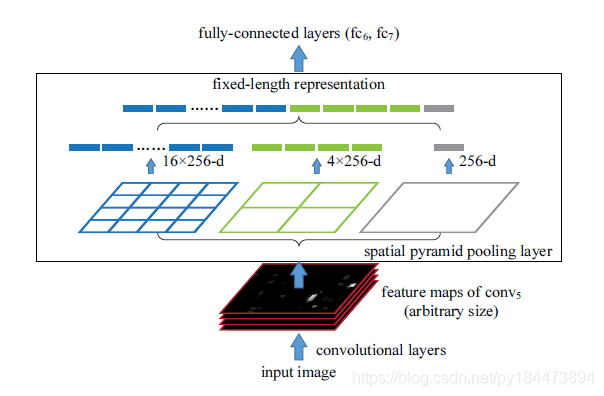
问题1具体解释:在含有全连接层的分类网络中,严格要求输入分辨率和全连接层的特征维度相匹配。所以就会对图像进行裁剪和变形操作,也就出现了问题1。如下图展示的就是通过spp模块将任意分辨率的featherMap转换为设计好的和全连接层相同维度的特征向量。
问题2具体解释:R-CNN是先对输入图像进行2k个候选框选择后,把候选框内的图像wrap到227*277后,再放到cnn里边进行提取,这2k个候选框很多地方都是重叠的,会带来大量重复的计算,因此SPP就先对输入图像进行特征提取之后,在提取后的feature map上在选取候选框,然后使用spatial pyramid pooling,对对应候选框的feature map区域提到到fixed-length representation。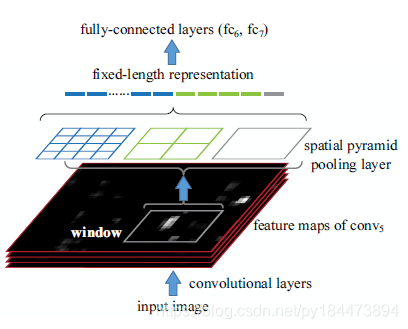
注:如果还想深入了解其中的奥秘,请参考博客:https://www.cnblogs.com/zongfa/p/9076311.html
今生:
yolov3-spp中的spp模块不是解决以上的两个问题,知识借鉴了空间金字塔池化思想。具体实现的价值请看下一节。
3 效果验证
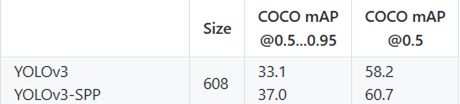
- 官方coco数据集效果
- 自己数据集验证效果
YOLOv3-SPP比YOLOV3的MAP提高了2.4个点,且自己样本中类别存在严重的类别不均衡的问题。
- 自家之言
出现检测效果提升的原因:通过spp模块实现局部特征和全局特征(所以空间金字塔池化结构的最大的池化核要尽可能的接近等于需要池化的featherMap的大小)的featherMap级别的融合,丰富最终特征图的表达能力,从而提高MAP。