1. 函数
首先了解使用到的函数的参数含义。有两种途径:
- 一种是在IDE中输入
help("函数名")。直接在ide中调出了官方文档。 - 另一种是直接在网上搜sklearn官方文档,在里面找到自己需要的这个函数。
第一种方法:
from sklearn.linear_model import LogisticRegression as LR
help(LR)
这个结果和官方文档介绍的一样的,但是在ide里面不好看,直接看官方文档:sklearn-logistic官方文档传送门:https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
sklearn.linear_model.LogisticRegression(
penalty=’l2’, dual=False,
tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1,
class_weight=None, random_state=None, solver=’warn’,
max_iter=100, multi_class=’warn’, verbose=0,
warm_start=False, n_jobs=None, l1_ratio=None)
2. 参数解释
- penalty:惩罚项
- str类型,默认为l2。newton-cg、sag和lbfgs求解算法只支持L2规范,L2假设的模型参数满足高斯分布。
- l1:L1G规范假设的是模型的参数满足拉普拉斯分布.
- dual:对偶或原始方法,bool类型,默认为False。对偶方法只用在求解线性多核(liblinear)的L2惩罚项上。当样本数量>样本特征的时候,dual通常设置为False。
- tol:停止求解的标准,float类型,默认为1e-4。就是求解到多少的时候,停止,认为已经求出最优解。
- c:正则化系数λ的倒数,float类型,默认为1.0。必须是正浮点型数。像SVM一样,越小的数值表示越强的正则化。
- fit_intercept:是否存在截距或偏差,bool类型,默认为True。
- intercept _ scaling:仅在正则化项为”liblinear”,且fit_intercept设置为True时有用。float类型,默认为1。
- class_ weight:用于标示分类模型中各种类型的权重,可以是一个字典或者’balanced’字符串,默认为不输入,也就是不考虑权重,即为None。
- 如果选择输入的话,可以选择balanced让类库自己计算类型权重,或者自己输入各个类型的权重。
- 举个例子,比如对于0,1的二元模型,我们可以定义class_ weight = {0:0.9,1:0.1},这样类型0的权重为90%,而类型1的权重为10%。如果class_ weight选择balanced,那么类库会根据训练样本量来计算权重。
- 某种类型样本量越多,则权重越低,样本量越少,则权重越高。
- 当class_ weight为balanced时,类权重计算方法如下:n_samples / (n_classes * np.bincount(y))。n_samples为样本数,n_classes为类别数量,np.bincount(y)会输出每个类的样本数,例如y=[1,0,0,1,1],则np.bincount(y)=[2,3]。
- 其实这个数据平衡的问题我们有专门的解决办法:重采样
- random_state:随机数种子,int类型,可选参数,默认为无,仅在正则化优化算法为sag,liblinear时有用。
- solver:优化算法选择参数
- liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
- lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。只用于L2
- sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。只用于L2
- saga:线性收敛的随机优化算法的的变重。只用于L2
- max_iter:算法收敛最大迭代次数,int类型,默认为10。仅在正则化优化算法为newton-cg, sag和lbfgs才有用,算法收敛的最大迭代次数。
- multi_class:分类方式选择参数,str类型,可选参数为ovr和multinomial,默认为ovr。ovr即前面提到的one-vs-rest(OvR),而multinomial即前面提到的many-vs-many(MvM)。如果是二元逻辑回归,ovr和multinomial并没有任何区别,区别主要在多元逻辑回归上。
- verbose:日志冗长度,int类型。默认为0。就是不输出训练过程,1的时候偶尔输出结果,大于1,对于每个子模型都输出。
- warm_start:热启动参数,bool类型。默认为False。如果为True,则下一次训练是以追加树的形式进行(重新使用上一次的调用作为初始化)。
- n_jobs:并行数。int类型,默认为1。为-1的时候,用所有CPU的内核运行程序。
3. 实例
数据使用python自带的鸢尾花数据,需要进行标准化处理
from sklearn import datasets
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
iris = datasets.load_iris()
X = iris.data[:,[2,3]] ## 选取花瓣长度和花瓣宽度两个特征
y = iris.target
x_train,x_test,y_train,y_test = train_test_split(X,y,test_size=0.3,train_size=0.7,random_state=0)
sc = StandardScaler()
sc.fit(x_train) # 计算均值和方差
x_train_std = sc.transform(x_train) #利用计算好的方差和均值进行Z分数标准化
x_test_std = sc.transform(x_test)
拟合模型
lr = LR(C=1000,random_state=123)
lr.fit(x_train_std,y_train)
lr.score(u"正确率:",x_test_std,y_test) # 输出一个正确率
y_pred = lr.predict(x_test_std)
print(u"混淆矩阵",confusion_matrix(y_true=y_test,y_pred=y_pred))
print("正确率:",AC(y_test,y_pred))
lr.coef_

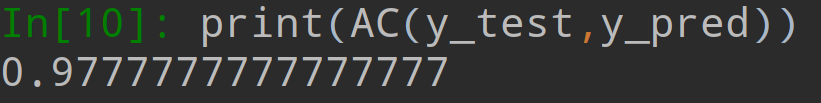
结果正确率三种方式输出都是0.97777777777777
最后看一下模型的三组coefficience:
应该对多元无序的logistic体会更深了吧。这就是所谓的“OvR”。
以上。
版权声明:本文为Monk_donot_know原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。