Flink入门这一篇就够了
Flink好处在这不再赘述,有想要了解的同学可自行搜索
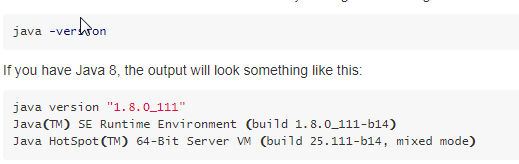
Linux中安装好JDK1.8
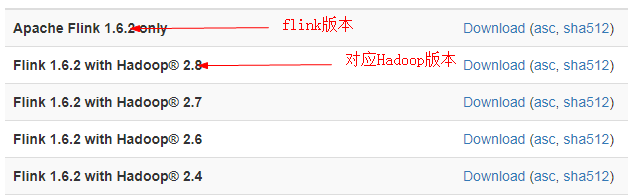
Flink下载(没有windows版本)
https://flink.apache.org/downloads.html
 通过sftp将下载好的文件传入到linux系统上(连接上虚拟机后 alt + p)
通过sftp将下载好的文件传入到linux系统上(连接上虚拟机后 alt + p)
 在/root下可以将文件移动到指定目录中
在/root下可以将文件移动到指定目录中
[root@hadoop301 ~]# mv flink-1.6.1-bin-hadoop26-scala_2.11.tgz /opt
解压
[root@hadoop301 ~]# tar -zxvf flink-1.6.1-bin-hadoop26-scala_2.11.tgz
进入目录启动
[root@hadoop301 flink-1.6.1]# ./bin/start-cluster.sh
点开浏览器输入linuxIP端口为8081打开网页
在IDEA中可以开始写JAVA代码了(也可以使用scala)自行查看
https://ci.apache.org/projects/flink/flink-docs-release-1.6/quickstart/setup_quickstart.html
1.创建一个maven工程
2.pom文件
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.6.1</version>
</dependency>
</dependencies>
Word Count 代码-读取本地文件
//获取环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//读取本地文件-放入到数据集合中
DataSet<String> text = env.readTextFile("/path/to/file");
DataSet<Tuple2<String, Integer>> counts =
text.flatMap(new Tokenizer())
.groupBy(0)
.sum(1);
counts.writeAsCsv(outputPath, "\n", " ");
public static class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
//value是文件中一行一行的数据,将每行数据进行切割
String[] tokens = value.toLowerCase().split("\\W+");
//token是分割出来的单词
for (String token : tokens) {
//如果切割出来的的单词
if (token.length() > 0) {
//写入集合进行统计
out.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
版权声明:本文为JobClub原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。