1 主要创新点
- 文本检测和识别两个任务结合起来,作为互补,提高检测和识别精度;
- 处理不规则形状的文本;
- 提供一个高效的端到端框架PAN++,对实时的应用场景友好。
2 已有工作的痛点
- 将文本检测和识别任务分开,不利于利用两个任务的互补性,也会增加计算开销;
- 已有的端到端框架只能读取水平或定向文本行;
- 已有的端到端框架效率不能满足实时应用。
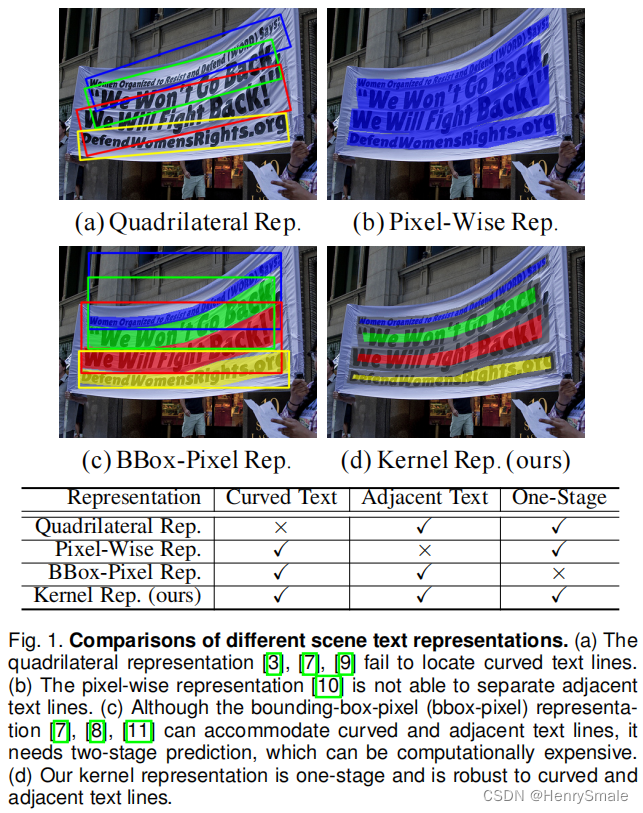
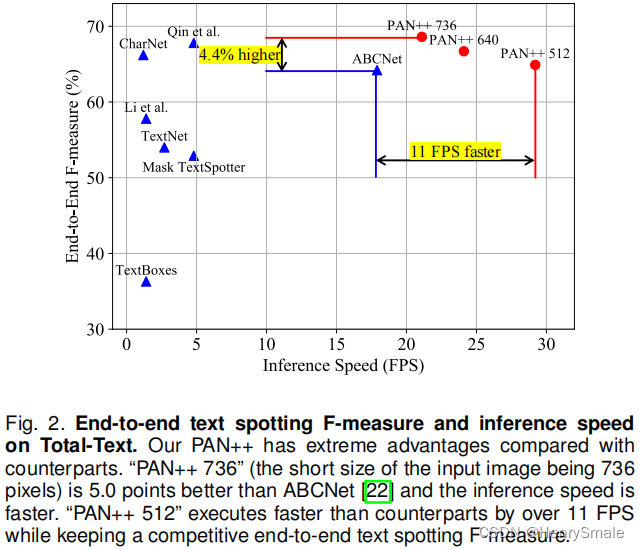
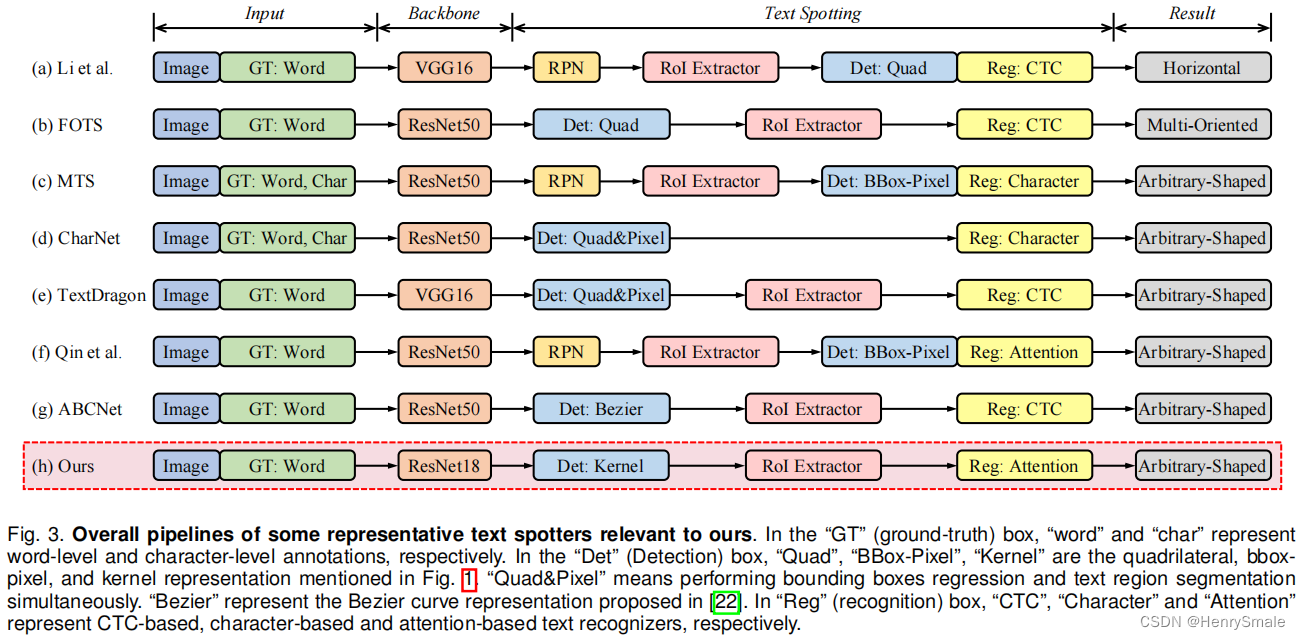
3 主要算法
3.1 总体框架
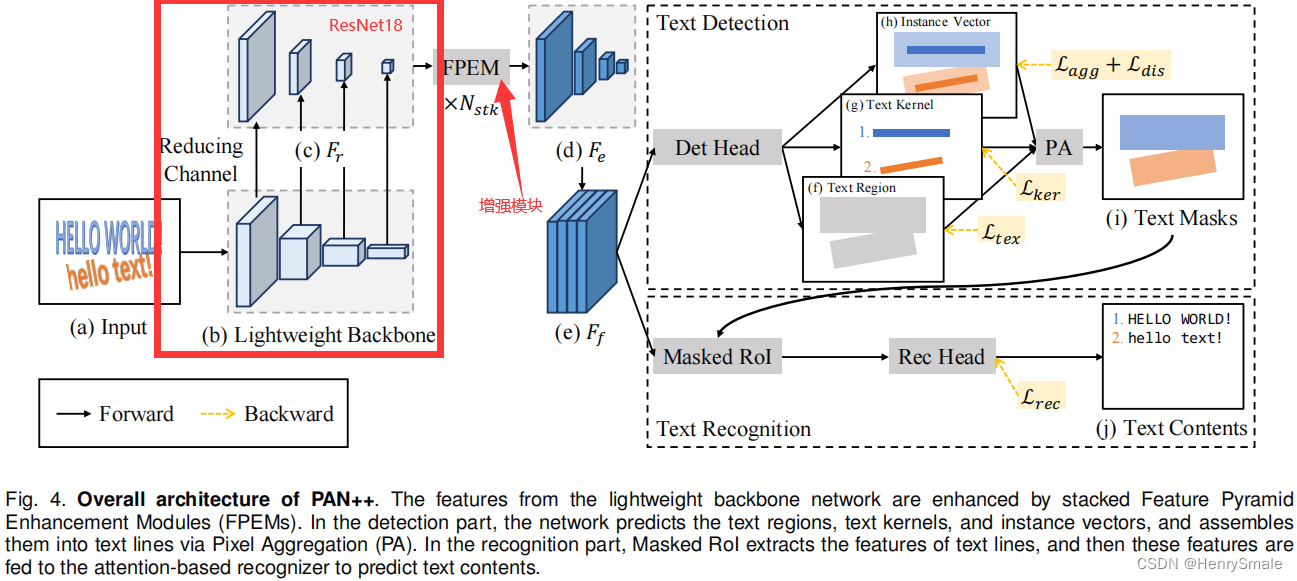
- 为了提高推理速度,采用轻量级的ResNet18作为骨干网络;
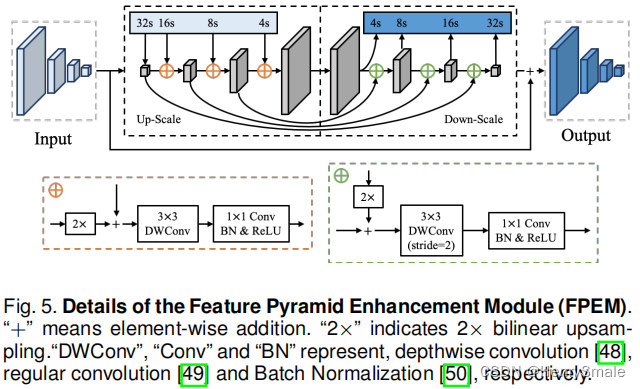
- 针对轻量级网络具有感受野小和表征能力弱的缺点,使用堆叠的特征金字塔增强模块(FPEM)对提取到的特征进行增强;
- FPEM(图5所示):(1)基于可分离卷积构建的U形模块,可以以较小的计算开销增强骨干网络提取的多尺度特征;(2)可堆叠,随着堆叠层数的增加,网络的感受野也将增大。
整体使用的损失函数如下:
L = L det + L r e c . (1) \mathcal{L}=\mathcal{L}_{\text {det }}+\mathcal{L}_{\mathrm{rec}}. \tag1L=Ldet +Lrec.(1)
3.2 文本检测
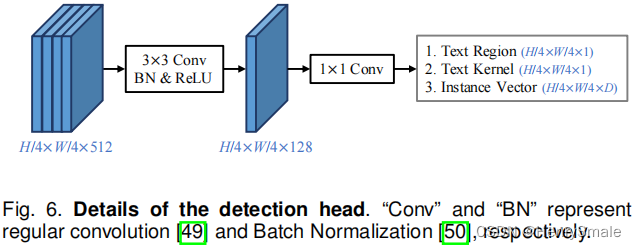
本文提出了一个仅包含两层卷积的轻量级检测头(见图6)来完成文本检测任务。
该检测头同时预测:
- 文本区域;
- 文本内核;
- 实例向量。
通过PA算法将文本区域、文本内核和实例向量进行融合,得到最终的检测结果(见图7)。
- PA借用了聚类的思想;
- 把不同的文本看作不同的簇,则文本内核就是簇的中心,文本区域内的像素就是待聚类的样本。
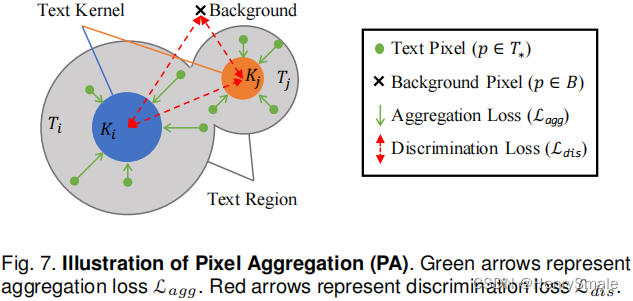
图8是测试阶段。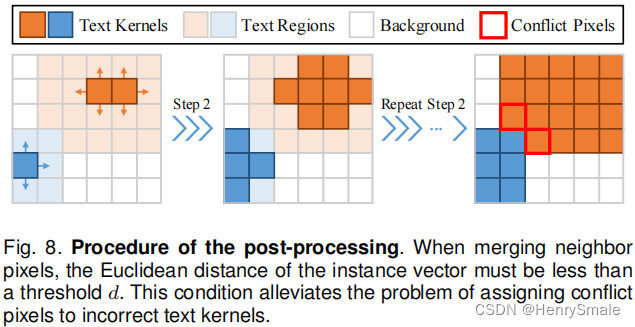
文本检测部分的损失函数如下:
L det = L tex + α L k e r + β ( L a g g + L dis ) . (2) \mathcal{L}_{\text {det }}=\mathcal{L}_{\text {tex }}+\alpha \mathcal{L}_{k e r}+\beta\left(\mathcal{L}_{a g g}+\mathcal{L}_{\text {dis }}\right). \tag2Ldet =Ltex +αLker+β(Lagg+Ldis ).(2)
L tex = 1 − 2 ∑ i P tex ( i ) G tex ( i ) ∑ i P tex ( i ) 2 + ∑ i G tex ( i ) 2 . (3) \mathcal{L}_{\text {tex }}=1-\frac{2 \sum_{i} P_{\text {tex }}(i) G_{\text {tex }}(i)}{\sum_{i} P_{\text {tex }}(i)^{2}+\sum_{i} G_{\text {tex }}(i)^{2}}. \tag3Ltex =1−∑iPtex (i)2+∑iGtex (i)22∑iPtex (i)Gtex (i).(3)
P tex ( i ) P_{\text {tex }}(i)Ptex (i)和G tex ( i ) G_{\text {tex }}(i)Gtex (i)分别指分割结果中第i ii个像素的值和文本区域的真实值。
L k e r = 1 − 2 ∑ i P k e r ( i ) G k e r ( i ) ∑ i P k e r ( i ) 2 + ∑ i G k e r ( i ) 2 . (4) \mathcal{L}_{k e r}=1-\frac{2 \sum_{i} P_{k e r}(i) G_{k e r}(i)}{\sum_{i} P_{k e r}(i)^{2}+\sum_{i} G_{k e r}(i)^{2}}. \tag4Lker=1−∑iPker(i)2+∑iGker(i)22∑iPker(i)Gker(i).(4)
P k e r ( i ) P_{k e r}(i)Pker(i)和G k e r ( i ) G_{k e r}(i)Gker(i)分别指文本核预测中的第i ii个像素值和真实值。
L a g g = 1 N ∑ i = 1 N 1 ∣ T i ∣ ∑ p ∈ T i D 1 ( p , K i ) , D 1 ( p , K i ) = ln ( R ( ∥ F ( p ) − G ( K i ) ∥ − δ a g g ) 2 + 1 ) . (5) \begin{array}{c} \mathcal{L}_{a g g}=\frac{1}{N} \sum_{i=1}^{N} \frac{1}{\left|T_{i}\right|} \sum_{p \in T_{i}} \mathcal{D}_{1}\left(p, K_{i}\right), \\ \mathcal{D}_{1}\left(p, K_{i}\right)=\ln \left(\mathcal{R}\left(\left\|\mathcal{F}(p)-\mathcal{G}\left(K_{i}\right)\right\|-\delta_{a g g}\right)^{2}+1\right) . \end{array} \tag5Lagg=N1∑i=1N∣Ti∣1∑p∈TiD1(p,Ki),D1(p,Ki)=ln(R(∥F(p)−G(Ki)∥−δagg)2+1).(5)
- N NN: 文本行数;
- T i T_{i}Ti: 第i ii个文本行的文本区域;
- K i K_{i}Ki: 文本行T i T_{i}Ti的文本内核K i K_{i}Ki;
- D 1 ( p , K i ) \mathcal{D}_{1}\left(p, K_{i}\right)D1(p,Ki): 文本像素p pp和文本内核K i K_{i}Ki之间的距离;
- R ( ⋅ ) \mathcal{R}(\cdot)R(⋅): ReLU函数,确保输出为非负;
- F ( p ) \mathcal{F}(p)F(p): 像素p pp的实例向量;
- G ( K i ) \mathcal{G}\left(K_{i}\right)G(Ki): 文本内核K i K_{i}Ki的实例向量, 利用下面的公式进行计算: G ( K i ) = ∑ p ∈ K i F ( p ) / ∣ K i ∣ \mathcal{G}\left(K_{i}\right)=\sum_{p \in K_{i}} \mathcal{F}(p) /\left|K_{i}\right|G(Ki)=∑p∈KiF(p)/∣Ki∣;
- δ agg \delta_{\text {agg}}δagg: 常量, 在实验中设置为0.5。
L d i s = 1 N 2 ∑ i = 1 N ( D b ( K i ) + ∑ j = 1 j ≠ i N D 2 ( K i , K j ) ) , D b ( K i ) = 1 ∣ B ∣ ∑ p ∈ B ln ( R ( δ d i s − ∥ F ( p ) − G ( K i ) ∥ ) 2 + 1 ) , D 2 ( K i , K j ) = ln ( R ( δ d i s − ∥ G ( K i ) − G ( K j ) ∥ ) 2 + 1 ) . (6) \begin{array}{c} \mathcal{L}_{d i s}=\frac{1}{N^{2}} \sum_{i=1}^{N}\left(D_{b}\left(K_{i}\right)+\sum_{\substack{j=1 \\ j \neq i}}^{N} \mathcal{D}_{2}\left(K_{i}, K_{j}\right)\right), \\ \mathcal{D}_{b}\left(K_{i}\right)=\frac{1}{|B|} \sum_{p \in B} \ln \left(\mathcal{R}\left(\delta_{d i s}-\left\|\mathcal{F}(p)-\mathcal{G}\left(K_{i}\right)\right\|\right)^{2}+1\right), \\ \mathcal{D}_{2}\left(K_{i}, K_{j}\right)=\ln \left(\mathcal{R}\left(\delta_{d i s}-\left\|\mathcal{G}\left(K_{i}\right)-\mathcal{G}\left(K_{j}\right)\right\|\right)^{2}+1\right). \end{array} \tag6Ldis=N21∑i=1N(Db(Ki)+∑j=1j=iND2(Ki,Kj)),Db(Ki)=∣B∣1∑p∈Bln(R(δdis−∥F(p)−G(Ki)∥)2+1),D2(Ki,Kj)=ln(R(δdis−∥G(Ki)−G(Kj)∥)2+1).(6)
- B BB: 背景.
- D b ( K i ) \mathcal{D}_{b}\left(K_{i}\right)Db(Ki): 文本内核K i K_{i}Ki与背景之间的距离;
- \mathcal{D}{2}\left(K{i}, K_{j}\right): 文本内核K i K_{i}Ki和文本内核K j K_{j}Kj之间的距离;
- \delta_{d i s}: 常量, 在实验中设置为3。
3.3 文本识别
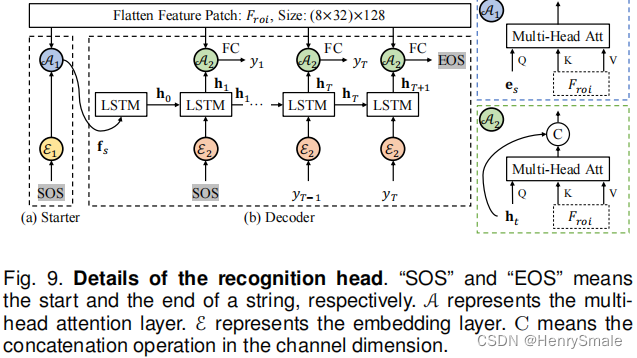
本文提出了一个不规则文字特征提取器Masked RoI和一个基于注意力机制的轻量级识别头来完成文本识别任务。
- Masked RoI:为任意形状的文本提取固定大小的特征块;
- 轻量级识别头:包含两层LSTM和两层多头注意力(见图9)。
文本识别使用的损失函数如下:
L r e c = 1 ∣ w ∣ ∑ i = 0 ∣ w ∣ CrossEntropy ( y i , w i ) . (7) \mathcal{L}_{r e c}=\frac{1}{|w|} \sum_{i=0}^{|w|} \operatorname{CrossEntropy}\left(y_{i}, w_{i}\right). \tag7Lrec=∣w∣1i=0∑∣w∣CrossEntropy(yi,wi).(7)