简介
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、 安全。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
适用的应用场景
- 异步处理:例如短信通知、终端状态推送、App推送、用户注册等
- 数据同步:业务数据推送同步
- 重试补偿:记账失败重试
- 系统解耦:通讯上下行、终端异常监控、分布式事件中心
- 流量消峰:秒杀场景下的下单处理
- 发布订阅:HSF的服务状态变化通知、分布式事件中心
- 高并发缓冲:日志服务、监控上报
一个故事告诉你什么是消息队列
有一天,产品跑来说:“我们要做一个用户注册功能,需要在用户注册成功后给用户发一封成功邮件。”
小明(攻城狮):“好,需求很明确了。” 不就提供一个注册接口,保存用户信息,同时发起邮件调用,待邮件发送成功后,返回用户操作成功。没一会功夫,代码就写完了。验证功能没问题后,就发布上线了。
线上正常运行了一段时间,产品匆匆地跑来说:“你做的功能不行啊,运营反馈注册操作响应太慢,已经有好多用户流失了。”
小明听得一身冷汗,赶紧回去改。他发现,原先的以单线程同步阻塞的方式进行邮件发送,确实存在问题。这次,他利用了 JAVA 多线程的特性,另起线程进行邮件发送,主线程直接返回保存结果。测试通过后,赶紧发布上线。小明心想,这下总没问题了吧。
没过多久,产品又跑来了,他说:“现在,注册操作响应是快多了。但是又有新的问题了,有用户反应,邮件收不到。能否在发送邮件时,保存一下发送的结果,对于发送失败的,进行补发。”
小明一听,哎,又得熬夜加班了。产品看他一脸苦逼的样子,忙说:“邮件服务这块,别的团队都已经做好了,你不用再自己搞了,直接用他们的服务。”
小明赶紧去和邮件团队沟通,谁知他们的服务根本就不对外开放。这下小明可开始犯愁了,明知道有这么一个服务,可是偏偏又调用不了。
邮件团队的人说,“看你愁的,我给你提供了一个类似邮局信箱的东西,你往这信箱里写上你要发送的消息,以及我们约定的地址。之后你就不用再操心了,我们自然能从约定的地址中取得消息,进行邮件的相应操作。”
后来,小明才知道,这就是外界广为流传的消息队列。你不用知道具体的服务在哪,如何调用。你要做的只是将该发送的消息,向你们约定好的地址进行发送,你的任务就完成了。对应的服务自然能监听到你发送的消息,进行后续的操作。这就是消息队列最大的特点,将同步操作转为异步处理,将多服务共同操作转为职责单一的单服务操作,做到了服务间的解耦。
哈哈,这下能高枕无忧了。太年轻,哪有万无一失的技术啊~
不久的一天,你会发现所有业务都替换了邮件发送的方式,统一使用了消息队列来进行发送。这下仅仅一个邮件服务模块,难以承受业务方源源不断的消息,大量的消息堆积在了队列中。这就需要更多的消费者(邮件服务)来共同处理队列中的消息,即所谓的分布式消息处理。
案例原文地址:https://github.com/jasonGeng88/blog/blob/master/201705/MQ.md
安装教程(Windows)
由于RabbitMQ是用Erlang语言编写的,因此需要先安装Erlang。
通过http://www.erlang.org/downloads获取对应安装文件进行安装
增加环境变量ERLANG_HOME=D:\Program Files\erl9.3(这里的目录是我的安装目录,你要换成自己的目录)
修改环境变量Path,在原来的值后面加上“;%ERLANG_HOME%\bin”
安装完Erlang之后,我们就可以安装RabbitMQ了。
到http://www.rabbitmq.com/install-windows-manual.html下载安装包进行安装
增加环境变量RABBITMQ_HOEM=D:\Program Files\RabbitMQ Server\rabbitmq_server-3.7.5(这里的目录是我的安装目录,你要换成自己的目录)
修改环境变量Path,在原来的值后面加上“;%RABBITMQ_HOME%\sbin”
安装好之后,RabbitMQ就作为一个服务按照默认方式进行启动了
启动服务后,直接在服务器中http://127.0.0.1:15672,账号密码默认为guest,guest
服务启动后就可以编写dome了,在编写之前先添加虚拟主机,用于测试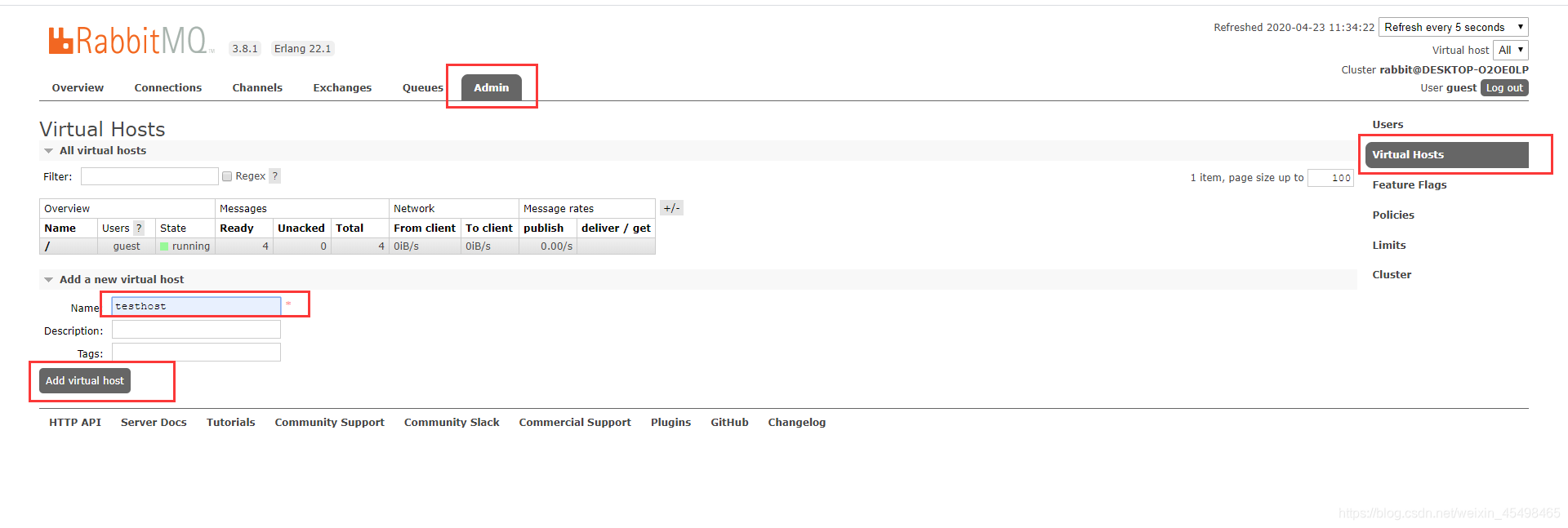
简单队列示例
添加依赖
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>3.4.1</version>
</dependency>
编写链接类
public class ConnectionUtil {
public static Connection getConnection() throws IOException {
//定义连接工厂
ConnectionFactory factory = new ConnectionFactory();
//设置服务地址
factory.setHost("127.0.0.1");
//设置服务端口
factory.setPort(5672);
//设置账号
factory.setUsername("guest");
//设置密码
factory.setPassword("guest");
//设置虚拟主机
factory.setVirtualHost("testhost");
//获取链接
Connection connection = factory.newConnection();
return connection;
}
}
创建生产者,发送消息
public class Producer {
//队列名称
private static final String QUEUE = "simple_queue_message";
public static void main(String[] args) throws Exception {
//获取链接
Connection connection = ConnectionUtil.getConnection();
//创建与Exchange的通道,每个连接可以创建多个通道,每个通道代表一个会话任务
Channel channel = connection.createChannel();
//声明队列,如果Rabbit中没有此队列将自动创建
channel.queueDeclare(QUEUE, true, false, false, null);
String message = "hello world rabbitMQ " + System.currentTimeMillis();
//消息发布方法
channel.basicPublish("", QUEUE, null, message.getBytes());
System.out.println("Send Message is:'" + message + "'");
//关闭资源
channel.close();
connection.close();
}
}
创建消费者,消费消息
public class Receive {
private static final String QUEUE = "simple_queue_message";
public static void main(String[] args) throws Exception {
//获取链接
Connection connection = ConnectionUtil.getConnection();
//创建与Exchange的通道,每个连接可以创建多个通道,每个通道代表一个会话任务
Channel channel = connection.createChannel();
//声明队列,如果Rabbit中没有此队列将自动创建
channel.queueDeclare(QUEUE, true, false, false, null);
// 监听队列
Consumer consumer = new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws UnsupportedEncodingException {
String message = new String(body,"utf-8");
System.out.println(" Received '" + message + "'");
}
};
//回调
channel.basicConsume(QUEUE, true, consumer);
}
}
RabbitMQ的优势
解耦
看这么个场景。A 系统发送数据到 BCD 三个系统,通过接口调用发送。如果 E 系统也要这个数据呢?那如果 C 系统现在不需要了呢?A 系统负责人几乎崩溃…
在这个场景中,A 系统跟其它各种乱七八糟的系统严重耦合,A 系统产生一条比较关键的数据,很多系统都需要 A 系统将这个数据发送过来。A 系统要时时刻刻考虑 BCDE 四个系统如果挂了该咋办?要不要重发,要不要把消息存起来?头发都白了啊!
如果使用 MQ,A 系统产生一条数据,发送到 MQ 里面去,哪个系统需要数据自己去 MQ 里面消费。如果新系统需要数据,直接从 MQ 里消费即可;如果某个系统不需要这条数据了,就取消对 MQ 消息的消费即可。这样下来,A 系统压根儿不需要去考虑要给谁发送数据,不需要维护这个代码,也不需要考虑人家是否调用成功、失败超时等情况。
异步
再来看一个场景,A 系统接收一个请求,需要在自己本地写库,还需要在 BCD 三个系统写库,自己本地写库要 3ms,BCD 三个系统分别写库要 300ms、450ms、200ms。最终请求总延时是 3 + 300 + 450 + 200 = 953ms,接近 1s,用户感觉搞个什么东西,慢死了慢死了。用户通过浏览器发起请求,等待个 1s,这几乎是不可接受的。
一般互联网类的企业,对于用户直接的操作,一般要求是每个请求都必须在 200 ms 以内完成,对用户几乎是无感知的。
如果使用 MQ,那么 A 系统连续发送 3 条消息到 MQ 队列中,假如耗时 5ms,A 系统从接受一个请求到返回响应给用户,总时长是 3 + 5 = 8ms,对于用户而言,其实感觉上就是点个按钮,8ms 以后就直接返回了,爽!网站做得真好,真快!
削峰
每天 0:00 到 12:00,A 系统风平浪静,每秒并发请求数量就 50 个。结果每次一到 12:00 ~ 13:00 ,每秒并发请求数量突然会暴增到 5k+ 条。但是系统是直接基于 MySQL 的,大量的请求涌入 MySQL,每秒钟对 MySQL 执行约 5k 条 SQL。
一般的 MySQL,扛到每秒 2k 个请求就差不多了,如果每秒请求到 5k 的话,可能就直接把 MySQL 给打死了,导致系统崩溃,用户也就没法再使用系统了。
但是高峰期一过,到了下午的时候,就成了低峰期,可能也就 1w 的用户同时在网站上操作,每秒中的请求数量可能也就 50 个请求,对整个系统几乎没有任何的压力。
如果使用 MQ,每秒 5k 个请求写入 MQ,A 系统每秒钟最多处理 2k 个请求,因为 MySQL 每秒钟最多处理2k 个。A 系统从 MQ 中慢慢拉取请求,每秒钟就拉取 2k 个请求,不要超过自己每秒能处理的最大请求数量就 ok,这样下来,哪怕是高峰期的时候,A 系统也绝对不会挂掉。而 MQ 每秒钟 5k 个请求进来,就 2k个请求出去,结果就导致在中午高峰期(1 个小时),可能有几十万甚至几百万的请求积压在 MQ 中。
这个短暂的高峰期积压是 ok 的,因为高峰期过了之后,每秒钟就 50 个请求进 MQ,但是 A 系统依然会按照每秒 2k 个请求的速度在处理。所以说,只要高峰期一过,A 系统就会快速将积压的消息给解决掉。
消息队列有什么优缺点
优点上面已经说了,就是在特殊场景下有其对应的好处,解耦、异步、削峰。
RabbitMQ的劣势
系统可用性降低
系统引入的外部依赖越多,越容易挂掉。本来你就是 A 系统调用 BCD 三个系统的接口就好了,人ABCD 四个系统好好的,没啥问题,你偏加个 MQ 进来,万一 MQ 挂了咋整,MQ 一挂,整套系统崩溃的,你不就完了?
系统复杂度提高
硬生生加个 MQ 进来,你怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性?头大头大,问题一大堆,痛苦不已。
一致性问题
A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了。
所以消息队列实际是一种非常复杂的架构,你引入它有很多好处,但是也得针对它带来的坏处做各种额外的技术方案和架构来规避掉,做好之后,你会发现,系统复杂度提升了一个数量级,也许是复杂了 10倍。但是关键时刻,用,还是得用的。
后续学习方向
通过上面的介绍,我们已经知道MQ如何使用,及它的优缺点是什么。后期我们主要针对它的缺点进行优化,提供解决思路,并编写相关dome。还有rabbitmq的各种模式,如Work模式、消息的确认模式、订阅模式、路由模式、通配符模式等等进行深入学习。
相关博文:
RabbitMQ系列(一)工作队列模式
RabbitMQ系列(二)确认模式
RabbitMQ系列(三)发布订阅模式
RabbitMQ系列(四)路由模式
RabbitMQ系列(五)主题模式