a.什么是激活函数
b.为什么要用激活函数 c.常用激活函数 2、逻辑回归 a.损失函数 b.成本函数 三、神经网络结构与原理 1、基本结构及表示方法 a.神经元模型 b.神经网络模型 2、神经网络输出计算过程ONE简介 01 神经网络是什么 神经网络是机器学习中的一种模型,是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。02 神经网络分类 刚刚入门神经网络,往往会对众多的神经网络架构感到困惑,神经网络看起来复杂多样,但是这么多架构无非也就是三类:前馈式网络、反馈式网络、图网络。[1] 前馈神经网络 FFNN,Feedforward Neural Network 输入:向量或向量序列 包括:全连接前馈神经网络,卷积神经网络 表示:有向无环图
信息传播:朝着一个方向(反向传播和这个不是同一个概念)
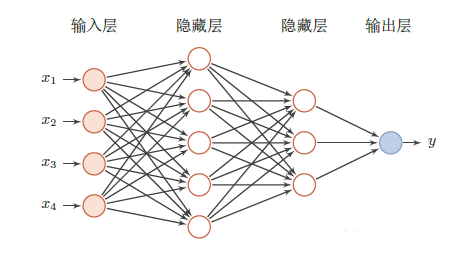
前馈神经网络是我们接触到论文中最常用的一种神经网络,简称前馈网络。是实际应用中最常见的神经网络结构,是人工神经网络的一种,前馈描述的是网络的结构,指的是网络的信息流是单向的,不会构成环路。在此种神经网络中,各神经元从输入层开始,接收前一级输入,并输出到下一级,直至输出层。整个网络中无反馈,可用一个有向无环图表示。
前馈神经网络采用一种单向多层结构,其拓扑结构如上图所示。其中每一层包含若干个神经元,同一层的神经元之间没有互相连接,层间信息的传送只沿一个方向进行。其中第一层称为输入层。最后一层为输出层,中间为隐含层,简称隐层。隐层可以是一层。也可以是多层。增强网络的分类和识别能力、解决非线性问题的唯一途径是采用多层前馈前馈网络,即在输入层和输出层之间加上隐含层,构成多层前对感知器网络。[2]
延展1:前馈神经网络和BP神经网络是一个东西吗 BP神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,是在前馈神经网络的基础上应用了BP算法(下一节会讲到),属于前馈神经网络的一种。BP神经网络的基本思想是梯度下降法,利用梯度搜索技术,以期望使得网络的实际输出值和期望输出值的误差均方差最小。[3] 延展2:人工神经网络和神经网络是说的一个东西吗 除生物体神经网络实体外所有人为创造的神经网络结构均可称为人工神经网络,机器学习文献上的模型大多属于这个范畴,几乎涵盖所有我们研究的神经网络。所以我认为人工神经网络≈神经网络。 延展3:人工神经网络(ANN)、前馈神经网络和BP神经网络的关系 人工神经网络包括前馈神经网络,BP神经网络属于前馈神经网络的一种,在前馈神经网络的基础上应用了BP算法用来优化参数以学习并接近真实值。 反馈神经网络 FDNN, feedback neural network 输入:向量或向量序列(多个特征X1、X2…) 包括:循环神经网络(RNN),Hopfieid网络,波尔兹曼机 表示:有向循环图或者无向图 信息传播:可单向,可双向,可以自己到自己 神经元:有记忆功能,在不同时刻有不同状态。(为进一步增强网络记忆容量,可引入外部记忆单元和读写机制,以保存网络中间状态,如神经图灵机)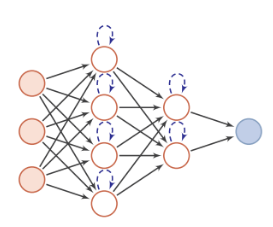
人工神经网络特有的非线性适应性信息处理能力,克服了传统人工智能方法对于直觉,如模式、语音识别、非结构化信息处理方面的缺陷,使之在神经专家系统、模式识别、智能控制、组合优化、预测等领域得到成功应用。人工神经网络与其它传统方法相结合,将推动人工智能和信息处理技术不断发展。近年来,人工神经网络正向模拟人类认知的道路上更加深入发展,与模糊系统、遗传算法、进化机制等结合,形成计算智能,成为人工智能的一个重要方向,将在实际应用中得到发展。
笔者将在今后的内容分享中偏重基于时间序列的数据预测领域,这也是我今后研究的一个大方向。
TWO神经网络编程基础01 激活函数 l 什么是激活函数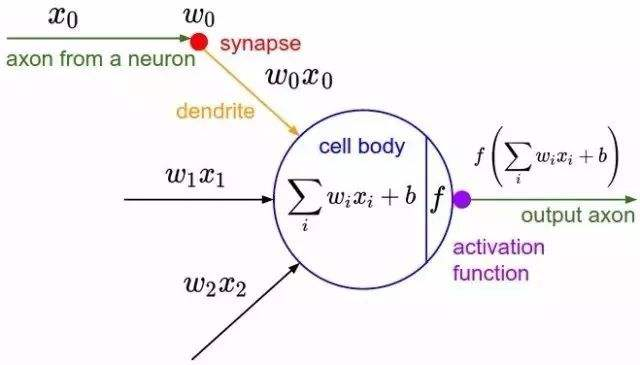
 激活函数(Activation functions)对于人工神经网络模型去学习、理解非常复杂和非线性的函数来说具有十分重要的作用。它们将 非线性特性 引入到我们的网络中。如上图,在神经元中,输入的 inputs 通过加权,求和后,还被作用了一个函数,这个函数就是激活函数。 引入激活函数是为了增加神经网络模型的非线性。没有激活函数的每层都相当于矩阵相乘。就算你叠加了若干层之后,无非还是个矩阵相乘罢了。 l 为什么要用激活函数 如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,这种情况就是最原始的感知机。 如果使用的话,激活函数给神经元引入了 非线性因素 ,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。 l 常用的激活函数 Sigmoid函数
激活函数(Activation functions)对于人工神经网络模型去学习、理解非常复杂和非线性的函数来说具有十分重要的作用。它们将 非线性特性 引入到我们的网络中。如上图,在神经元中,输入的 inputs 通过加权,求和后,还被作用了一个函数,这个函数就是激活函数。 引入激活函数是为了增加神经网络模型的非线性。没有激活函数的每层都相当于矩阵相乘。就算你叠加了若干层之后,无非还是个矩阵相乘罢了。 l 为什么要用激活函数 如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,这种情况就是最原始的感知机。 如果使用的话,激活函数给神经元引入了 非线性因素 ,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。 l 常用的激活函数 Sigmoid函数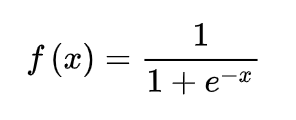
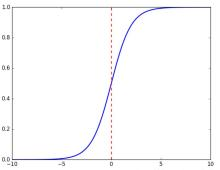
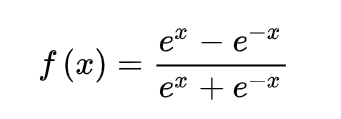
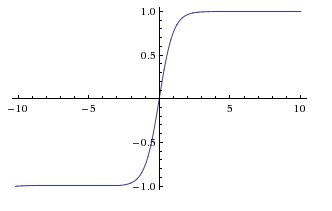
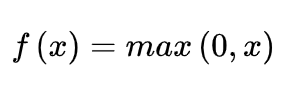
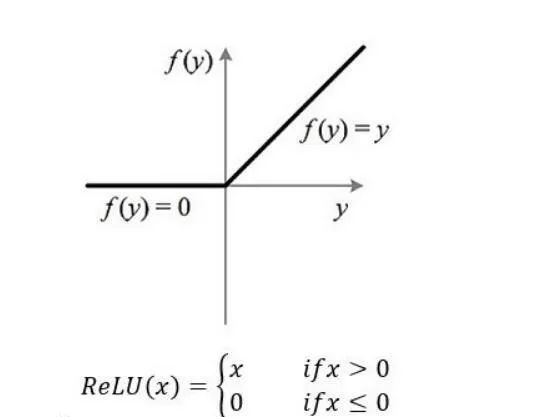
ReLU(Rectified Linear Unit)函数是目前比较火的一个激活函数,相比于sigmoid函数和tanh函数,它有以下几个优点: 1) 在输入为正数的时候,不存在 梯度饱和问题 。 2) 计算速度要快很多。ReLU函数 只有线性关系 ,不管是前向传播还是反向传播,都比sigmoid和tanh要快很多。( sigmoid和tanh要计算指数,计算速度会比较慢 ) 当然,缺点也是有的: 1) 当输入是负数的时候,ReLU是完全不被激活的,这就表明一旦输入到了负数,ReLU就会死掉。 这样在前向传播过程中,还不算什么问题,有的区域是敏感的,有的是不敏感的。 但是到了反向传播过程中,输入负数,梯度就会完全到0,这个和sigmoid函数、tanh函数有一样的问题。 2) 我们发现ReLU函数的输出要么是0,要么是正数,这也就是说, ReLU函数也不是以0为中心的函数。 除三种常见的激活函数外,还有ELU函数、PReLU函数,选择哪种激活函数都要视情况而定,具体讲解请看引用文献。[5] 02 逻辑回归 逻辑回归是一种线性回归分析模型,输入为常见的多个特征,输出的因变量可以为二分类,也可以是多分类,但大多时候 用于二分类 。 同时,逻辑回归也是一种广义线性回归,因此与多重线性回归分析有很多相同之处。它们的模型形式基本上相同,都具有 w‘x+b,其中w和b是 待求参数 ,其区别在于他们的因变量不同,多重线性回归直接将w‘x+b作为因变量,即y =w‘x+b,而logistic回归则通过函数L将w‘x+b对应一个隐状态p,p =L(w‘x+b), 然后根据p 与1-p的大小决定因变量的值 。如果L是logistic函数,就是logistic回归,如果L是多项式函数就是多项式回归。 [6] 此处我将以Logistic回归模型为例去解释两个概念:损失函数和成本函数。 a. 损失函数 损失函数L(y^,y)是为了衡量预测输出的y^和实际值y有多接近。 损失函数计算过程: ① y^=σ(wx+b), σ=1/1+e-x ----运用激活函数求预测值 ② L(y^,y)= -[y*logy^ +(1-y)log(1-y^)] ----求损失函数 在②求损失函数的时候这里为什么不用 L(y^,y)=1/2*(y^-y)2是因为 之后讨论的优化问题会变成非凸的,会有很多局部最优解,运用梯度下降法可能找不到全局最 优解。 b. 成本函数 为了训练Logistic回归模型的参数w和b,需要定义一个成本函数J(w,b),让模型通过学习来调整参数。 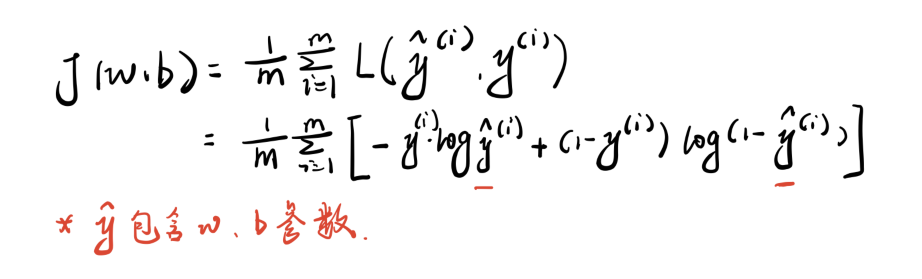
| 符号 | 含义 |
| (x(1),y(1)) | 第一个样本的一系列特征值x及表现结果y;其中x为特征向量(多个特征) |
| X∈nx | x是nx维的特征向量; nx有时也会写成n |
| m | 训练集样本个数;有时为强调是训练样本,写成m=mtrain |
| y^ | 表示神经网络输出的预测值;通常与真实值y进行比对 |
| wij | 神经元之间连线上的连接权值 |
| bk | 神经元上的阈值 |
| α | 人为给定的学习速率 |
a. 神经元模型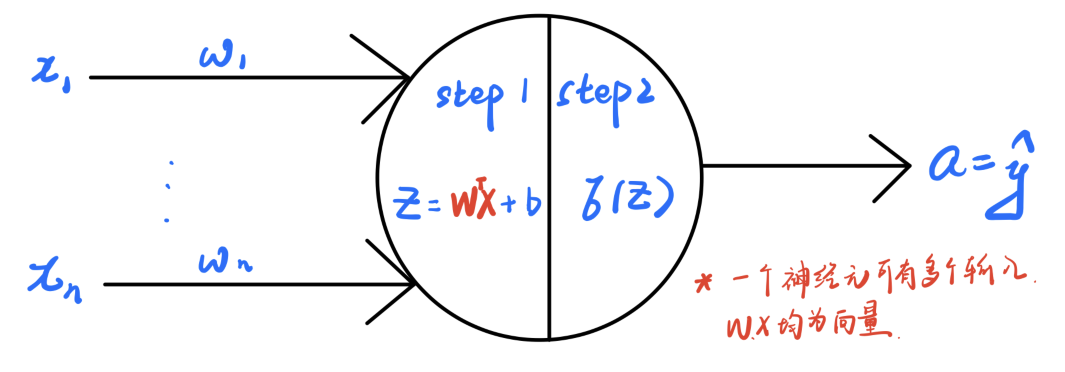
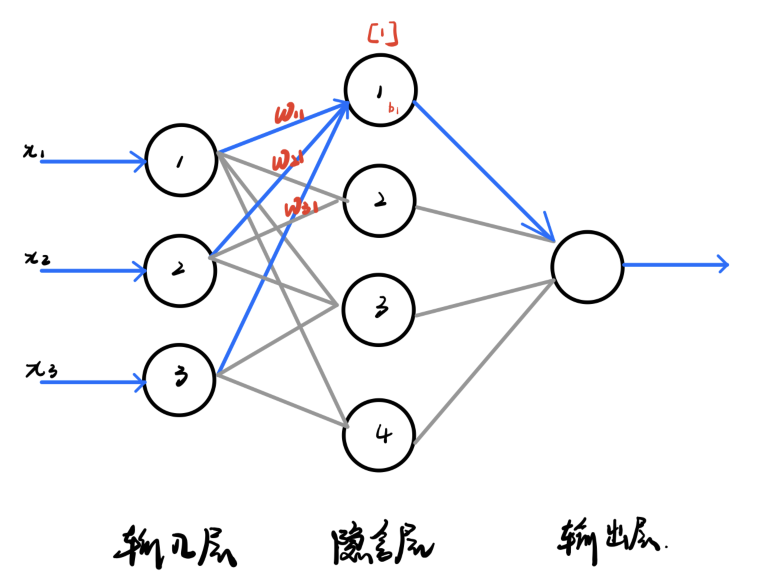

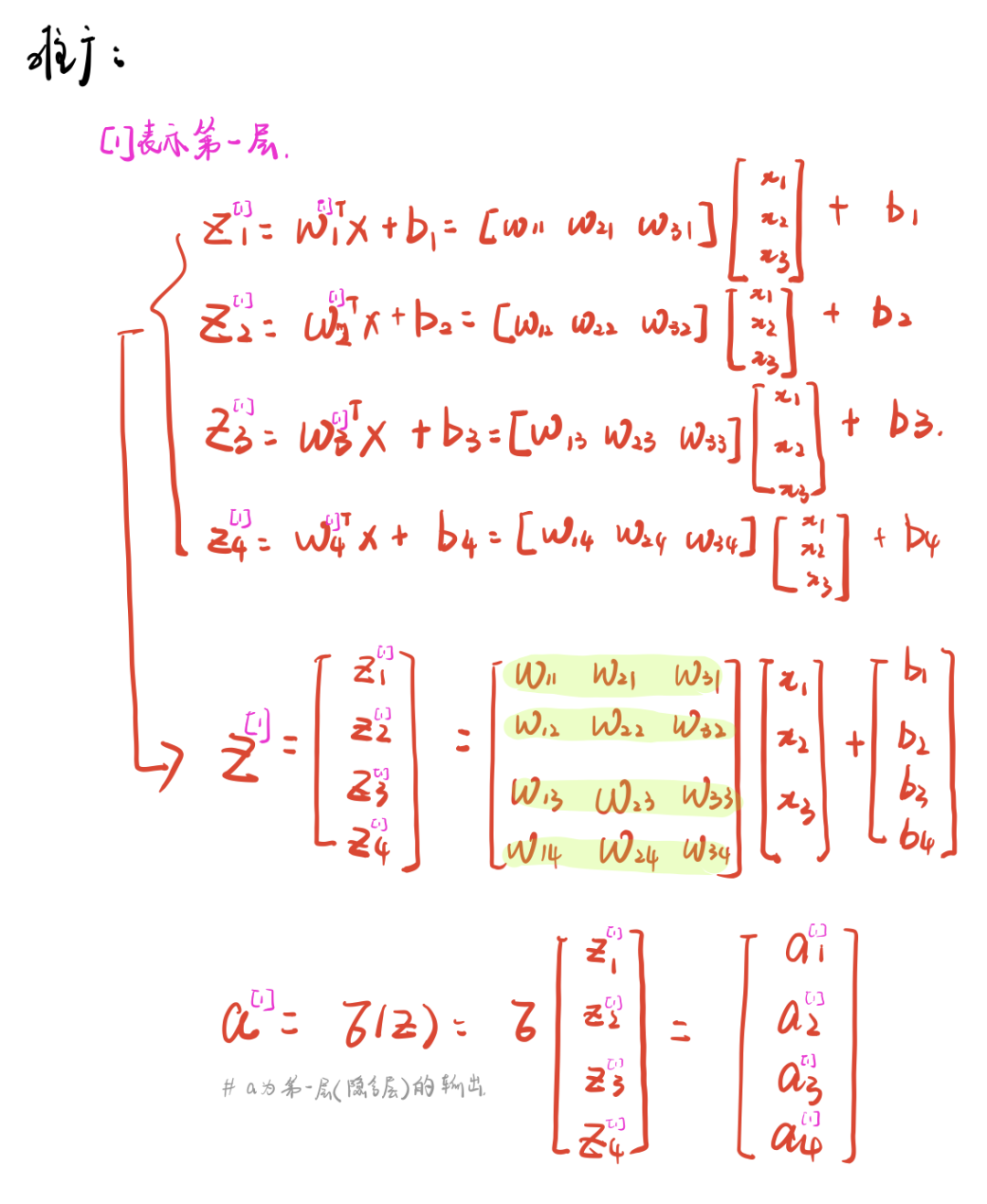
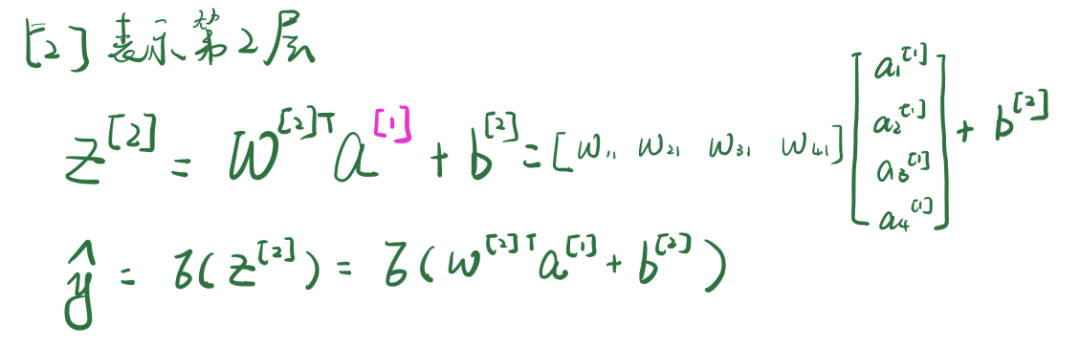
[1]深度学习——神经网络的种类(前馈神经网络,反馈神经网络,图网络)
https://blog.csdn.net/weiwei935707936/article/details/97611676
[2]前馈型神经网络与反馈型神经网络
https://www.jianshu.com/p/0bc5aacdd168
[3]百度百科- BP神经网络
https://baike.baidu.com/item/BP%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/4581827?fr=aladdin
[4]百度百科-循环神经网络
https://baike.baidu.com/item/%E5%BE%AA%E7%8E%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/23199490?fr=aladdin
[5]CSDN-几种常用激活函数的简介
https://blog.csdn.net/kangyi411/article/details/78969642
[6]百度百科-逻辑回归
https://baike.baidu.com/item/logistic%E5%9B%9E%E5%BD%92/2981575?fromtitle=%E9%80%BB%E8%BE%91%E5%9B%9E%E5%BD%92&fromid=17202449#reference-[1]-2294104-wrap