| ? | Powered By HeartFireY | Segment Tree |
一、线段树简介
线段树是算法竞赛中常用的用来维护 区间信息 的数据结构。
线段树可以在 O ( log N ) O(\log N)O(logN) 的时间复杂度内实现单点修改、区间修改、区间查询(区间求和,求区间最大值,求区间最小值)等操作。
线段树维护的信息,需要满足可加性,即能以可以接受的速度合并信息和修改信息,包括在使用Lazy标记时,标记也要满足可加性
注:可加性表示运算能否合并,例如取模就不满足可加性,对4 44 取模然后对 3 33 取模,两个操作就不能合并在一起做。
二、线段树的基本结构
1.什么是线段树
线段树将每个长度不为 1 11 的区间划分成左右两个区间递归求解,把整个线段划分为一个树形结构,通过合并左右两区间信息来求得该区间的信息。这种数据结构可以方便的进行大部分的区间操作。
我们举例来说明线段树的基本结构:
我们给出一个数组A = { 11 , 22 , 33 , 44 , 55 } A = \{11, \ 22, \ 33, \ 44, \ 55 \}A={11, 22, 33, 44, 55},我们开始针对这个数组构造线段树,首先将根节点编号设为1 11,用数组D DD来保存线段树,其中D i D_iDi保存线段树上编号为i ii的结点的值(每个结点所维护的值就是这个节点所表示的区间总和),如下图所示:
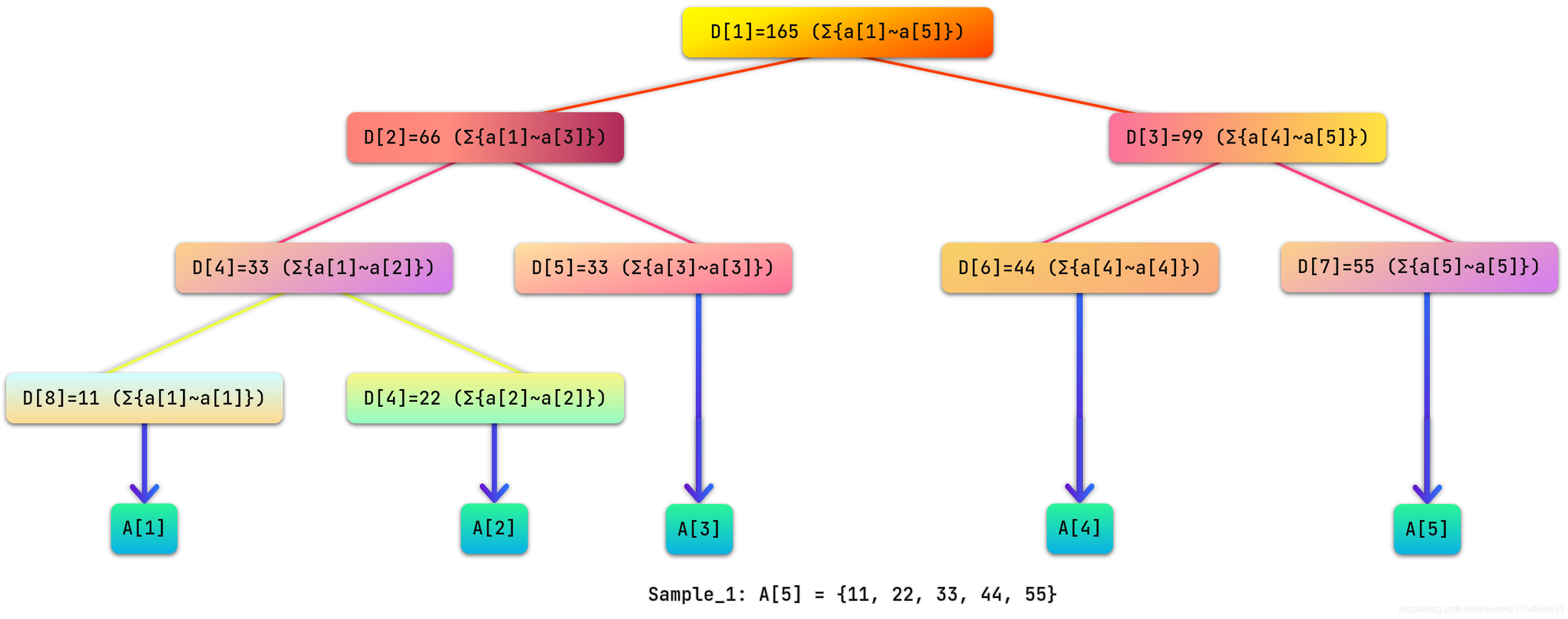
图中 D 1 D_1D1 表示根节点, $ D_1$ 所表示的区间就是 [ 1 , 4 ] [1,4][1,4](a 1 , a 2 , ⋯ , a 5 a_1,a_2, \cdots ,a_5a1,a2,⋯,a5),其值为∑ i = 1 n = 5 A i \sum^{n = 5}_{i = 1}A_i∑i=1n=5Ai,其余结点类推。
通过观察不难发现,D i D_iDi 的左儿子节点就是 D 2 × i D_{2\times i}D2×i,D i D_iDi 的右儿子节点就是 D 2 × i + 1 D_{2\times i+1}D2×i+1。如果 D i D_iDi 表示的是区间 [ s , t ] [s,t][s,t](即 D i = A s + A s + 1 + ⋯ + A t D_i=A_s+A_{s+1}+ \cdots +A_tDi=As+As+1+⋯+At) 的话,那么 D i D_iDi 的左儿子节点表示的是区间 [ s , s + t 2 ] [ s, \frac{s+t}{2} ][s,2s+t],D i D_iDi 的右儿子表示的是区间 [ s + t 2 + 1 , t ] [ \frac{s+t}{2} +1,t ][2s+t+1,t]。
2.线段树的建立
首先我们选择堆式储存,即用数组对线段树进行储存(那么2 p 2p2p 是 p pp 的左儿子,2 p + 1 2p+12p+1 是 p pp 的右儿子),若有 n nn 个叶子结点,则 d 数组的范围最大为 2 ⌈ log n ⌉ + 1 2^{\left\lceil\log{n}\right\rceil+1}2⌈logn⌉+1。在实际操作中,我们一般把数组的大小开到4 n 4n4n,即4倍数据范围。(同时,建议关闭C++堆栈限制)。
分析:容易知道线段树的深度是 ⌈ log n ⌉ \left\lceil\log{n}\right\rceil⌈logn⌉ 的,则在堆式储存情况下叶子节点(包括无用的叶子节点)数量为 2 ⌈ log n ⌉ 2^{\left\lceil\log{n}\right\rceil}2⌈logn⌉ 个,又由于其为一棵完全二叉树,则其总节点个数 2 ⌈ log n ⌉ + 1 − 1 2^{\left\lceil\log{n}\right\rceil+1}-12⌈logn⌉+1−1。
在实际使用过程中,我们可以直接将数组的大小开到4 n 4n4n,因为 2 ⌈ log n ⌉ + 1 − 1 n \frac{2^{\left\lceil\log{n}\right\rceil+1}-1}{n}n2⌈logn⌉+1−1 的最大值在 n = 2 x + 1 ( x ∈ N + ) n=2^{x}+1(x\in N_{+})n=2x+1(x∈N+) 时取到,此时节点数为 2 ⌈ log n ⌉ + 1 − 1 = 2 x + 2 − 1 = 4 n − 5 2^{\left\lceil\log{n}\right\rceil+1}-1=2^{x+2}-1=4n-52⌈logn⌉+1−1=2x+2−1=4n−5。
线段树一般采用递归建树,从根节点开始向下递归建左子树右子树。
那么我们讨论递归建树的边界:如果 D i D_iDi 表示的区间大小等于 1 11 的话(区间大小指的是区间包含的元素的个数,即 A AA的个数。设 D j D_jDj 表示区间 [ l , r ] [l,r][l,r],它的区间大小就是 r − l + 1 r-l+1r−l+1),那么 D i D_iDi 所表示的区间 [ l , r ] [l,r][l,r] 中肯定有 l = r l=rl=r,且 D i = A l = A r D_i=A_l=A_rDi=Al=Ar。这就是线段树的递归边界。
我们通过图片来说明建树的基本思路:



同时,我们通过动态示意图来展示递归执行的过程(以下过程展示的是区间最大值线段树):

了解了具体的过程,那么我们就可以通过代码进行实现:
这里我们先介绍几个基本运算的表达方式:设当前结点下标为r t rtrt
求当前结点的左子下标:r t × 2 ⟺ r t < < 1 rt \times 2 \ \Longleftrightarrow \ rt << 1rt×2 ⟺ rt<<1
求当前结点的右子下标:r t × 2 + 1 ⟺ r t < < 1 ∣ 1 rt \times 2 + 1 \ \Longleftrightarrow rt << 1 \ | \ 1rt×2+1 ⟺rt<<1 ∣ 1
合并/上传操作:这种操作一般是从儿子节点更新父节点。可以单独写一个函数p u s h _ u p ( i n t l , i n t r ) push\_up(int \ l, \ int \ r)push_up(int l, int r)或者m e r g e mergemerge函数,由于要进行的操作可能被频繁的执行多次,因此一般将这种函数进行内联展开。
void build(int rt, int l, int r){
if(l == r){
d[rt] = a[l]
return;
}
int mid = l + r >> 1;
build(rt << 1, l, mid);
build(rt << 1 | 1, mid + 1, r);
push_up(rt << 1, rt << 1 | 1)
//如果是求和线段树,则上传操作代表:d[rt] = d[rt * 2] + d[(rt * 2) + 1];
}
3.线段树的区间查询
区间查询是指:求区间 [ l , r ] [l,r][l,r] 的总和(即 a l + a l + 1 + ⋯ + a r a_l+a_{l+1}+ \cdots +a_ral+al+1+⋯+ar)、求区间最大值/最小值等操作。
再次回顾线段树的结构,不难发现,对于查询一个给定的区间,并不能很直接的查询到区间的值
一般而言,如果我们要查询区间 [ l , r ] [l,r][l,r],则可以将其拆成最多为 O ( log n ) O(\log n)O(logn) 个 极大 的区间,合并这些区间即可求出 [ l , r ] [l,r][l,r] 的答案。
代码的具体实现思路并不难,实际上就是不断查询区间的交集,以此实现缩小查找区间范围的过程。
我们可以通过一个直观的动图来模拟区间查询的过程:

了解了过程之后,实现起来就比较简单了,代码实现如下:
//[L,R] 为查询区间,[l,r] 为当前节点包含的区间, rt为当前节点的编号
int query(int rt, int l, int r, int L, int R){
//当前区间为询区间的子集时直接或返回当前区间的和
if(l >= L && r <= R) return d[rt];
int mid = l + r >> 1, ans = 0;
//如果左儿子代表的区间[L, mid]与询问区间存在交集,则递归查询左儿子
if(l <= mid) ans += query(rt << 1, l, mid, L, R);
//如锅右儿子代表的区间[mid + 1, R]与询问区间存在交集,则递归查询右儿子
if(r > mid) ans += query(rt << 1 | 1, mid + 1, r, L, R);
return ans;
}
4.线段树的区间修改
同样,我们使用r t rtrt表示当前结点的下标,用x xx表示修改的结点的值,v vv表示要修改的目标值,l , r l, \ rl, r表示查询区间。
试分析区间修改的过程,发现如果要求修改区间 [ l , r ] [l,r][l,r],把所有包含在区间 [ l , r ] [l,r][l,r] 中的节点都遍历一次、修改一次。这样的操作显然需要消耗大量的时间,与我们一开始对线段树的期望背道而驰。因此我们需要一种方法,是线段树的修改更加的高效。
因此在这里,我们需要引入L a z y LazyLazy标记。什么是L a z y LazyLazy标记,如何理解?这里引用一个经典的故事:
A 有两个儿子,一个是 B,一个是 C。
有一天 A 要建一个新房子,没钱。刚好过年嘛,有人要给 B 和 C 红包,两个红包的钱数相同都是 1 11 元,然而因为 A 是父亲所以红包肯定是先塞给 A 咯~
理论上来讲 A 应该把两个红包分别给 B 和 C,但是……缺钱嘛,A 就把红包偷偷收到自己口袋里了。
A 高兴地说:「我现在有 2 22 份红包了!我又多了 2 × 1 = 2 2\times 1=22×1=2 元了!哈哈哈~」
但是 A 知道,如果他不把红包给 B 和 C,那 B 和 C 肯定会不爽然后导致家庭矛盾最后崩溃,所以 A 对儿子 B 和 C 说:「我欠你们每人 1 11 份 1 11 元的红包,下次有新红包给过来的时候再给你们!这里我先做下记录……嗯……我欠你们各 1 11 元……」
儿子 B、C 有点恼怒:「可是如果有同学问起我们我们收到了多少红包咋办?你把我们的红包都收了,我们还怎么装?」
父亲 A 赶忙说:「有同学问起来我就会给你们的!我欠条都写好了不会不算话的!」
这样 B、C 才放了心。
在这个故事中我们不难看出,A 就是父亲节点,B 和 C 是 A 的儿子节点,而且 B 和 C 是叶子节点,分别对应一个数组中的值(就是之前讲的数组 a aa),我们假设节点 A 表示区间 [ 1 , 2 ] [1,2][1,2](即 a 1 + a 2 a_1+a_2a1+a2),节点 B 表示区间 [ 1 , 1 ] [1,1][1,1](即 a 1 a_1a1),节点 C 表示区间 [ 2 , 2 ] [2,2][2,2](即 a 2 a_2a2),它们的初始值都为 0 00(现在才刚开始呢,还没拿到红包,所以都没钱)。
我们用一棵简单的线段树来展示L a z y LazyLazy标记的具体实现:
首先,我们定义一个D A T A = 1 e 18 DATA = 1e18DATA=1e18,这个D A T A DATADATA表示的是一个非常大的数。同时我们声明一颗线段树,其原始序列A [ ] A[]A[](仅含两个元素)。初始状态下所有结点的L a z y LazyLazy标记为0 00。如图所示:

现在我们需要将这个D A T A DATADATA加到子结点上,从父结点D [ 1 ] D[1]D[1]出发,需要进行两次操作(如果线段树的子节点很多,那么需要进行非常多次的操作),显然是非常耗时的,我们不妨将要给两个子节点D [ 2 ] D[2]D[2]、D [ 3 ] D[3]D[3]增加的值暂存到父节点的L a z y LazyLazy标记中,即D [ 1 ] . L a z y _ V a l = D A T A D[1].Lazy\_Val = DATAD[1].Lazy_Val=DATA,等子节点需要使用的时候再进行下载操作(还给子节点),这样便省去了两次相加的操作。

那么接下来我们模拟查询过程中下载L a z y LazyLazy标记的操作。
如果我们需要查询区间A [ 1 , 1 ] A[1, 1]A[1,1]的值(即查询结点D [ 2 ] D[2]D[2]的值),那么结点D [ 1 ] D[1]D[1]需要将它欠的值返还给D [ 2 ] D[2]D[2]。
首先我们从根节点D [ 1 ] D[1]D[1]开始遍历,对当前节点的L a z y LazyLazy标记进行检查,如果L a z y _ V a l > 0 Lazy\_Val > 0Lazy_Val>0则说明当前结点对它的两个子节点有暂存值:

显然,结点D [ 1 ] D[1]D[1]对它的两个结点有暂存值,因此我们需要对当前节点D [ 1 ] D[1]D[1]的L a z y LazyLazy标记中储存的值下载到子节点的值中,即:将节点D [ 2 ] D[2]D[2]、D [ 3 ] D[3]D[3]的值加上D A T A DATADATA;
同时,我们还需要将当前结点D [ 1 ] D[1]D[1]的L a z y LazyLazy标记进行下载操作,即:将节点D [ 2 ] D[2]D[2]、D [ 3 ] D[3]D[3]的L a z y LazyLazy标记值修改为其父亲节点/当前结点的L a z y LazyLazy标记的值,表示节点D [ 2 ] D[2]D[2]、D [ 3 ] D[3]D[3]也对他们的儿子具有暂存值,最后将父节点/当前结点D [ 1 ] D[1]D[1]的L a z y LazyLazy标记清空,表示不再"亏欠"。这便是“标记下载”。
此时,线段树示意图如下:

我们继续遍历,向下寻找。发现:结点D [ 2 ] D[2]D[2]表示的区间A [ 1 , 1 ] A[1,1]A[1,1]包含于我们要查询的区间A [ 1 , 1 ] A[1,1]A[1,1]中,则返回值为0 + D A T A = D A T A 0 + DATA = DATA0+DATA=DATA,查询操作结束。
了解了L a z y LazyLazy标记的原理以及执行过程,那么我们就可以通过代码来实现区间修改了:
区间修改(区间增加值)
void update(int l, int r, int c, int s, int t, int p){
// [l,r] 为修改区间,c 为被修改的元素的变化量,[s,t] 为当前节点包含的区间,p
// 为当前节点的编号
if (l <= s && t <= r){
d[p] += (t - s + 1) * c, b[p] += c;
return;
} // 当前区间为修改区间的子集时直接修改当前节点的值,然后打标记,结束修改
int m = (s + t) / 2;
if (b[p] && s != t){
// 如果当前节点的懒标记非空,则更新当前节点两个子节点的值和懒标记值
d[p * 2] += b[p] * (m - s + 1), d[p * 2 + 1] += b[p] * (t - m);
b[p * 2] += b[p], b[p * 2 + 1] += b[p]; // 将标记下传给子节点
b[p] = 0; // 清空当前节点的标记
}
if (l <= m) update(l, r, c, s, m, p * 2);
if (r > m) update(l, r, c, m + 1, t, p * 2 + 1);
d[p] = d[p * 2] + d[p * 2 + 1];
}
区间查询
int getsum(int l, int r, int s, int t, int p) {
// [l,r] 为查询区间,[s,t] 为当前节点包含的区间,p为当前节点的编号
if (l <= s && t <= r) return d[p];
// 当前区间为询问区间的子集时直接返回当前区间的和
int m = (s + t) / 2;
if (b[p]) {
// 如果当前节点的懒标记非空,则更新当前节点两个子节点的值和懒标记值
d[p * 2] += b[p] * (m - s + 1), d[p * 2 + 1] += b[p] * (t - m),
b[p * 2] += b[p], b[p * 2 + 1] += b[p]; // 将标记下传给子节点
b[p] = 0; // 清空当前节点的标记
}
int sum = 0;
if (l <= m) sum = getsum(l, r, s, m, p * 2);
if (r > m) sum += getsum(l, r, m + 1, t, p * 2 + 1);
return sum;
}
区间修改(区间修改值)
如果要实现区间修改为某一个值而不是加上某一个值的话,代码如下:
void update(int l, int r, int c, int s, int t, int p)
{
if (l <= s && t <= r){
d[p] = (t - s + 1) * c, b[p] = c;
return;
}
int m = (s + t) / 2;
if (b[p]){
d[p * 2] = b[p] * (m - s + 1), d[p * 2 + 1] = b[p] * (t - m), b[p * 2] = b[p * 2 + 1] = b[p];
b[p] = 0;
}
if (l <= m) update(l, r, c, s, m, p * 2);
if (r > m) update(l, r, c, m + 1, t, p * 2 + 1);
d[p] = d[p * 2] + d[p * 2 + 1];
}
int getsum(int l, int r, int s, int t, int p){
if (l <= s && t <= r) return d[p];
int m = (s + t) / 2;
if (b[p]) {
d[p * 2] = b[p] * (m - s + 1), d[p * 2 + 1] = b[p] * (t - m), b[p * 2] = b[p * 2 + 1] = b[p];
b[p] = 0;
}
int sum = 0;
if (l <= m) sum = getsum(l, r, s, m, p * 2);
if (r > m) sum += getsum(l, r, m + 1, t, p * 2 + 1);
return sum;
}
5.编写过程中的一些优化
在叶子节点处无需下放懒惰标记,所以懒惰标记可以不下传到叶子节点。
下放懒惰标记可以写一个专门的函数
pushdown,从儿子节点更新当前节点也可以写一个专门的函数maintain(或者对称地用pushup),降低代码编写难度。标记永久化,如果确定懒惰标记不会在中途被加到溢出(即超过了该类型数据所能表示的最大范围),那么就可以将标记永久化。标记永久化可以避免下传懒惰标记,只需在进行询问时把标记的影响加到答案当中,从而降低程序常数。具体如何处理与题目特性相关,需结合题目来写。这也是树套树和可持久化数据结构中会用到的一种技巧。
三、猫树(线段树扩展)
众所周知线段树可以支持高速查询某一段区间的信息和,比如区间最大子段和,区间和,区间矩阵的连乘积等等。
但是有一个问题在于普通线段树的区间询问在某些毒瘤的眼里可能还是有些慢了。
简单来说就是线段树建树的时候需要做 O ( n ) O(n)O(n) 次合并操作,而每一次区间询问需要做 O ( log n ) O(\log{n})O(logn) 次合并操作,询问区间和这种东西的时候还可以忍受,但是当我们需要询问区间线性基这种合并复杂度高达 O ( log 2 w ) O(\log^2{w})O(log2w) 的信息的话,此时就算是做 O ( log n ) O(\log{n})O(logn) 次合并有些时候在时间上也是不可接受的。
而所谓 “猫树” 就是一种不支持修改,仅仅支持快速区间询问的一种静态线段树。
构造一棵这样的静态线段树需要 O ( n log n ) O(n\log{n})O(nlogn) 次合并操作,但是此时的查询复杂度被加速至 O ( 1 ) O(1)O(1) 次合并操作。
在处理线性基这样特殊的信息的时候甚至可以将复杂度降至 O ( n log 2 w ) O(n\log^2{w})O(nlog2w)。
原理
在查询 [ l , r ] [l,r][l,r] 这段区间的信息和的时候,将线段树树上代表 [ l , l ] [l,l][l,l] 的节点和代表 [ r , r ] [r,r][r,r] 这段区间的节点在线段树上的 lca 求出来,设这个节点 p pp 代表的区间为 [ L , R ] [L,R][L,R],我们会发现一些非常有趣的性质:
1.[ L , R ] [L,R][L,R] 这个区间一定包含 [ l , r ] [l,r][l,r]
显然,因为它既是 l ll 的祖先又是 r rr 的祖先。
2.[ l , r ] [l,r][l,r] 这个区间一定跨越 [ L , R ] [L,R][L,R] 的中点
由于 p pp 是 l ll 和 r rr 的 lca,这意味着 p pp 的左儿子是 l ll 的祖先而不是 r rr 的祖先,p pp 的右儿子是 r rr 的祖先而不是 l ll 的祖先。
因此 l ll 一定在 [ L , M I D ] [L,MID][L,MID] 这个区间内,r rr 一定在 ( M I D , R ] (MID,R](MID,R] 这个区间内。
有了这两个性质,我们就可以将询问的复杂度降至 O ( 1 ) O(1)O(1) 了。
实现
具体来讲我们建树的时候对于线段树树上的一个节点,设它代表的区间为 ( l , r ] (l,r](l,r]。
不同于传统线段树在这个节点里只保留 [ l , r ] [l,r][l,r] 的和,我们在这个节点里面额外保存 ( l , m i d ] (l,mid](l,mid] 的后缀和数组和 ( m i d , r ] (mid,r](mid,r] 的前缀和数组。
这样的话建树的复杂度为 T ( n ) = 2 T ( n / 2 ) + O ( n ) = O ( n log n ) T(n)=2T(n/2)+O(n)=O(n\log{n})T(n)=2T(n/2)+O(n)=O(nlogn) 同理空间复杂度也从原来的 O ( n ) O(n)O(n) 变成了 O ( n log n ) O(n\log{n})O(nlogn)。
下面是最关键的询问了~
如果我们询问的区间是 [ l , r ] [l,r][l,r] 那么我们把代表 [ l , l ] [l,l][l,l] 的节点和代表 [ r , r ] [r,r][r,r] 的节点的 lca 求出来,记为 p pp。
根据刚才的两个性质,l , r l,rl,r 在 p pp 所包含的区间之内并且一定跨越了 p pp 的中点。
这意味这一个非常关键的事实是我们可以使用 p pp 里面的前缀和数组和后缀和数组,将 [ l , r ] [l,r][l,r] 拆成 [ l , m i d ] + ( m i d , r ] [l,mid]+(mid,r][l,mid]+(mid,r] 从而拼出来 [ l , r ] [l,r][l,r] 这个区间。
而这个过程仅仅需要 O ( 1 ) O(1)O(1) 次合并操作!
不过我们好像忽略了点什么?
似乎求 lca 的复杂度似乎还不是 O ( 1 ) O(1)O(1),暴力求是 O ( log n ) O(\log{n})O(logn) 的,倍增法则是 O ( log log n ) O(\log{\log{n}})O(loglogn) 的,转 ST 表的代价又太大……
堆式建树
具体来将我们将这个序列补成 2 的整次幂,然后建线段树。
此时我们发现线段树上两个节点的 lca 编号,就是两个节点二进制编号的 lcp。
稍作思考即可发现发现在 x xx 和 y yy 的二进制下 lcp(x,y)=x>>log[x^y]。
所以我们预处理一个 log 数组即可轻松完成求 lca 的工作。
这样我们就完成了一个猫树。
由于建树的时候涉及到求前缀和和求后缀和,所以对于线性基这种虽然合并是 O ( log 2 w ) O(\log^2{w})O(log2w) 但是求前缀和却是 O ( n log n ) O(n\log{n})O(nlogn) 的信息,使用猫树可以将静态区间线性基从 O ( n log 2 w + m log 2 w log n ) O(n\log^2{w}+m\log^2{w}\log{n})O(nlog2w+mlog2wlogn) 优化至 O ( n log n log w + m log 2 w ) O(n\log{n}\log{w}+m\log^2{w})O(nlognlogw+mlog2w) 的复杂度。
两个节点的 lca 编号,就是两个节点二进制编号的 lcp。
稍作思考即可发现发现在 x xx 和 y yy 的二进制下 lcp(x,y)=x>>log[x^y]。
所以我们预处理一个 log 数组即可轻松完成求 lca 的工作。
这样我们就完成了一个猫树。
由于建树的时候涉及到求前缀和和求后缀和,所以对于线性基这种虽然合并是 O ( log 2 w ) O(\log^2{w})O(log2w) 但是求前缀和却是 O ( n log n ) O(n\log{n})O(nlogn) 的信息,使用猫树可以将静态区间线性基从 O ( n log 2 w + m log 2 w log n ) O(n\log^2{w}+m\log^2{w}\log{n})O(nlog2w+mlog2wlogn) 优化至 O ( n log n log w + m log 2 w ) O(n\log{n}\log{w}+m\log^2{w})O(nlognlogw+mlog2w) 的复杂度。