文章目录
写在最前
计量 数据科学 大数据 统计 软件
2018年AI及大数据处理发展速度实在太快了,我也对 大数据、机器学习、AI 、计量等内容做了些功课。也许翻译(谷歌翻译)的内容有些陈旧,但思路值得借鉴
这里面我要先提一句话大数据推动计量,计量需要大数据
文章范围真的不大好定义。先说为什么要写这个,有好事者提出:我们为什么用hadoop来分析数据,怎么不用spss或者stata,他们有什么区别。
回答:hadoop 分布式,开源(捂脸)
话说要做什么,必须先了解什么,了解->熟悉->掌握-会用。
了解:知道是什么。手机是什么能干什么
理解:不仅知道是什么,还要知其然,知其所以然,理解来龙去脉。为什么会有手机,怎么就能打电话呢。
会用:无需掌握原理,就像手机,会使用即可。
掌握:刨根问底、举一反三。不仅仅会用,还要掌握原理,可以熟练分析并应用解决问题。此处要引起重视。
哈哈哈哈,别笑!好吧,我们先了解
以下内容来源于几个链接地址的翻译整理(我仅做搬运工),非常精彩,感谢互联网
- The Popularity of Data Science Software
- Comparison of data analysis packages: R, Matlab, SciPy, Excel, SAS, SPSS, Stata
- STATISTICAL SOFTWARE
若涉及侵删,请邮件给我
值得一提的是 Robert A. Muenchen 在r4stats 上的 The Popularity of Data Science Software 真是大爱。
统计软件
几乎所有严肃的统计分析都在以下一个包中完成:R(S-PLUS),Matlab,SAS,SPSS和Stata。我对每个软件包都有专业知识,但这并不意味着每个软件包都适用于特定类型的分析。事实上,对于大多数高级领域,只有2-3个软件包是合适的,提供足够的功能或足够的工具来轻松实现此功能。例如,马尔可夫链蒙特卡罗的一个非常重要的区域仅适用于R,Matlab和SAS,除非您想依赖网络上随机用户编写的复杂宏。本页末尾的表格非常详细地比较了五个包。
R&MATLAB
R和Matlab是迄今为止最丰富的系统。它们包含令人印象深刻的插件库,每天都在增长。即使所需的特定模型不是标准功能的一部分,您也可以自己实现该模型,因为R和Matlab实际上是具有相对简单语法的编程语言。作为“语言”,它们允许您表达任何想法。问题是你是不是一个好作家。在现代应用统计工具方面,R库比Matlab更丰富。R也是免费的。另一方面,Matlab有更好的图形,你不会因为放入纸张或演示文稿而感到羞耻。
SPSS
另一方面是像SPSS这样的软件包。SPSS的功能非常狭窄,只允许您进行大约一半的主流统计。对于雄心勃勃的建模和估算程序来说,这是无用的,这些程序是内核平滑,模式识别或信号处理的一部分。尽管如此,SPSS在实践者中非常受欢迎,因为它几乎不需要任何培训。您只需点击几个按钮,SPSS就会为您完成所有计算。在那些需要标准的情况下,SPSS可能会完全实施。SPSS输出将非常详细,视觉上令人愉悦。它将包含与该方法相关的所有主要测试和诊断工具,并允许您编写实证分析的信息统计部分。简而言之,当方法存在时,它比R或Matlab中的类似功能运行得更快。所以我经常使用SPSS来满足客户的标准要求,比如线性回归,ANOVA或主成分分析。SPSS使您能够编程宏,但该功能非常不灵活。
SAS&STATA
在R,Matlab和SPSS之间的某个地方是SAS和Stata。SAS比Stata更广泛的分析。它由数十个程序组成,具有大量,大量的输出,通常覆盖十多页。SAS的想法不是那么听你的。它就像一个老祖父,你用一个简单的问题来接近他,但他告诉你他的生活故事。许多程序包含的内容比您需要知道的有关该细分的程序多三倍。所以必须花一些时间在相关输出中进行过滤。使用简单脚本调用SAS过程。可以通过单击菜单中的按钮或运行简单脚本来调用Stata过程。在菜单部分,Stata类似于SPSS。SAS和Stata都是编程语言,因此它们允许您围绕标准过程构建分析。Stata比SAS更灵活。尽管如此,就编程灵活性而言,Stata和SAS并不接近R或Matlab。与所有其他软件包相比,SAS的选择优势:大数据集,速度,漂亮的图形,格式化输出的灵活性,时间序列程序,计数过程。与所有其他软件包相比,Stata的选择优势:调查数据的操作(分层样本,聚类),稳健的估计和测试,纵向数据方法,多变量时间序列。
表
下表详细比较了五个包的标准功能。“标准”是指
1)内置的,
2)可以从官方或广为人知的可靠的公共网站上获得,或者
3)通过围绕内置功能的相对简单的编程可以实现。
如果在超过30%的典型项目中所需的编程超过10行代码,我使用标签“10+代码”
I use label "10+ code" if the required programming is more than 10 lines of code in more than 30% of typical projects.
| TYPE OF STATISTICAL ANALYSIS | R | MATLAB | SAS | STATA | SPSS |
|---|---|---|---|---|---|
| Nonparametric Tests | Yes | Yes | Yes | Yes | Yes |
| T-test | Yes | Yes | Yes | Yes | Yes |
| ANOVA & MANOVA | Yes | Yes | Yes | Yes | Yes |
| ANCOVA & MANCOVA | Yes | Yes | Yes | Yes | Yes |
| Linear Regression | Yes | Yes | Yes | Yes | Yes |
| Generalized Least Squares | Yes | Yes | Yes | Yes | Yes |
| Ridge Regression | Yes | Yes | Yes | Limited | Limited |
| Lasso | Yes | Yes | Yes | Limited | |
| Generalized Linear Models | Yes | Yes | Yes | Yes | Yes |
| Logistic Regression | Yes | Yes | Yes | Yes | Yes |
| Mixed Effects Models | Yes | Yes | Yes | Yes | Yes |
| Nonlinear Regression | Yes | Yes | Yes | Limited | Limited |
| Discriminant Analysis | Yes | Yes | Yes | Yes | Yes |
| Nearest Neighbor | Yes | Yes | Yes | Yes | |
| Naive Bayes | Yes | Yes | Limited | ||
| Factor & Principal Components Analysis | Yes | Yes | Yes | Yes | Yes |
| Canonical Correlation Analysis | Yes | Yes | Yes | Yes | Yes |
| Copula Models | Yes | Yes | Limited | ||
| Path Analysis | Yes | Yes | Yes | Yes | Yes |
| Structural Equation Modeling (Latent Factors) | Yes | 10+ code | Yes | Yes | AMOS |
| Extreme Value Theory | Yes | Yes | |||
| Variance Stabilization | Yes | Yes | |||
| Bayesian Statistics | Yes | Yes | Limited | ||
| Monte Carlo, Classic Methods | Yes | Yes | Yes | Yes | Limited |
| Markov Chain Monte Carlo | 10+ code | 10+ code | 10+ code | ||
| EM Algorithm | 10+ code | 10+ code | 10+ code | ||
| Missing Data Imputation | Yes | Yes | Yes | Yes | Yes |
| Bootstrap & Jackknife | Yes | Yes | Yes | Yes | Yes |
| Outlier Diagnostics | Yes | Yes | Yes | Yes | Yes |
| Robust Estimation | Yes | Yes | Yes | Yes | |
| Cross-Validation | Yes | Yes | Yes | Yes | |
| Longitudinal (Panel) Data | Yes | Yes | Yes | Yes | Limited |
| Survival Analysis | Yes | Yes | Yes | Yes | Yes |
| Propensity Score Matching | Yes | Yes | Limited | Yes | |
| Stratified Samples (Survey Data) | Yes | Yes | Yes | Yes | Yes |
| Experimental Design | Yes | Yes | Limited | ||
| Quality Control | Yes | Yes | Yes | Yes | Yes |
| Reliability Theory | Yes | Yes | Yes | Yes | Yes |
| Univariate Time Series | Yes | Yes | Yes | Yes | Limited |
| Multivariate Time Series | Yes | Yes | Yes | Yes | |
| Stochastic Volatility Models, Discrete Case | Yes | Yes | Yes | Yes | Limited |
| Stochastic Volatility Models, Continuous Case | Yes | Yes | Limited | Limited | |
| Diffusions | 10+ code | 10+ code | |||
| Markov Chains | 10+ code | 10+ code | |||
| Hidden Markov Models | Yes | Yes | Yes | ||
| Counting Processes | Yes | Yes | Yes | ||
| Filtering | Yes | Yes | Limited | Limited | |
| Instrumental Variables | Yes | Yes | Yes | Yes | Yes |
| Simultaneous Equations | Yes | Yes | Yes | Yes | AMOS |
| Splines | Yes | Yes | Yes | Yes | |
| Nonparametric Smoothing Methods | Yes | Yes | Yes | Yes | |
| Spatial Statistics | Yes | 10+ code | Limited | Limited | |
| Cluster Analysis | Yes | Yes | Yes | Yes | Yes |
| Neural Networks | Yes | Yes | Yes | Limited | |
| Classification & Regression Trees | Yes | Yes | Yes | Limited | |
| Boosting | Yes | Yes | Limited | ||
| Random Forests | Yes | Yes | Limited | ||
| Support Vector Machines | Yes | Yes | Yes | ||
| Signal Processing | Yes | Yes | Limited | ||
| Wavelet Analysis | Yes | Yes | Yes | ||
| Bagging | Yes | Yes | Yes | Yes | |
| Meta-analysis | Yes | 10+ code | Limited | Yes | |
| ROC Curves | Yes | Yes | Yes | Yes | Yes |
| Deterministic Optimization | Yes | Yes | Yes | Limited | |
| Stochastic Optimization | Yes | Yes | Limited |
| 计分析的类型 | [R | MATLAB | SAS | BEEN | SPSS |
|---|---|---|---|---|---|
| 非参数测试 | 是 | 是 | 是 | 是 | 是 |
| T-测试 | 是 | 是 | 是 | 是 | 是 |
| ANOVA&MANOVA | 是 | 是 | 是 | 是 | 是 |
| ANCOVA&MANCOVA | 是 | 是 | 是 | 是 | 是 |
| 线性回归 | 是 | 是 | 是 | 是 | 是 |
| 广义最小二乘法 | 是 | 是 | 是 | 是 | 是 |
| 岭回归 | 是 | 是 | 是 | 有限 | 有限 |
| 套索 | 是 | 是 | 是 | 有限 | |
| 广义线性模型 | 是 | 是 | 是 | 是 | 是 |
| Logistic回归 | 是 | 是 | 是 | 是 | 是 |
| 混合效果模型 | 是 | 是 | 是 | 是 | 是 |
| 非线性回归 | 是 | 是 | 是 | 有限 | 有限 |
| 判别分析 | 是 | 是 | 是 | 是 | 是 |
| 最近的邻居 | 是 | 是 | 是 | 是 | |
| 朴素贝叶斯 | 是 | 是 | 有限 | ||
| 因子和主成分分析 | 是 | 是 | 是 | 是 | 是 |
| 典型相关分析 | 是 | 是 | 是 | 是 | 是 |
| Copula模型 | 是 | 是 | 有限 | ||
| 路径分析 | 是 | 是 | 是 | 是 | 是 |
| 结构方程模型(潜在因子) | 是 | 10+代码 | 是 | 是 | AMOS |
| 极值理论 | 是 | 是 | |||
| 方差稳定 | 是 | 是 | |||
| 贝叶斯统计 | 是 | 是 | 有限 | ||
| 蒙特卡洛,经典方法 | 是 | 是 | 是 | 是 | 有限 |
| 马尔可夫链蒙特卡洛 | 10+代码 | 10+代码 | 10+代码 | ||
| IN算法 | 10+代码 | 10+代码 | 10+代码 | ||
| 缺少数据插补 | 是 | 是 | 是 | 是 | 是 |
| Bootstrap&Jackknife | 是 | 是 | 是 | 是 | 是 |
| 异常值诊断 | 是 | 是 | 是 | 是 | 是 |
| 稳健估计 | 是 | 是 | 是 | 是 | |
| 交叉验证 | 是 | 是 | 是 | 是 | |
| 纵向(面板)数据 | 是 | 是 | 是 | 是 | 有限 |
| 生存分析 | 是 | 是 | 是 | 是 | 是 |
| 倾向得分匹配 | 是 | 是 | 有限 | 是 | |
| 分层样本(调查数据) | 是 | 是 | 是 | 是 | 是 |
| 实验设计 | 是 | 是 | 有限 | ||
| 质量控制 | 是 | 是 | 是 | 是 | 是 |
| 可靠性理论 | 是 | 是 | 是 | 是 | 是 |
| 单变量时间序列 | 是 | 是 | 是 | 是 | 有限 |
| 多变量时间序列 | 是 | 是 | 是 | 是 | |
| 随机波动率模型,离散情形 | 是 | 是 | 是 | 是 | 有限 |
| 随机波动率模型,连续案例 | 是 | 是 | 有限 | 有限 | |
| 广播 | 10+代码 | 10+代码 | |||
| 马可夫链 | 10+代码 | 10+代码 | |||
| 隐马尔可夫模型 | 是 | 是 | 是 | ||
| 计数过程 | 是 | 是 | 是 | ||
| 过滤 | 是 | 是 | 有限 | 有限 | |
| 乐器变量 | 是 | 是 | 是 | 是 | 是 |
| 联立方程 | 是 | 是 | 是 | 是 | AMOS |
| 样条曲线 | 是 | 是 | 是 | 是 | |
| 非参数平滑方法 | 是 | 是 | 是 | 是 | |
| 空间统计 | 是 | 10+代码 | 有限 | 有限 | |
| 聚类分析 | 是 | 是 | 是 | 是 | 是 |
| 神经网络 | 是 | 是 | 是 | 有限 | |
| 分类和回归树 | 是 | 是 | 是 | 有限 | |
| 推进 | 是 | 是 | 有限 | ||
| 随机森林 | 是 | 是 | 有限 | ||
| 支持向量机 | 是 | 是 | 是 | ||
| 信号处理 | 是 | 是 | 有限 | ||
| 小波分析 | 是 | 是 | 是 | ||
| 套袋 | 是 | 是 | 是 | 是 | |
| Meta分析 | 是 | 10+代码 | 有限 | 是 | |
| ROC曲线 | 是 | 是 | 是 | 是 | 是 |
| 确定性优化 | 是 | 是 | 是 | 有限 | |
| 随机优化 | 是 | 是 | 有限 |
数据科学软件的人气对比
Robert A. Muenchen
摘要
本文以前称为“数据分析软件的受欢迎度”,通过各种方式方法来衡量市面上流行的高级分析软件软件的。此类软件也被称为数据科学,统计分析,机器学习,人工智能,预测分析,业务分析的工具,也是商业智能的子集。涵盖的软件包括:
Actuate, Alpine, Alteryx, Angoss, Apache Flink, Apache Hive, Apache Mahout, Apache MXNet, Apache Pig, Apache Spark, BMDP, C, C++ or C#, Caffe, Cognos, DataRobot, Domino Data Labs, Enterprise Miner, FICO, FORTRAN, H2O, Hadoop, Info Centricy or Xeno, Java, JMP, Julia, KNIME, Lavastorm, MATLAB, Megaputer or PolyAnalyst, Microsoft, Minitab, NCSS, Oracle Data Miner, Prognoz, Python, R, RapidMiner, Salford SPM, SAP, SAS, Scala, Spotfire, SPSS, SPSS Modeler, SQL, Stata, Statgraphics, Statistica, Systat, Tableau, Tensorflow, Teradata, Vowpal Wabbit, WEKA/Pentaho, and XGboost.
更新:最新更新是学术文章部分6/19/2017。
我在Twitter上发布了这篇文章的更新:http://twitter.com/BobMuenchen
介绍
在选择数据分析(现在更常称为分析或数据科学)工具时,需要考虑许多因素:
它是否在您的计算机上本机运行?
该软件是否提供您需要的所有方法?如果没有,如何扩展?
它的可扩展性是否使用自己独特的语言,或使用某些常用外部语言(例如Python,R)?
它是否完全支持您喜欢的样式(编程,菜单和对话框,或工作流程图)?
它的可视化选项(例如静态与交互式)是否适合您的问题?
它是否以您喜欢的形式提供输出(例如,复制粘贴到另外的文字处理与LaTeX集成)?
它能处理非常大的数据集吗?
您的同事是否使用它以便您轻松共享数据和程序?
你能负担得起吗?
有许多方法可以衡量人气或市场份额,每种方法都有其优点和缺点。按数据质量的粗略顺序,这些包括:
招聘广告
学术文章
IT研究公司报告
使用调查
写书
博客
讨论论坛活动
编程人气对比
销售和下载
比赛用途
能力增长
让我们依次检查它们中的每一个
就职机会
招聘广告
衡量数据科学软件的受欢迎程度或市场份额的最佳方法之一是计算每种软件的招聘广告数量。招聘广告信息丰富,并以资金为后盾,因此它们可能是衡量每个软件现在流行程度的最佳指标。工作趋势图让我们对未来可能变得更受欢迎的东西有了一个很好的了解。
Indeed.com是美国最大的招聘网站。正如他们的联合创始人兼前首席执行官保罗福斯特所说,Indeed.com包括“来自1000多个独特来源的所有工作,包括主要的工作委员会 - Monster,Careerbuilder,Hotjobs,Craigslist - 以及数百家报纸,协会和公司网站。“Indeed.com还具有卓越的搜索功能,它包含一个跟踪长期趋势的工具。
使用Indeed.com搜索工作很容易,但是用来跨工作来统计应用的软件是非常棘手的。某些软件仅用于数据科学(例如SPSS,Apache Spark),而其他软件更多应用于数据科学的职位,比如大量试用与报告编写的工作(例如SAS,Tableau)。通用语言(例如C,Java)在数据科学工作中被大量使用,但绝大多数使用它们的工作与数据科学无关。为了平衡竞争环境,我开发了一个 专门针对数据科学家的工作重点搜索每个软件 的协议。该协议的详细信息在另一篇文章“ 如何搜索数据科学作业”中进行了描述。本节中的所有图表都是这样查询出来的。
我在2017年2月24日收集了本节中讨论的工作计数。有人可能会认为一天的样本可能不是很稳定,但是非常大的工作职位来源使得Indeed.com的工作集中的计数趋向一致的。我最后一次收集这些数据是在2014年2月20日,那些使用相同协议(通用语言)收集的数据产生了非常相似的结果。它们的增长率在7%到11%之间,相关性为r = .94,p = .002。
图1a显示SQL占据了近18,000个工作岗位,其次是13,000个岗位的Python和Java。Hadoop接下来只有10,000多个工作岗位,然后是R,C变种和SAS。(C,C ++和C#组合在一次搜索中,因为招聘广告通常会寻找其中任何一个)。这是该报告第一次显示R比SAS 有更多的工作需求,但请记住这些是特定于数据科学的工作。如果搜索用于报告编写的岗位,您将找到近乎两倍的SAS岗位。
接下来是Apache Spark,它太新了,无法包含在2014年的报告中。它在极短的时间内走了很长的路。有关Spark的状态的详细分析,请参阅Thomas Dinsmore撰写的Spark是分析的未来。
Tableau紧随其后,约有5,000个工作岗位。2014年报告排除了Tableau,因为其工作由报告撰写主导。包括撰写报告在内,Tableau专业知识的工作数量将翻两番,超过20,000。

图1a。更受欢迎的软件(250个或更多工作,2/2017)的数据科学工作数量。
Apache Hive是下一个,大约有3,900个工作岗位,接下来是一个非常多样化的软件集,包括Scala,SAP,MATLAB和SPSS,每个软件都有超过2,500个数据科学工作。在那之后,我们看到Teradata的下降速度缓慢下降。
许多软件的工作列表少于250个。当与行业领跑者在同一图表上显示时,他们的工作计数似乎为零; 因此我在图1b中分别绘制了它们。Alteryx成为这个集团的领导者,拥有240个工作岗位。微软是一个困难的搜索,因为它出现在数据科学广告中,提到了其他微软产品,如Windows或SQL Server。为了消除这种过度统计,我通过包括Azure机器学习和Microsoft认知工具包(Cognitive Toolkit)等产品名称来区别于Microsoft。所以我很有可能从过分强调微软到只强调157个工作岗位。

图1b。不太受欢迎的软件的分析工作数量(250个工作岗位,2/2017)。
接下来是迷人的全新高性能语言Julia。我添加了FORTRAN只是为了好玩,并且惊讶地看到它在这些年后仍然悬挂在那里。Apache Flink也在这个分组中,它们都有大约125个工作岗位。
H2O紧随其后,只有100多个工作岗位。
我发现SAS Enterprise Miner,RapidMiner和KNIME出现了类似数量的工作(大约90个),这令人着迷。这三者共享一个类似的工作流程用户界面,使它们特别容易使用。这些公司宣传该软件不需要太多培训,因此如果现有员工更容易接受,公司可能不需要聘请专业知识人员。SPSS Modeler也使用这种类型的接口,但它的工作量大约是其他工作的一半,占50个工作。
这成就了Statistica,先卖给戴尔,然后卖给了Quest。它的36个工作岗位远远落后于其类似的竞争对手SPSS,后者拥有惊人的74倍工作优势。
开源MXNet深度学习框架,接下来将展示34个工作岗位。Tensorflow是一个类似的项目,具有12倍的工作优势,但这两个都足够年轻,我预计未来两者都会快速增长。
在最后一批几乎没有工作的工作中,我们看到了一些新人,如DataRobot和Domino Data Labs。其他人已经存在多年,让我们想知道在竞争激烈的情况下他们如何能够维持下去。
值得注意的是,图1a和1b中显示的值是单个时间点。更受欢迎的软件的工作数量每天都没有太大变化。因此,图1a中所示软件的相对排名在未来一年内不太可能发生太大变化。图1b中显示的不太受欢迎的包具有如此低的工作量,以至于他们的排名更有可能每月变化,尽管他们相对于主要包的位置应该保持更稳定。
每个软件都有一个总体趋势,显示多年来对工作的需求如何变化。您可以使用Indeed.com的“ 工作趋势”工具绘制这些趋势。但是,和以前一样,只关注分析工作需要仔细构建查询,并且在一次比较两个趋势时,它们都必须符合相同的查询限制。这些细节在这里描述。
我对涉及R的趋势特别感兴趣所以让我们看看它与SAS相比如何。在图1c中,我们看到SAS的数据科学工作数量从2012年到2017年2月28日仍然相对平稳,当时我制作了这个图。在同一时期,R的工作岗位稳步增长,最终在2016年初超过了SAS的工作岗位。正如博客文章(以及本报告的其他部分)所述,学术出版物中R的使用率超过了2015年的SAS。

图1c。R(蓝色)和SAS(橙色)的数据科学工作趋势。
关于Python和R的相对位置,互联网上一直存在着长期的争论。具有讽刺意味的是,关于数据科学软件的争论很少涉及实际数据。但是,现在至少可以研究工作趋势。图1a向我们展示了Python在R之前很好,至少在搜索运行的那一天。随着时间的推移,数据看起来像什么?答案如图1d所示。

图1d。R(蓝色和低级)和Python(橙色和上层)的工作趋势。
正如我们所看到的,Python在2013年的数据科学工作方面超过了R.当然,这些语言非常不同,快速扫描工作描述将表明R工作更侧重于使用现有的分析,而Python工作有更多的自定义编程角度。
学术文章
学术文章提供了有关数据科学工具的丰富信息来源。他们的创建需要大量的努力,远远超过回应工具使用情况调查所需的努力。软件包越流行,它就越有可能作为分析工具,甚至是研究对象出现在学术出版物中。
由于研究生在这些文章中进行了大部分分析,所使用的软件可以成为事物发展方向的主要指标。Google学术搜索提供了衡量此类活动的方法。然而,没有这种规模的搜索是完美的; 每个都将包括一些不相关的文章,并拒绝一些相关的文章。通过简明的工作要求(参见上一节)搜索比搜索学术文章更容易; 但是,只有具有高级分析能力的软件才能使用这种方法进行研究。我使用的搜索术语的详细信息非常复杂,可以转到配套文章“ 如何搜索数据科学文章”。由于Google会定期改进其搜索算法,因此我每年都会重新收集前几年的数据。
图2a显示了2016年最新一年中更受欢迎的软件包(至少有750篇文章)的文章数量。为了有足够的时间进行发布,插入在线数据库和编制索引,收集了数据在2017年6月8日。
SPSS是迄今为止最具统治力的一揽子计划,已有超过15年的历史。这可能是由于它在功率和易用性之间的平衡。R排在第二位,约有一半的文章。SAS排在第三位,仍然保持着领先于Stata,MATLAB和GraphPad Prism的巨大优势,这几乎是并列的。这是我跟踪Prism的第一年,这是一个强调图形但也包括统计分析功能的软件包。它在医学研究界特别受欢迎,因为它易于使用。但是,在这种普及程度上,它提供的分析方法远远少于其他软件。
请注意,通用语言:C,C ++,C#,FORTRAN,MATLAB,Java和Python仅在与数据科学术语结合使用时才包含在内,因此请将这些计数视为近似值,而不是其他语言。

图2a。在最近的完整年份(2016年)中发现的更受欢迎的数据科学软件的学术文章数量。要包括在内,必须在至少750篇学术文章中使用软件。
下一组软件包从Apache Hadoop到Python,Statistica,Java和Minitab,随着它们的发展逐渐下降。
Systat和JMP都是已经上市多年的套装,但从未进入过“大联盟”。
从C到KNIME,计数似乎接近于零,但请记住,每个计数至少使用750篇期刊文章。然而,与使用SPSS的86,500相比,它们只是昙花一现。
图2a的底部是两个类似的软件包,开源Caffe和谷歌的Tensorflow。这两个侧重于“深度学习”算法,这个领域相当新(至少是术语)并且发展迅速。
图2a中的最后两个包是RapidMiner和KNIME。看过去几年他们之间的竞争是非常有趣的。它们都是工作流驱动的工具,具有非常相似的功能。IT咨询公司Gartner和Forester将它们评为能够对抗商业巨头SPSS和SAS的工具。鉴于SPSS在学术界的使用率约为75倍,这似乎相当长。然而,正如我们将很快看到的,这些新手的使用正在增长,而旧包装的使用正在迅速缩小。尽管KNIME拥有更多的开源模型,但该图显示RapidMiner的使用率几乎是KNIME的两倍。
图2b显示了2016年少于750篇文章中使用的软件的结果。这种规模的变化为“条形”的扩展留出了空间,让我们可以更有效地进行比较。该图包含一些相当新的软件,其使用率低但增长迅速,如Alteryx,Azure机器学习,H2O,Apache MXNet,亚马逊机器学习,Scala和Julia。它还包含一些软件,这些软件要么已经从一次性优势中衰退,例如BMDP,要么在底层停滞不前,例如Lavastorm,Megaputer,NCSS,SAS Enterprise Miner和SPSS Modeler。

图2b。不太流行的数据科学的学术文章数量(2016年少于750篇学术文章使用的数据)。
虽然图2a和2b对于研究现在的市场份额很有用,但它们并没有显示出事态的变化。为每个分析包提供长期增长趋势图是理想的,但每年收集这么多数据太费时间了。我所做的只是收集过去两年,即2015年和2016年的数据。这提供了研究逐年变化所需的数据。
图2c显示了那些年份的百分比变化,其中使用的“热”包显示为红色(右侧);使用率下降或“冷却”的那些显示为蓝色(左侧)。由于文章的数量往往达到数千或数万,我已经删除了2015年少于500篇文章的软件。从1篇文章到5篇的软件包可能会显示500%的增长,但仍然很少利益。

图2c。在最近两个完整年度(2015年至2016年)中使用每种软件的学术文章数量的变化。以红色上增、蓝色下降趋势。
Caffe是数据科学工具,增长最快,略高于150%。这反映了过去几年深度学习模式使用的快速增长。类似的产品Apache MXNet和H2O也迅速增长,但它们分别只有12和31篇文章,所以没有显示。
IBM Watson增长了91%,这令我感到意外,因为我不太清楚它的作用或它是如何做到的,尽管已经阅读了IBM的几个描述。但它在Jeopardy真棒!
虽然R的增长仅为“仅仅”14.7%,但它已经被广泛使用,这一百分比转化为非常可观的5,300篇额外文章。
在RapidMiner vs. KNIME比赛中,我们之前看到RapidMiner领先。从这个情节我们也看到它继续从KNIME开始快速增长。
从Minitab开始,该软件正在失去市场份额,至少在学术界是这样。C和Java的变体可能会同时失去一些来自几种不同类型软件的竞争。
在过去的几年里,Statsa被Statsoft卖给戴尔,然后是Quest Software,然后是Francisco Partners,然后是Tibco!它的使用量下降是否推动了这些销售?音乐椅游戏是否吓跑了潜在用户?如果您有意见,请在下面发表评论或发送电子邮件给我。
最大的输家是SPSS和SAS,两者的使用率下降了25%或更多。回想一下,图2a显示尽管近年来有所下降,但SPSS仍然在学术上占据主导地位。
我对经典统计软件包的长期趋势特别感兴趣。因此,在图2d中,我绘制了1995年到2016年相同的学术用途数据。

图2d。Google学术搜索每年发现的学术文章数量。仅显示前六个“经典”统计包。
如图2a所示,SPSS总体上具有明显的领先优势,但现在您可以看到它的主导地位在2009年达到顶峰并且其使用率急剧下降。SAS从未接近SPSS的主导地位,其使用率在2010年左右达到顶峰.IraphPAD Prism遵循类似的模式,尽管它在2013年左右达到顶峰。
请注意,使用SPSS,SAS或Prism的文章数量的下降并未通过此特定图表中显示的其他软件的增加来平衡。即使将图2a和2b中所示的所有其他软件相加,也不能解释整体下降的情况。但是,我只关注100多种数据科学工具中的46种。SQL和Microsoft Excel可能会占用一些空间,但是将Google Scholar的搜索重点放在那些专门用于数据分析的文章中是非常困难的。
由于SAS和SPSS在图2d中的垂直空间占据如此大的空间,我删除了这两条曲线,在2015年和2016年只留下了两个SAS使用点。结果如图2e所示。

图2e。删除了SPSS和SAS曲线后,Google Scholar每年在经典统计数据包中找到的学术文章数量。
在画布中释放出如此多的空间让我们看到R的使用增长非常迅速并且正在逐渐消失。如果目前的趋势继续下去,R将在2018年末超过SPSS成为排名第一的软件学术性语言,由于谷歌的搜索算法的变化,趋势线的相关讨论请参阅这里。幸运的是,这一情节的整体趋势多年来保持相当稳定。
Stata使用的快速增长似乎终于放缓了。2016年,Minitab的增长也似乎停滞不前,Systat也是如此。JMP似乎在2015年有所下降,并且正在从中恢复。
这些结果一般适用于学术文章。特定领域或期刊的结果很可能不同。Denis Haine为流行病学期刊应用了提取的类似数据,甚至在类似的帖子中专注于贝叶斯算法的软件。
IT研究厂商
IT研究厂商研究软件产品和公司战略,他们调查客户对产品和服务的满意度,然后对他们向客户销售的报告中的每一个进行分析。每个研究公司都有自己的评级公司标准,因此他们并不总是同意。但是,我发现这些报告包含非常有趣的阅读的详细分析。虽然这些报告侧重于公司,但它们通常还描述了他们的商业工具如何集成开源工具,如R,Python,H2O,TensoFlow等。
虽然这些报告很昂贵,但获得良好评级的公司通常会购买副本以赠送给潜在客户。对报告标题的互联网搜索通常会显示正在分发此类免费副本的公司。
Gartner,Inc。是提供此类报告的公司之一。在大约100家销售数据科学软件的公司中,Gartner选择了16家具有高收入或低收入以及高增长的公司(详见完整报告)。经过客户和公司代表的广泛投入,Gartner分析师对这些公司的“视觉完整性”及其“执行能力”的愿景进行了评级。此后,我将这些视为视觉和能力。图3a显示了2018年的“魔力象限”图,3b显示了上一年的情节。
在领导者象限是谁在与他们的客户的需求和资源来执行这一愿景线有一个未来发展方向的公司的地方。右上角越远,合并得分越高。KNIME处于主要地位,H2O.ai表现出更强的视野,但执行能力更低。今年KNIME获得了运行H2O.ai算法的能力,所以这两者可能被视为补充工具而不是直接竞争对手。
Alteryx和SAS的综合得分几乎相同,但请注意Gartner只研究了SAS Enterprise Miner和SAS Visual Analytics。后者包括可视统计,可视化数据挖掘和机器学习。由于Gartner专注于集成的工具,因此排除了SAS系统本身。缺乏整合可能解释SAS从去年开始的视力下降。
KNIME和RapidMiner是非常相似的工具,因为它们都是由易于使用和可重复的工作流程界面驱动的。两者都提供免费和开源版本,但公司在开源概念的承诺方面存在很大差异。KNIME的桌面版本是免费和开源的,该公司表示它将永远如此。另一方面,RapidMiner受限于它可以分析的数据量上限(10,000个案例),并且当它们添加新功能时,它们通常只能通过商业许可证来获得。在前一年的魔力象限中,RapidMiner略微领先,但现在KNIME处于领先地位。
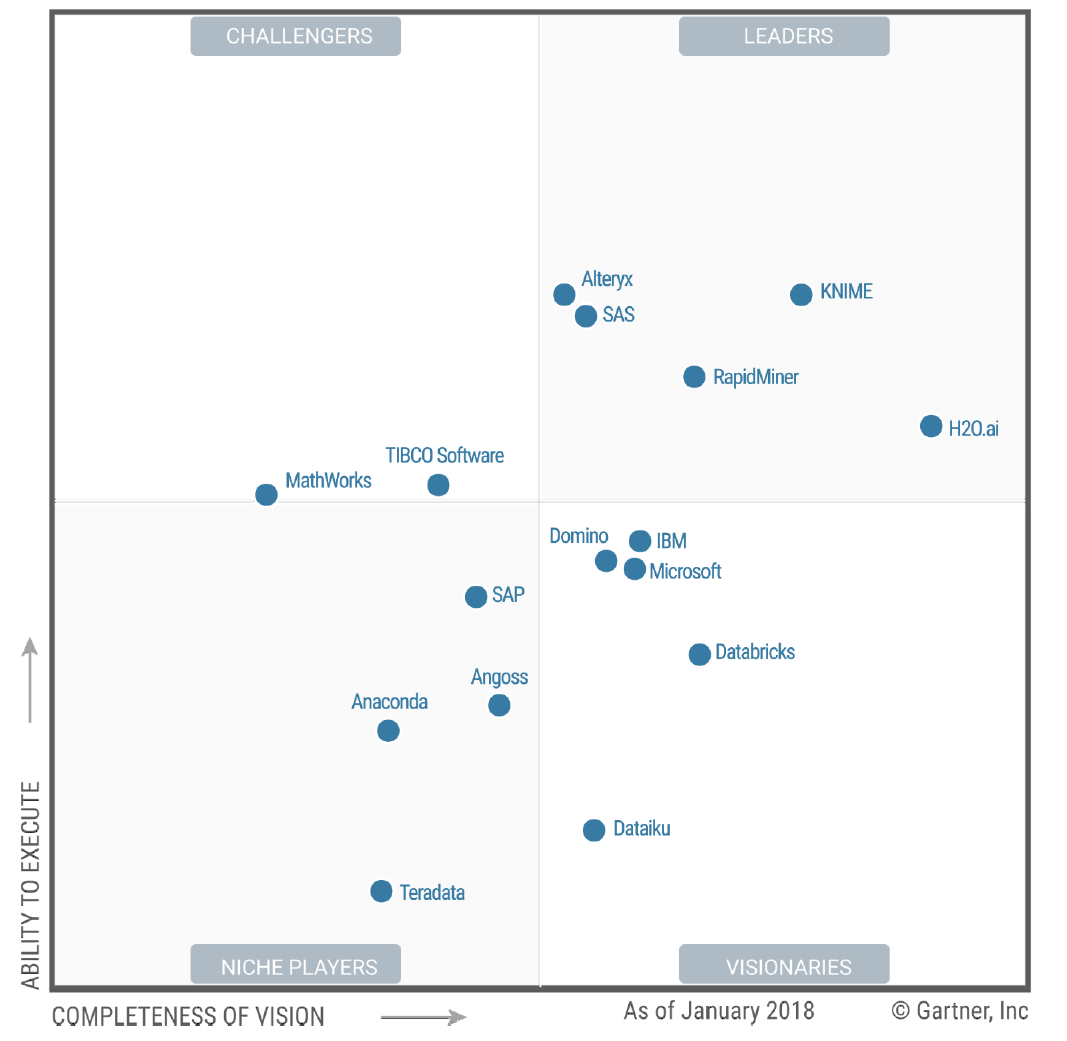
图3a。Gartner数据科学和机器学习平台的魔力象限

图3b。Gartner 2017年数据科学平台魔力象限。
潜力Visionaries Quadrant中的公司是具有良好未来计划但可能没有资源来执行该愿景的公司。其中,IBM在领导者象限中连续几年登陆后遭受重创。现在,他们与微软和Domino密切相关。Domino从该象限的底部向顶部增长。他们将许多不同的开源和商业软件(例如SAS,MATLAB)集成到他们的Domino数据科学平台中。Databricks和Dataiku提供类似于Domino的基于云的分析,但缺乏对商业工具的访问。
那些在挑战者象限Challenger’s Quadrant有充足的资源,但客户对于他们的未来计划、远见并不是很有信心。作为MATLAB的制造商,Mathworks继续使用其专有工具“坚持到底”,而大多数竞争对手提供了更好的集成到不断扩展的开源工具领域。由于购买了Statistica,Tibco取代了这个象限中的Quest。无论数据科学的最火的排名变成什么样?Statistica四年内由四家公司所有!(Statsoft,Dell,Quest,Tibco)该软件的用户必须考虑其他选择。Tibco也在2017年购买了Alpine Data,看到从图3b到3a消失了。
**Niche Players **象限的成员提供的工具不是广泛适用的。Anaconda是今年与Gartner合作。它为Python提供了深入的支持。SAP有一个工具链,Gartner称之为“支离破碎和含糊不清。”Angoss最近被Datawatch收购。Gartner指出,经过20年的经营,Angoss只有300名忠实客户。随着数据科学领域的激烈竞争,人们不禁怀疑他们将会有多长时间。说到死亡数据,曾经是大数据之王,Teradata受到来自Hadoop和Spark等开源工具的竞争的打击。Teradata的净收入在2008年高于今天。
截至2014年2月26日,RapidMiner正在此处发布 Gartner报告的副本。有关详细信息,请参阅Thomas Dinsmore 的原始报告和此分析。
Forrester Research,Inc。是另一家提供此类报告的公司。2017年报告“ Forrester Wave:Predictive Analytics and Machine Learning Solutions”的结论总结在图3c中。在x轴上,它们列出了每个公司战略的强度,而y轴则衡量了当前产品的强度。每个数据点周围的圆圈的大小和阴影表示市场中每个供应商的强度(70%的供应商规模,30%的ISV和服务合作伙伴)。
与上面讨论的Gartner 2017报告(不是Gartner最新的2018年报告)一样,IBM,SAS,KNIME和RapidMiner被视为领导者。但是,Forrester看到了这一类别中的更多公司:Angoss,FICO和SAP。这与Gartner的分析完全不同,后者将Angoss和SAP置于中间位置,而FICO被认为是一个利基市场。

图3c。Forrester Wave预测分析和机器学习软件的图。
在他们的强劲表现者类别中,他们拥有H2O.ai,Microsoft,Statistica,Alpine Data,Dataiku,以及几乎没有Domino Data Labs。Gartner对Dataiku的评价相当高,但他们普遍同意其他人。唯一的例外是Gartner在2017年放弃了对Alpine Data的报道。最后,Salford Systems进入了竞争者部分。索尔福德最近被Minitab收购,该公司之前从未被Gartner或Forrester评为过,因为他们专注于统计数据包,而不像大多数其他统计数据包那样扩展到机器学习或人工智能工具(另一个值得注意的例外:Stata )。看看未来的报告如何涵盖它们将会很有趣。
与去年的Forrester报告相比,KNIME从几乎没有成为领先者的强势表现中崛起。RapidMiner和FICO从强势表演者群体的中间开始加入领导者行列。唯一的另一个主要举措是Statistica的横向调整,其战略评分下降,而当前发行的评分上升(去年Statistica属于戴尔,今年它是Quest Software的一部分。)
RapidMiner的“市场存在”圈子的大小表明,Forrester认为其在市场中的地位与IBM和SAS一样强大。我发现这个视角确实很有意义!
有关Forrester 2017年报告的详细分析,请参阅Thomas Dinsmore的博客。
Alteryx,Oracle和Predixion都从今年的Forrester报告中删除。他们提到Alteryx和Oracle具有“嵌入其他工具的功能”,这意味着这不是本报告的重点。没有提到Predixion被放弃的原因,但考虑到Gartner在2017年也放弃了覆盖率,这对公司来说并不是好兆头。
使用调查
调查数据增加了有关软件流行度的附加信息,但它们通常使用“雪球采样 snowball sampling”来完成,其中调查提供者试图广泛分发链接,然后供应商争相查看谁可以让他们的大多数用户参与。只要它们都以相同的效果这样做,结果就会很有用。但是,信息通常是有限的,因为问题简短而精确(例如“数据挖掘工具”或“数据挖掘程序语言”)和响应只需点击几下鼠标,而不是放置工作所需的承诺广告或发布学术文章,书籍或博客文章。因此,一年内市场份额增长100%或下降50%并不罕见,这很可能不会反映实际使用的变化。
Rexer Analytics每隔一年对数据科学家进行一次调查,询问有关数据科学的各种问题(以前称为调查本身的数据挖掘)。图4a显示了1,220名受访者在2015年使用的工具。

图4a。受访者对2015 Rexer Analytics Survey使用的分析工具。在这种观点中,每个受访者都可以自由检查多种工具。
我们看到R在下一个最受欢迎的软件包SPSS Statistics和SAS上的领先优势超过2比1。微软的Excel数据挖掘软件略显不受欢迎,但请注意,它很少用作主要工具。接下来是Tableau,也很少用作主要工具。这是可以预料的,因为Tableau主要是一种可视化工具,具有最低级别的高级分析功能。
下一批软件首先出现在15%到20%的范围内,但是KNIME和RapidMiner都列在他们的免费版本中,更进一步的是商业版本。这些数据来自“检查所有适用的”类型的问题,因此如果我们添加这两个数额,我们可能会过度计算。然而,该调查还询问,“ 在过去一年中,您最常使用的是哪一个(我的重点)数据挖掘/分析软件包?”使用这些数据,我将免费版和商业版组合在一起,并再次绘制了前10个软件包。图4b。由于可能存在其他软件组合,例如SAS和Enterprise Miner; SPSS Statistics和SPSS Modeler; 我也结合了其他几个。

图4b。2015年将每个包作为主要工具进行检查的受访者百分比。请注意,KNIME和RapidMiner的免费和商业版本相结合。同一公司的多个工具也合并在一起。仅显示前10名。
在这种观点中,我们看到R甚至更具优势,与IBM SPSS和SAS Institute的软件相比具有3比1的优势。但是,前三名的整体排名没有变化。然而,KNIME从第9位升至第4位。RapidMiner也从第10位上升到第6位。尽管这两个软件包具有相似的功能并且都使用工作流用户界面,但KNIME与RapidMiner的关系大约为2比1。这可能是由于RapidMiner转向更加商业化的许可方法。对于免费,您仍然可以获得较旧版本的RapidMiner或最新版本的版本,这是非常有限的在它可以读取的数据文件类型中。甚至RapidMiner的学术许可也受到公司认为“资助活动”(例如政府拨款研究)与商业工作相同的事实的限制。KNIME许可证更加慷慨,因为该公司通过附加组件赚钱,提高生产力,协作和性能,而不是限制分析功能或访问流行的数据格式。(译者按:这个目标写的好!!)
2015年5月KDnuggets.com网站进行的类似民意调查的结果如图4c所示。这个显示R位居第一,46.9%的用户报告将其用于“真实项目”.FreeMiner,SQL和Python的使用率相当低,约为30%。然后大约20%是Excel,KNIME和HADOOP。有趣的是,这些调查结果与前一个调整结果相反,显示RapidMiner比KNIME更受欢迎。两者仍然是非编程而是“点击式”类型包。

图4c。在KDnuggets 2015年民意调查中使用每种软件的受访者百分比。仅显示具有5%市场份额的软件。单独的百分比是仅使用该工具的工具选民的百分比。例如,只有3.6%的R用户仅使用R,而13.7%的RapidMiner用户表示他们仅使用该工具。年份采用颜色编码,2015年,2014年,2013年从上到下。
O’Reilly Media进行年度数据科学薪酬调查,该调查还询问有关分析工具的问题。虽然完整的结果报告正如他们的报告所指出的那样,“O’Reilly内容 - 书籍,在线和会议 - 专注于技术,特别是新技术,因此我们的受众倾向于成为早期采用者一些较新的工具。“超过600名”受访者的结果显示在图6d和6e中。

图4d。2015年受访者对O’Reilly 2015薪资调查使用的工具。这些受众中较不受欢迎的工具如下图所示。

图4e。O’Reilly 2015年薪资调查的受访者使用的不太受欢迎的工具。
O’Reilly的结果将SQL放在第一位,70%的用户报告它,紧接着是Excel。Python和R似乎并列第三,占55%。然而,Python也出现在第六位,其子程序库numpy等,R的流行ggplot包出现在第7位,市场份额约为38%。第一个具有深入分析能力的商业软件包是SAS排名第23位!这强调了O’Reilly的样本非常重视他们通常的开源受众。希望将来他们会将调查广告给广大受众,并且不仅仅是薪水调查。工具调查获得额外的受访者,因为他们被各种工具的倡导者(供应商,粉丝等)做广告。
Lavastorm,Inc。对分析社区进行了调查,包括LinkedIn的Lavastorm Analytics社区组,Data Science Central和KDnuggets。结果发布于2013年3月,其受访者的“自助分析工具”使用条形图如图6f所示。Excel作为顶级工具出现,75.6%的受访者报告其使用情况。
R成为最先进的分析工具,占35.3%的受访者,紧随其后的是SAS。MS Access在第四位的位置有点异常,因为没有其他调查包括它。Lavastorm出现了3.4%,而其他调查根本没有显示出来。这项调查针对Lavastorm的LinkedIn社区小组,这并不令人惊讶。

图4f。Lavastorm对分析工具的调查。
图书
在其标题中包含软件名称的书籍数量是一个特别有用的信息,因为它需要花费大量精力来编写一个,出版商在承担出版风险之前自己研究市场份额。但是,搜索可能很难找到使用通用语言的书籍,而这些书籍也只关注分析。Amazon.com提供了一种高级搜索方法,适用于除R和Java,C和MATLAB等通用语言之外的所有软件。我没有找到一种方法来轻松搜索使用此类通用语言的分析书籍,因此我在本节中将其排除在外。
我使用的Amazon.com高级搜索配置是(以SAS为例):
标题:SAS -excerpt -chapter -changes -articles
主题:计算机与技术
条件:新的
格式:所有格式
出版日期:2000年1月以后
“title”参数允许我将搜索重点放在其标题中包含软件名称的书籍上。其他书籍可能在其示例中使用特定软件,但它们无法轻松搜索。SAS有许多手册可供出售,作为单独的章节或摘录。它们在标题中包含“章节”或“摘录”,因此我使用减号将其排除在外,例如“-excerpt”.SAS还有简短的“更改和增强”小册子,其他软件包的开发人员仅以传单的形式发布和/或网页,所以我也排除了“变化”。一些软件列出了我也排除的简短“文章”。我在2015年6月1日进行了搜索,并且我排除了所有的摘录,章节,变更和文章搜索。
“R”是一个难以搜索的术语,因为它在书籍标题中用于表示“SAS(R)”中的注册商标。因此,我手动验证了所有R书。
结果显示在下面的表格中,很明显,极少数的分析软件包主导着图书出版领域。SAS拥有576个标题,其次是SPSS,339个,R和240个.SAS和SPSS都有相同书籍或手册的许多版本仍在销售中,因此他们的数字都被夸大了。JMP和Hadoop的R计数都不到一半,然后Minitab和Enterprise Miner的数量再少一半。虽然我获得了图2a中显示的所有27个特定领域(即非通用)分析软件包或语言的计数,但我在具有8个或更少书籍的软件中删除了表格,以节省空间。
软件书籍数量
SAS 576
SPSS Statistics 339
R 240 [更正自博文:172]
JMP 97
Hadoop 89
Stata 62
Minitab 33
企业矿工(Enterprise Miner )32
表1.标题包含每个软件包名称的书籍数量。
博客
在互联网博客上,人们会写下他们感兴趣的软件,展示如何解决问题和解释现场事件。博客帖子包含大量有关其主题的信息,虽然它不像书籍那样耗费时间,但维护博客肯定需要付出努力。因此,撰写有关分析软件的博主的数量有可能作为受欢迎程度或市场份额的衡量标准。不幸的是,计算相关的数量博客通常是一项艰巨的任务。诸如Java,Python,C语言变体和MATLAB之类的通用软件有更多的博客写作关于通用编程主题而不仅仅是分析。但将它们分开并不容易。博客的名称和最新帖子的标题可能无法让您知道它通常包含有关分析的文章。
另一个问题来自于一些公司将其作为简报写出来的事实,其他公司将作为一组博客来做,其中公司中的几个人各自贡献他们自己的博客。这些个人博客也可能合并成一个公司博客,进一步夸大计数。Statsoft和Minitab提供了这方面的示例。所以真正有趣的不是被指派写博客的公司员工,而是那些由外部志愿者撰写的员工。在一些幸运的情况下,这些博客的列表通常由博客整合者维护,博客整合者将许多博客组合成一个大的“代数日志”。我所要做的就是找到这样的列表并计算博客。我不会尝试提取我认识的混合到这些列表中的少数供应商员工。我只跳过那些完全基于员工(或非常接近它)的列表。
数
博客软件来源
R 550 R-Bloggers.com
Python 60 SciPy.org
SAS 40 PROC-X.com,sasCommunity.org Planet
Stata 11 Stata-Bloggers.com
表2. 2014年4月7日专用于每个软件包的博客数量以及
数据来源。
R的550个博客数字令人印象深刻。对于Python,我只能找到专门用于SciPy子例程库的60个列表。其中一些可能涵盖除分析之外的主题,但确定哪些从未涵盖该主题将是非常耗时的。关于SAS的40个博客仍然是一个令人印象深刻的数字,因为Stata是唯一一个甚至在任何地方获得名单的公司。该列表位于供应商本身,Statacorp,但它由非员工组成,除了一个。
在搜索其他软件上的博客列表时,我确实找到了至少偶尔涵盖特定主题的个人博客。然而,考虑到收集其他受欢迎度量的相对容易性,将该列表保持最新是非常耗时的。
如果您知道其他相关博客列表,请告诉我,我会添加它们。如果您是软件供应商员工,并且您的公司没有构建代数日志或者至少维护一个博客列表,我建议您利用这一重要的免费宣传来源。
论坛活动
衡量软件受欢迎程度的另一种方法是查看有多少人互相帮助使用每种软件包或语言。虽然这些数据很容易获得,但它也存在问题。像SPSS这样的菜单驱动软件或KNIME等工作流程驱动的软件非常易于使用,并且往往产生的问题更少。通过编程控制的软件需要记忆许多命令并需要更多支持。即使在语言中,有些比其他语言更难使用,产生更多问题(参见为什么R难以学习)。
这类数据的另一个问题是,有很多地方可以提问,每个地方都有自己的重点。有些人对经典统计学观点感兴趣,而另一些人则将软件视为通用编程语言。近年来,公司在其主要企业网站内设立了支持站点,进一步分散了您可以去寻求帮助的地方。此类网站的使用数据不易获得。
另一个问题是,使用逻辑来关注特定类型的问题并不像使用之前讨论的招聘广告和学术文章中的数据那样容易。跨时间获取数据也不容易让我们研究趋势。最后,此类网站所测量的内容包括:软件组成员(也称为粉丝),个别主题(又名问题或主题)以及所有主题(即总帖子)的总评论。这使得跨站点的组合计数成为问题。
用于讨论软件的两个最大的网站是LinkedIn和Quora。它们都显示了跟踪每个软件主题的人数,因此将它们的数字结合起来是有道理的。但是,由于这些网站缺乏对分析的关注,我没有收集他们的数据,如Java,MATLAB,Python或C的变体等通用语言。2015年10月17日收集的数据结果如下所示:

图7a。在LinkedIn和Quara上关注每个软件的人数。
我们看到R是主导软件,通过SAS,SPSS和Stata向下移动导致每步中大约一半的人流失。Lavastorm跟随Stata,但我觉得奇怪的是,在Quora上对Lavastorm的讨论绝对没有。您可以在此剧情中看到的最后一个栏目是62人关注Minitab。下面的所有人都只有不到10人的小观众。
接下来让我们检查两个仅关注统计问题的站点:Talk Stats和Cross Validated。他们都报告了给定软件的问题数量(又称线程),允许我总计他们的计数:

图7b。Talk Stats和Cross Validated上的每个软件的问题数量和问题。那些没有显示的人没有问题。
我们看到R在下一个最受欢迎的软件包SPSS上领先4比1。Stata排在第3位,随后是SAS。SAS在这里排在第四位的事实可能是因为它在数据管理和报告编写方面很强大,这不是这两个网站关注的问题类型。尽管MATLAB和Python是通用语言,但我将它们包含在此处,因为此站点上的问题属于分析领域。请注意,我在上一个图表中显示的包中收集了数据,但未显示的数据包计数为零。由于图表的规模,Julia似乎计数为零,但实际上在Cross Validated上有5个问题。
编程人气度量
一些网站对编程语言的普及程度进行排名。不幸的是,他们没有区分通用语言和用于分析的特定于应用程序的语言。但是,很容易从他们的结果中选择一些分析语言。
这些网站中最全面的是IEEE频谱排名。该网站结合了10个不同网站的12个指标。这些包括上面讨论的一些措施,例如在工作地点和搜索引擎上的流行度。它们还包括引人入胜且有用的措施,例如去年在流行的GitHub存储库中添加了多少新的编程代码。该图显示了2015年的十大语言:

图8a。IEEE Spectrum语言的人气排名。左栏(橙色)显示2015年排名,而左侧(黄色)显示2014年排名。
我们看到R排在第6位,并且从2014年的第9位增加。未显示在这里是第26位的SAS。Python排在第四位,但这用于所有目的,而R的使用更侧重于分析。没有其他特定于分析的语言可以在其排名中使用它。此排名基于加权综合得分,网站是互动的,允许您生成更适合您需求的排名。
下一个最全面的分析由RedMonk提供。他们的分析简单而客观。它们绘制了使用流行的Github存储库中每种语言编写的代码行数与讨论论坛StackOverflow.com上标记的注释数量。结果如下:

图8b。RedMonkpProgramming语言流行度,通过GitHub上的项目数量和StackOverflow上的讨论量来衡量。
从右上角向下左下方移动,我们可以看到Redmonk的方法将R显示为一种非常流行的语言,大约在第12位。虽然Python,MATLAB和Julia的大量指标可能是由于分析的使用,但我们无法知道多少。
在TIOBE编程社区指数也汇总排行了流程的编程语言。它从25个最受欢迎的搜索引擎中提取测量结果,包括Google,YouTube,Wikipedia,Amazon.com,并将它们组合成一个索引。在2015年10月的排名中,他们将R排在第20位,SAS排在第23位。Stata是一种捆绑,他们称之为“接下来的50种”语言,它们在通用语言中的流行程度如此稀少,以至于它们的相对排名太不稳定而无法给予个人排名。SPSS是他们监控的语言,但它没有进入前100名。这使我们对Tiobe索引有一个重要的限制:它搜索一个单独的字符串:“X编程。”所以如果它没有找到“SPSS编程”然后它不算数。我用于工作和学术文章的复杂搜索在估计每个包的受欢迎程度方面更有用。Tiobe指数的另一个限制是它现在测量互联网上的内容,因此它是一个滞后指标。没有购买他们的数据就无法绘制趋势,这非常昂贵。
一个非常相似的流行度指数是编程语言的PYPL PopularitY。它只跟踪前15种语言,并在2015年10月将R排在第11位。它搜索单个字符串“X教程”,使其成为未来可能更受欢迎的领先指标。
该透明的语言人气指数非常相似,TIOBE指数与不同之处在于它的排名的软件,算法和数据公布给大家看。截至2013年7月,该指数的工作已停止。
销售和下载
一些商业供应商报告的销售数据包括与分析无关的产品。许多供应商不会发布销售数据,或者他们以结合了许多不同产品的形式发布它们,这使得对特定产品的检查变得不可能。对于像R这样的开源软件,您可以计算下载量,但是一个迷茫的人可以下载许多副本,从而使总数膨胀。相反,许多人可以在服务器上使用单个下载,从而缩小它。
基于R的Bioconductor项目的下载计数位于此处。下载Stata附加组件(不是Stata本身)的类似数据可在此处获得。此处提供了Stata存储库列表。存储库和个人网站上的许多下载源使计数下载成为一项非常困难的任务。
比赛用途
Kaggle.com是一个赞助数据科学竞赛的网站。人们在那里发布问题,他们愿意向最能解决问题的人或团队支付金额。金钱和竞争对手的声誉都在线上,因此有充分的动力使用最好的工具。图9比较了处理这些问题的数据科学家所选择的前两个工具的使用情况。从2015年4月到2016年7月,我们看到R和Python的使用量以相似的速度增长。在最近的时间点,Python略微领先。这里有更多细节。

图9. 2015年和2016年Kaggle.com数据科学竞赛中使用的软件。
能力增长
多年来,分析软件的功能显着增长。能够绘制每个软件包功能的增长是有帮助的,但这些数据很难获得。]John Fox(2009)](https://www.jstatsoft.org/article/view/v073i02/v73i02.pdf)为R的每个版本的R 主要发行网站 http://cran.r-project.org/ 购买了它们。为了简化正在进行的数据收集,我只保留了每年发布的R的最新版本的值(通常在11月或12月),并通过最近一整年收集数据。
这些数据显示在图10中。最右边的点是版本3.2.3,发布于12/10/2015。生长曲线遵循快速抛物线弧(二次拟合,R平方= .995)。

图10.每年发布的最新版本的主要分发站点上可用的R包数。
为了实现这一惊人的增长,让我们将其与最主要的商业软件包SAS进行比较。在版本9.3中,SAS包含大约1,200个命令,这些命令大致相当于R函数(基础,统计,ETS,HP预测,图形,IML,宏,OR和QC中的过程,函数等)。在2015年,R增加了1,357个包,仅计算CRAN,或约27,642个功能。仅在2015年,R就增加了比SAS Institute 在其整个历史中所写的功能/过程更多的功能/过程。
当然,虽然SAS和R命令解决了许多相同的问题,但它们肯定不完全等同。有些SAS程序比R函数有更多选项来控制它们的输出,因此一个SAS程序可能等同于许多R函数。另一方面,R函数可以相互嵌套,创建几乎无限的组合。SAS现在已经推出了版本9.4,我没有重复重述其命令的艰巨任务。如果SAS Institute会提供这个数字,我会把它包含在这里。虽然这种比较远非完美,但它确实提供了有关R的大小和增长率的有趣观点。
与R的增长一样快,这些数据仅代表主要的CRAN存储库。R还有其他八个软件存储库,如Bioconductor,未包含在图10中。2016年4月19日运行的程序在所有主要存储库中计算了11,531个R包,其中8,239个在CRAN。(我排除了GitHub存储库,因为它包含了我无法轻易删除的CRAN副本。)因此,所有存储库中软件的增长曲线在y轴上比图10中所示的增长曲线高约40%。
与任何分析软件一样,个人也可以在其网站上保留自己的独立馆藏。但是,这些都不容易计算。
R功能的总数是多少?该Rdocumentation网站显示了CRAN,Bioconductor的和GitHub的两个包和功能的最新计数。它们表明每个包平均有19.78个函数。鉴于包裹数量为11,531,截至2016年4月19日,R中的总功能大约为228,103个。总的来说,R的命令大约是其主要商业竞争对手SAS的190倍。
少了什么东西?
我之前添加了Google趋势图表。该网站不会通过搜索跟踪互联网上实际存在的内容,而是跟踪人们进入Google搜索的关键字和短语。最终变得如此可变,以至于基本上毫无价值。有关此主题的有趣讨论,请参阅Rick Wicklin撰写的这篇文章。
网站流行度 - 在之前的版本中,我已经包含了这方面的措施。然而,随着企业格局的巩固,我们最终将远远超出分析领域(例如IBM)的大型公司与相对较小的重点公司进行比较,这些公司已经不再有意义了。
结论
虽然每个软件包的排名取决于所使用的标准,但我们仍然可以看到主要趋势。在倾向于用作预写方法集合的软件中,R,SAS,SPSS和Stata往往位于顶部,R和SAS偶尔会根据所使用的标准交换位置。我没有在这个组中包含Python,因为我很少看到有人专门用它来调用预编写的例程。(译者按:这个与编写 pre-written methods 我确实没找到)
在倾向于用作分析语言的软件中,C / C#/ C ++,Java,MATLAB,Python,R和SAS始终处于领先地位。我按字母顺序列出了这些,因为许多措施不仅包括用于分析,还包括其他用途。在我的同事中,那些更倾向于数据科学领域的计算机科学领域的人倾向于选择Python,而那些更倾向于统计数据发送的人往往更喜欢R.一个值得一提的语言是Julia,其目标是拥有语法像Pythons一样干净,同时保持C / C#/ C ++组达到的最高速度。
我发现非常有趣的趋势是使用工作流程(或流程图)控制方式的软件的兴起。虽然菜单驱动的软件易于学习,但重复使用这项工作并不容易。工作流驱动的软件几乎一样容易 - 控制每个节点的对话框几乎与菜单驱动的软件相同 - 但您也可以保存并重复使用工作。使用此方法的软件包括:KNIME,Microsoft Azure机器学习,RapidMiner,SPSS Modeler(第一个推广这种方法),SAS Enterprise Miner,SAS Studio,甚至还有两个我没有跟踪过的基于云的系统,Dotplot Designer和Microsoft Azure机器学习。此接口的广泛使用允许非程序员使用高级分析。
我对测量软件流行度的其他方法感兴趣。如果您对此主题有任何想法,请通过muenchen.bob@gmail.com与我联系。
如果您是有兴趣了解R的SAS或SPSS用户,您可以考虑我的书,R for SAS and SPSS Users。Stata用户可能会考虑R for Stata Users用户阅读,这是我与Stata大师Joe Hilbe一起写的。我还在线和实地考察讲授这些主题的研讨会。
致谢
I am grateful to the following people for their suggestions that improved this article: John Fox (2009) provided the data on R package growth; Marc Schwartz (2009) suggested plotting the amount of activity on e-mail discussion lists; Duncan Murdoch clarified the pitfalls of counting downloads; Martin Weiss pointed out both how to query Statlist for its number of subscribers; Christopher Baum provided information regarding counting Stata downloads; John (Jiangtang) HU suggested I add more detail from the TIOBE index; Andre Wielki suggested the addition of SAS Institute’s support forums; Kjetil Halvorsen provided the location of the expanded list of Internet R discussions; Dario Solari and Joris Meys suggested how to improve Google Insight searches; Keo Ormsby provded useful suggestions regarding Google Scholar; Karl Rexer provided his data mining survey data; Gregory Piatetsky-Shapiro provided his KDnuggets data mining poll; Tal Galili provided advice on blogs and consolidation, as well as Stack Exchange and Stack Overflow; Patrick Burns provided general advice; Nick Cox clarified the role of Stata’s software repositories and of popularity itself; Stas Kolenikov provided the link of known Stata repositories; Rick Wicklin convinced me to stop trying to get anything useful out of Google Insights; Drew Schmidt automated some of the data collection; Peter Hedström greatly improved my search string for Stata; Rudy Richardson pointed out that GraphPad Prism is widely used for statistical analysis; Josh Price and Janet Miles provided expert editorial advice.
参考书目
- J. Fox. Aspects of the Social Organization and Trajectory of the R Project. R Journal, http://journal.r-project.org/archive/2009-2/RJournal_2009-2_Fox.pdf
- R. Ihaka and R. Gentleman. R: A language for data analysis and graphics. Journal of Computational and Graphical Statistics, 5:299–314, 1996.
- R. Muenchen,http://sites.google.com/site/r4statistics/books/r4sas-spss,Springer,2009年
- R. Muenchen, J. Hilbe, R for Stata Users, Springer, 2010
- M. Schwartz, 1/7/2009, http://tolstoy.newcastle.edu.au/R/e6/help/09/01/0517.html
商标
Alpine, Alteryx, Angoss, Microsoft C#, BMDP, IBM SPSS Statistics, IBM SPSS Modeler, InfoCentricity Xeno, Oracle’s Java, SAS Institute’s JMP, KNIME, Lavastorm, Mathworks’ MATLAB, Megaputer’s PolyAnalyst, Minitab, NCSS, Python, R, RapidMiner, SAS, SAS Enterprise Miner, Salford Predictive Modeler (SPM) etc., SAP’S KXEN, Stata, Statistica, Systat, WEKA / Pentaho are are registered trademarks of their respective companies.
Copyright 2010-2017 Robert A. Muenchen, all rights reserved.
(2009.02)对比数据分析包:R Matlab SciPy Excel SAS SPASS Stata
发表于 2009年2月23日
Lukas和我试图对最常用于数据分析的最受欢迎的软件包进行简洁的比较。我认为大多数人根据他们周围的人使用或在学校学到的东西选择一个,所以我发现很难找到比较信息。我在这里张贴表格希望得到有用的评论。
| Name | Advantages | Disadvantages | Open source? | Typical users |
|---|---|---|---|---|
| R | Library support; visualization | Steep learning curve | Yes | Finance; Statistics |
| Matlab | Elegant matrix support; visualization | Expensive; incomplete statistics support | No | Engineering |
| SciPy/NumPy/Matplotlib | Python (general-purpose programming language) | Immature | Yes | Engineering |
| Excel | Easy; visual; flexible | Large datasets | No | Business |
| SAS | Large datasets | Expensive; outdated programming language | No | Business; Government |
| Stata | Easy statistical analysis | No | Science | |
| SPSS | Like Stata but more expensive and worse |
[ 7/09更新:调整包含一些精彩的评论,尤其是 对于SAS,SPSS和Stata。]
每个单元格都有更多的话要说。包含的项有:
- 桌面上有两大分类:面向编程的解决方案是R、Matlab、Python。偏向分析解决方案是Excel、SAS、Stata和SPSS。
- Python“不成熟”:matplotlib,numpy和scipy都是独立的库,并不总是相处。为什么matplotlib带有“pylab”,它应该是所有内容的统一命名空间?是不是scipy应该这样做?为什么numpy和scipy之间存在重复(例如numpy.linalg与scipy.linalg)?然后是包兼容版本地狱。您可以使用SAGE或Enthought,但两者都不是标准(尚未)。在功能和方法方面,SciPy最接近Matlab,但感觉不太成熟。
- Matlab的语言肯定很弱。它有时似乎不仅仅是包装矩阵库的脚本语言。在大多数情况下,Python显然更好。如果您能够通过标准库中奇怪的语言结构和奇怪的功能,那么R的表现非常出色(方案派生,智能使用命名args等)。每个人都说SAS非常糟糕。
- Matlab是开发新数学算法的最佳选择。在机器学习中很受欢迎。
- 我从未使用过Matlab统计工具箱。我想知道,与R相比有多好?
- 这是SAS / Stata与R上一个有趣的reddit线程。
- SPSS和Stata在同一类别中:它们似乎有类似的作用,所以我们把它们放在一起。Stata比SPSS便宜很多,人们通常都喜欢它,而且它似乎很受欢迎的入门课程。我个人还没用过…
- SPSS和Stata为“科学”:我们已经看到生物学家和社会科学家使用大量的Stata和SPSS。我的印象是,那些希望以最简单的方式进行标准统计分析的人们会使用它们,这些分析在许多学科中非常正统。(ANOVA,多元回归,t-和卡方显着性检验等)某些类型的科学家,如物理学家,计算机科学家和统计学家,往往做一些不适合这些传统方法的东西。
- 至少从我的角度来看,关于SAS的另一个重要的事情是,它主要由年长的人群使用。我知道30多岁以下的人做统计工作,只有一个人知道SAS。在上周举行的R聚会上,Jim Porzak向观众询问是否有最近在学校学过R的研究生。许多人的手都上升了。然后他问SAS是否作为一种选择提供。所有的手都掉了下来。在那次会议上有一大批SAS代表,他们肯定不会处于领先地位。
- 但是:除了SAS之外还有什么包可以对不适合内存的数据集进行分析吗?那些大多数都要留在磁盘上的?那么SAS的功能究竟有多好?
- 如果您的数据集无法放在单个硬盘驱动器上并且您需要一个群集,则上述任何一个都不起作用。有一些多机器数据处理框架在某种程度上是标准的(例如Hadoop,MPI),但标准的分布式数据分析框架将是一个悬而未决的问题。(蜂巢?猪?或者很可能是别的东西。)
- (这是R meetup 的一个有趣点.Porzak正在讨论如何利用MySQL来解决R的内存限制。但是Itamar Rosenn和Bo Cowgill(分别是Facebook和Google)正在讨论需要集群计算的多机数据集R至少现在还没有接触到它。这只是一个与大型数据集完全不同的球赛。)
- SAS人员抱怨图形功能不佳。
- R与Matlab可视化支持是有争议的。我听过的一个观点是,R的可视化非常适合探索性分析,但是对于非常高质量的图形,您需要其他东西。Matlab的互动情节虽然非常好。Matplotlib遵循Matlab模型,这很好,但比IMO更丑。
- Excel拥有远远超过任何其他选项的用户群。知道这一点很重要。我认为它被计算机科学家的某种人低估了。但它确实在> 10k或大约10万行时大量分解。
- 另一种选择:Fortran和C / C ++。它们速度超快,内存效率高,但是代码难度大且容易出错,不得不花费大量时间来处理I / O,并且没有可视化和数据管理支持。上面列出的大多数软件包都运行Fortran数字库来进行繁重的工作。
- 另一种选择:Mathematica。我得到的印象更多的是理论数学,而不是数据分析。谁能证明我错了?
- 另一种选择:pre-baked data mining packages.。我所知道的开源软件是Weka和Orange。我听说还有数以万计的商业产品。杰罗姆·弗里德曼(Jerome Friedman)是一位重要的统计学家,有一个有趣的抱怨,他们应该更多地关注重要性测试和实验设计等传统事物。(这里 ;启发这种rant的文章。)
- 我认为了解典型用户的来源对于您在软件功能和用户社区中可以看到的内容非常有用。对于所有这些选项,我都喜欢这方面的更多信息。
人们怎么想?