以豆瓣的电影排行榜为例子
在开发者工具中可以看到,随着页面滚动条的下滑,network 中 XHR 的文件数不断增加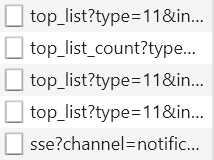
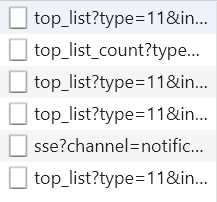
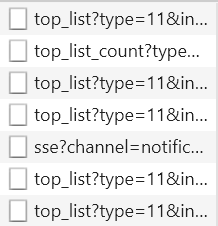
点击新增的文件,对比后可以发现 params 中的 start 发生改变



根据上述发现的不同,可以利用循环语句来获取分页查询的数据
获取一次查询的数据
import requests
url = "https://movie.douban.com/j/chart/top_list"
param = {
"type": "11",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3766.400 QQBrowser/10.6.4163.400"
}
resp = requests.get(url=url,params=param,headers=headers)
with open ("C://Users//lixt6//Desktop//mydouban.html",mode="a",encoding="Utf-8") as f:
f.write(resp.text)
加入循环语句
import requests
url = "https://movie.douban.com/j/chart/top_list"
for i in range(3):
param = {
"type": "11",
"interval_id": "100:90",
"action": "",
"start": i*20,
"limit": 20
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3766.400 QQBrowser/10.6.4163.400"
}
resp = requests.get(url=url,params=param,headers=headers)
with open ("C://Users//lixt6//Desktop//mydouban.html",mode="a",encoding="Utf-8") as f:
f.write(resp.text)
版权声明:本文为llllliznc原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。