Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021
链接:https://aclanthology.org/2021.findings-acl.122.pdf
参考:2021ACL中文文本纠错论文:Global Attention Decoder for Chinese Spelling Error Correction 论文笔记 - 知乎
摘要
近期BERT在CSC中的应用大多基于局部上下文信息,对词进行修正。
- 没有考虑句子中错词的影响。
- 对错误语境信息的关注会误导并降低CSC的表现。
该方法:
- Global Attention Decoder (GAD):潜在正确输入字符与潜在错误输入字符候选字符间的全局关系【获取更丰富的全局上下文信息,减轻局部错误上下文影响】
- A BERT with Confusion set guided Replacement Strategy(BERT_CRS):带有混淆集引导替换策略的BERT,缩小与下游任务CSC间的距离。
- 生成的候选字符覆盖正确字符概率>99.9
- 比其他模型性能高处6.2%,SOTA
结论
- GAD(全局注意解码器):在潜在正确输入字符与潜在错误输入字符候选字符条件下,学习全局关系,缓解错误语境。
- BERT_CRS:缩小BERT与CSC差距。
三个数据集上实验表明,BERT_CRS优于以往所有最先进方法,与GAD结合获得了更高的性能。
介绍
- 拼写纠错:发现错误字符/单词→改正
- 错误来源:人类书写、语音识别、光学字符识别(OCR)
- 汉语错别字:字音(83%)、视觉(48%)、语义相似性。
- 难点:同一个字在不同的语境中可能会有很大的变化。

CSC的主要方法:
- 基于语言模型(Yeh et al., 2013; Yu and Li, 2014; Xie et al., 2015
- 基于seq2seq模型 (Wang et al., 2019, 2018)
随着预训练BERT模型出现,取得了更大进展 (Hong et al., 2019; Zhang et al., 2020;
Cheng et al., 2020) ,几乎所有方法都利用了混淆集(音/视相似)
(Yu and Li, 2014)基于候选集生成候选字符,并找出语言模型判断概率最高的候选字符。
(Cheng et al., 2020)使用卷积网络,利用混淆集捕捉字符之间的相似性和先验依赖关系。
(Wang et al., 2019)提出了一种从混淆集生成字符的指针网络。
之前方法基于含有噪声或其他错误的局部上下文信息来预测每个字符或单词。
流程:
- 为解决局部错误上下文信息,引入潜在错误字符的候选集和由BERT_CRS生成的隐层状态。
- 全局注意力来获取全局隐层状态和潜在全局注意权重。
- 在每个字符的候选字符之间采用加权和算子,生成丰富的全局上下文隐藏状态。
- 用全连接层生成正确字符。
方法概括:
- BERT_CRS缩小二者间差距,决策网络+全连接层,模拟检测+校正。
- 全局注意解码器模型GAD,潜在正确输入字符和潜在错误字符候选字符的全局关系。
在三个基准数据集上的实验表明,方法比最先进的方法性能高出6.2%。
相关工作
N-gram 阶段
CSC的早期研究遵循错误检测、候选生成和候选选择的流程。
- 采用无监督n-gram语言模型来检测错误 (Yeh et al., 2013; Yu and Li, 2014; Xie et al., 2015; Tseng et al., 2015)
引入一个关于字符之间相似性的外部知识混淆集来限制候选字符。
最后,以n-gram语言模型概率最高的候选语言作为校正特征。
具体来说:
- (Yeh et al.,2013)提出了一种基于n-gram的倒置索引,将潜在的拼写错误字符映射到相应的字符。
(Xie et al., 2015)利用混淆集替换字符,然后通过联合2-gram和3-gram语言模型评估修改后的句子。
(Jia et al., 2013; Xin et al., 2014)用图模型表示句子,用单源最短路径(SSSP)算法纠正拼写错误。
其他人将其视为顺序标注问题,并采用条件随机场或隐马尔可夫模型(Tseng et al., 2015;Wang et al., 2018)。
深度学习阶段
深度学习方法 (Vaswani et al., 2017; Zhang et al., 2020; Hong et al., 2019; Wang et al., 2019; Song et al., 2017; Guo et al., 2016)
BERT(Devlin et al., 2018), XLNET(Yang et al., 2019), and Roberta(Liu et al., 2019), and ALBERT(Lan et al.,2019) 在很多NLP任务中达到很好的性能水平。
混淆集仍然是近年来CSC任务研究的一个重要组成部分,但已经有了更多的改进。
具体来说:
(Hong et al.,2019)采用预先训练好的掩码语言模型作为编码器,置信度-相似度解码器利用相似度评分来选择候选项,而不是混淆集。
(Vaswani et al. 2017)提出了一种专门的图卷积网络,将语音和视觉相似度知识整合到BERT模型中。
(Zhang et al.,2020)引入了基于GRU的检测网络,并通过软掩码技术与基于BERT的校正网络连接。
(Wang et al.,2019)采用了带有复制机制的Seq2Seq模型,该模型考虑到混淆集中额外的候选词生成新的句子。
方法
问题形成
BERT_CRS
给定一段序列x1到xn,BERT CRS模型将其编码到一个连续的表示空间![]() ,
,![]() ,表示每个字符的上下文特征,d维。
,表示每个字符的上下文特征,d维。
利用决策网络 ![]() ,将V建模得到一段序列,
,将V建模得到一段序列,![]() ,zi表示第i个字符的检测标签,为1则说明字符不正确,为0说明正确。
,zi表示第i个字符的检测标签,为1则说明字符不正确,为0说明正确。
BERT_CRS最顶的全连接层作为纠错网络![]() 对V建模得到一段序列,
对V建模得到一段序列,![]() ,yi表示每个字符的正确标签。
,yi表示每个字符的正确标签。
GAD
对额外的候选字符![]() 进行建模,减轻局部错误上下文信息的影响,其中c表示潜在的正确输入字符和潜在错误字符的候选字符,
进行建模,减轻局部错误上下文信息的影响,其中c表示潜在的正确输入字符和潜在错误字符的候选字符,
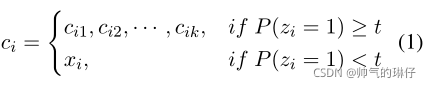
k是候选字符的数量,t是字符错误的概率
CSC的BERT_CRS方法
结合了之前BERT的方法,引入了使用混淆集的替换策略,缩小BERT和CSC模型的差距。
BERT_CRS改动:
- 抛弃了NSP任务,使用决策网络检测错误信息,与CSC的检测子任务相似。
- 与MacBERT (Cui et al., 2020)类似,引入了混淆集引导替换策略,通过替换语音和视觉相似字符来实现掩蔽,而不是使用[MASK] token。类似于CSC纠错子任务。
使用23%的输入字符进行屏蔽。为了保持检测目标的平衡(不替换为0,替换为1),我们分别设置35%、30%、30%、5%的不MASK概率、用混淆字符替换、用[MASK] token掩蔽和用随机词替换。通过计算,替换概率和掩蔽概率与BERT的掩蔽概率大致相同。
通过混淆集引导替换策略训练模型,前k个候选字符几乎来自混淆集。为GAD模型做了准备。
学习过程
如RoBERTa(Liu et al., 2019)一样,在训练了期间使用动态方法。在学习过程中,错误检测和纠正同时得到优化。
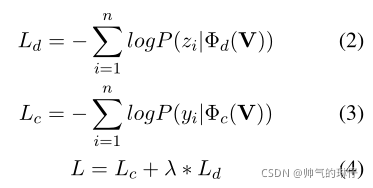
λ=0时,说明检测损失不纳入考虑之中。
Global Attention Decoder
GAD是Transformer层的一种延伸。
自注意力
transformer层的一部分,它将前一个transformer层或输入嵌入层的输出作为输入,以获得具有更高语义表示的隐藏状态,如图1左侧所示
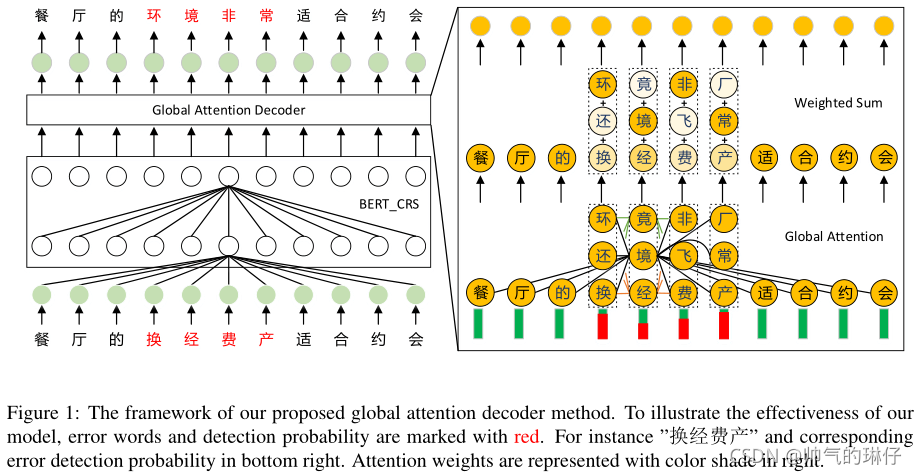
自注意力方法的第l层的第i个位置token表示为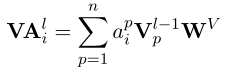 ,
,![]() 表示第p个token的注意力权重,所有位置的α加起来为1(对每个地方施以多少注意力)
表示第p个token的注意力权重,所有位置的α加起来为1(对每个地方施以多少注意力)
![]() 第p个字符,在l-1层的表示。
第p个字符,在l-1层的表示。![]() 可学习的映射矩阵。该策略可以有效地编码丰富的标记和句子级特征。然而,拼写错误信息也被编码到CSC的隐藏状态中。因此,对错误上下文信息的关注可能会误导和降低CSC的整体性能。
可学习的映射矩阵。该策略可以有效地编码丰富的标记和句子级特征。然而,拼写错误信息也被编码到CSC的隐藏状态中。因此,对错误上下文信息的关注可能会误导和降低CSC的整体性能。
Global Attention
与上方等式代表的局部信息不同,学习潜在的正确输入和潜在错误字符的候选间的关系,减轻局部上下文引起的影响。
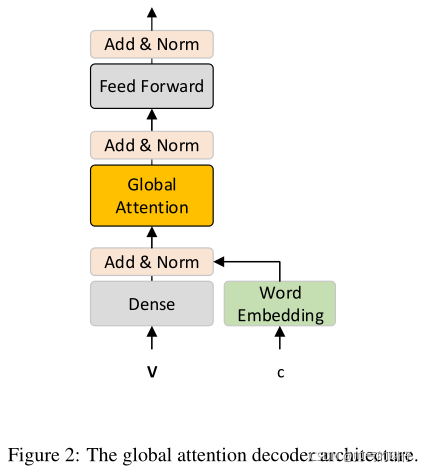
两个输入源:
上下文表示V,包含丰富的语义信息
由
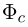 纠错网络生成的TOP-K候选字。为了减少学习过程中GAD的混乱,我们只为潜在错误字符生成候选字符。
纠错网络生成的TOP-K候选字。为了减少学习过程中GAD的混乱,我们只为潜在错误字符生成候选字符。
为了对两种不同信息建模,首先使用BERT-CRS中的单词嵌入E将候选词嵌入到连续表示中。然后将全连接层和正则化引入模型V和E(c)的输入状态GI:
![]()
全局注意力部分
第 i个token的第j个候选词的输出表征:
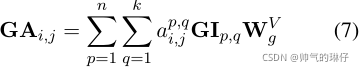
![]() 可学习的映射矩阵,
可学习的映射矩阵,![]() 第i个token第j个候选字符到第p个token的第q个候选字符的注意力权重,
第i个token第j个候选字符到第p个token的第q个候选字符的注意力权重,![]() 第p个token第q个候选字符的表示,并对同一个token的不同候选词采用了mask策略。
第p个token第q个候选字符的表示,并对同一个token的不同候选词采用了mask策略。
![]() ,
,![]()
将每个token的TOP-K个候选词表征通过注意力机制加权就和,得到token的全局注意力状态GAi。
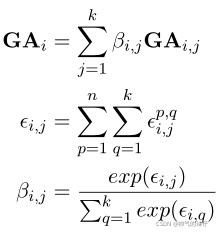
![]() 是第i个token的第j个候选词的全局注意力权重,量化了特征GAi,j的全局相关性。
是第i个token的第j个候选词的全局注意力权重,量化了特征GAi,j的全局相关性。
![]() 和
和![]() 表示
表示![]() 和
和![]() 未进行归一化的相关性分数。
未进行归一化的相关性分数。
学习过程
给定隐藏层状态V和由BERT_CRS生成的候选字符c,GAD模型对正确序列Y在学习过程进行拟合。
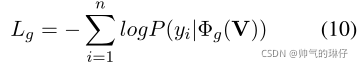
![]() 表示GAD网络
表示GAD网络
实验
数据集
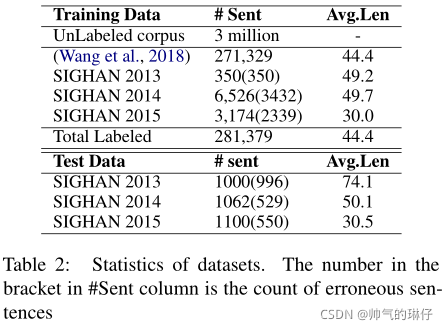
UnLabeled corpus:从新闻、wiki和百科全书QA领域收集了300万个未标记的语料
基线
JBT(Xie et al.,2015):该方法利用混淆集替换字符,然后通过联合双元和三元LM评估修改后的句子。
Hybird (Wang et al., 2018):基于序列标注模型来检测的双向LSTM
Seq2Seq (Wang et al., 2019):该方法引入了具有复制机制的SEQ2SEQ模型,以考虑来自混淆集的额外候选。
FASpell (Hong et al., 2019):该模型通过利用相似性度量而不是预定义的混淆集来选择候选对象,从而改变了模式。
Soft-Masked BERT (Zhang et al., 2020): 该方法提出了一种检测网络,通过软掩码技术连接纠错模型。
SpellGCN (Cheng et al., 2020):该模型通过一个专门的图卷积网络将语音和视觉相似性知识整合到CSC的语言模型中。
BERT (Devlin et al., 2018):在BERT顶部嵌入单词作为CSC任务的校正解码器。
实现细节
训练细节:
1.代码基于Transfomer,基于wwmBERT在300万未标记语料库中先对BERT_CRS进行了微调。
batchsize:1024
学习率:5e-5
max sequence length:512
2.在标记训练数据上微调6epochs,batchsize32,学习率2e-5。
3.固定BERT_CRS模型,候选数k和错误检测概率t设置为4和0.25.
4.微调GAD模型3epochs,batchsize32,学习率5e-5
5.由于SIGHAN 13中的数据分布不同于其他数据集,进行了6epochs的微调,区分了的地得。
评估指标
字符和句子级别的准确性、精确性、召回率和F1
官方的评估工具,给出句子级别的误报率(FRT)、准确度、召回率、F1和准确度。
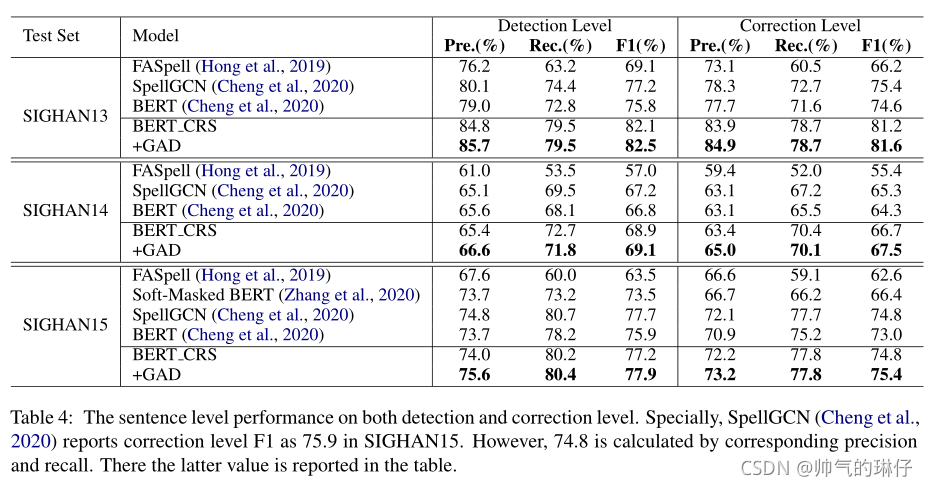
案例分析
