1 什么是数据湖?
数据湖这个词目前已经流行开来,逐步被数据相关的从业者接受,可能还有很多人不太清楚它和Hadoop,Hive,Spark这些大数据系统的区别,简单说数据湖是个业务概念,主要是为了区别传统数仓这个概念的(传统数仓的定义:data warehouse,是用于报告和数据分析的系统,被认为是商业智能的核心组件)。
为什么说是“传统数仓”,因为Hadoop 于 2006 年诞生至今已有10多年了,在这期间大量的公司,尤其是互联网公司用Hadoop相关的系统来完成之前数据仓库要完成的任务,也就是实现上和传统的数据仓库完全不同了,很多人也称之为“现代数仓”。数据湖算是为当前这类系统起了个专门的名字,在Wikipedia、各大云服务厂商的网站上都有数据湖的定义,它们的定义大同小异,主要意思是:
数据湖是一个集中存储区,用于存储大量结构化(比如字段结构清晰的二维表)、半结构化(比如Json,XML格式文件)或非结构化(音视频文件)的数据,支持对这些数据进一步处理,用来生成报表, 数据分析和机器学习等
从上面的定义看,一个包括基本组件的Hadoop系统(hdfs,Mapreduce,Hive)岂不就是数据湖?答案是肯定的,一个包括基本组件的Hadoop系统是数据湖的实现方式之一,数据湖是个业务概念,Hadoop系统是具体的实现数据湖的技术。
2 Hudi, Iceberg, Delta Lake是什么
提到数据湖,很多人会和上面三个词联系起来,甚至觉得不用到上面三个技术的系统不是数据湖。这是不对的,数据湖是个业务概念,Hudi、Iceberg这些只是实现技术之一,而且仅用到Hudi、IceBerg或Delta Lake无法实现数据湖。
具体这这三者是什么,先看一下它们官网的定义:
Iceberg is a high-performance format for huge analytic tables. Iceberg brings the reliability and simplicity of SQL tables to big data, while making it possible for engines like Spark, Trino, Flink, Presto, and Hive to safely work with the same tables, at the same time.
Delta Lake is an open source storage layer that brings reliability to data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Delta Lake runs on top of your existing data lake and is fully compatible with Apache Spark APIs. Delta Lake on Azure Databricks allows you to configure Delta Lake based on your workload patterns.
Hudi is a rich platform to build streaming data lakes with incremental data pipelines
on a self-managing database layer, while being optimized for lake engines and regular batch processing.
从官网的定义看,Iceberg和Delta Lake明确说自己是一种存储层的组件,可以用来构建数据湖。Hudi把自己定义成“rich platform”,从它当前提供的具体功能看,它也只是一种存储层的组件,或者说,它们三者都是某种“表格式”。
3 什么是表格式?
把原始数据映射成表,基于一定格式的表,我们能使用我们最喜欢的工具和语言与数据进行交互,就像我们用sql与数据库进行交互一样。表格式允许我们将不同的数据文件抽象为一个单一的数据集,一个表格。
大数据场景下的数据通常包括很多个文件,我们可以使用 Spark 和 Flink 等计算引擎,使用Scala 、 Java 、SQL等语言来分析这些数据。将大量文件分组然后定义为单个数据集或表格,分析起来就容易得多(与手动分组文件或一次分析一个文件相比)。还有个很重要的点,SQL 可能是进行数据分析最常用的语言(没有之一),而SQL 依赖于”表”的概念。
4 Hive:第一代表格式
大数据中最早的表格式是 Apache Hive。在 Hive 中,表被定义为一个或多个特定目录中的所有文件。Hive表格式已经可以满足很多场景下,通过 SQL 来分析大数据的需求,但随着数据量的增大、分析场景变得复杂, Hive表格式显露出了一些不足,比如ACID支持,在云服务对象存储上效率的问题等,于是人们开发出了其他的表格格式。
5 下一代表格式
Apache Iceberg、Apache Hudi 和Delta Lake是目前比较有影响的三种下一代表格式,这三者都使用了类似的方法,也就是通过充分利用表的元数据(metadata)来扩展Hive表无法提供的功能。
元数据(metadata)是表格式的核心,通过它来确定:
表的名称、位置;表里的字段;表的分区;该表由哪些数据文件组成
虽然Apache Iceberg、Apache Hudi 和Delta Lake都通过利用元数据来增加功能,但不同格式间有很多差异,在不同的使用场景下,一种表格格式可能比另一种更有优势。
三种表格式功能差异:

下面分别对比三种表格式对这4类功能的实现方式
ACID 支持
不同于Hive 的基于目录的表结构,新一代的表结构在很多操作类型上提供ACID(原子性、一致性、隔离性、持久性)保证,例如插入、删除和更新操作。而且下一代表格式一般都支持这些事务的并发执行。下面简单介绍三种表结构实现ACID的方式。
Apache Iceberg通过元数据树(即metadata files, manifest lists, manifests),提供了快照隔离和 ACID 支持。运行查询时,Iceberg 默认使用最新的快照,对任何写入会创建一个新快照,这样不会影响并发查询。对并发写入的支持是通过“乐观型并发”来实现的。除了常用的新增、插入和合并之外,Apache Iceberg 还可以进行行级更新和删除。而且这些操作都可以通过SQL 命令完成。
Apache Hudi 的实现方式是将所有事务分成不同类型的组,同组内的操作根据时间线来顺序执行。Hudi 的实现是基于目录的方式,使用带有时间戳的文件,以及跟踪数据文件更改的Log files。Hudi 允许选择启用元数据表以进行查询优化(元数据表从 0.11.0 版本开始默认开启)。Apache Hudi 为CREATE TABLE、INSERT、UPDATE、DELETE和Queries提供原子操作和 SQL 支持
Delta Lake的实现方式是跟踪两类元数据文件,Delta Logs(按顺序跟踪表的更改和Checkpoints(汇总了到该点为止对表的所有更改),Delta Lake 还支持 ACID 事务,通过SQL操作表的创建、插入、合并、更新和删除。
可变分区
使用过Hive的对分区肯定不陌生,有了分区,查询的时候不用每次都扫描整个表,效率提升非常明显,为了能高效地查询数据,分区是一个非常重要的功能。实际应用中,表的分区方案需要随着时间或需求的变更而改变,但是在Hive表结构上更改分区是一个非常繁重的操作,比如数据之前是按年分区的,我们想将其更改为按月分区,则需要重写整个表。在管理大规模数据的时候,支持低成本的分区变更尤为重要。
下面分别介绍一下三种新的表结构对分区演变的支持。
Apache Iceberg 是目前唯一支持可变分区的表格式。它通过跟踪分区列和列上的转换(如将时间戳转换为一天或一年)来实现分区。 Hive的分区实现方法依赖于特定列,用户需要知道哪个列是分区列,把筛选条件加到分区列上才能获得查询效率的提升。Iceberg 的新分区方式,让用户不必知道具体哪个是分区列。
例如,一个基于时间戳的分区列,可以按年份分区,当需要按月分区的时候,使用 ALTER TABLE 语句就可以轻松切换到月份。
ALTER TABLE db.sample ADD PARTITION FIELD months(ts)Iceberg这种不必创建专门的用于分区的列就能提高查询效率的分区方法,又被称为隐式分区。
Apache Hudi通过使用data skipping功能可以达到隐式分区类似的效果(目前仅支持read-optimized模式下的表)。
Delta Lake通过generated columns 功能实现类似隐式分区的功能,该功能目前为 Databricks Delta Lake 提供的公共预览版,还不支持 OSS Delta Lake。
Schema变更
数据格式需要随着需求的变化而被更改,比如:重命名列、更改字段类型、添加列等等。所有三种表格式都支持不同级别的Schema变更。下面的图表详细列出了可以对表的结构进行的哪些类型的更改。
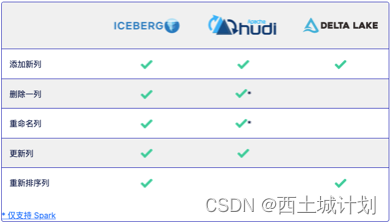
多版本数据
多版本数据允许我们查询表的先前状态的数据。一个常见的用例是在机器学习应用中,在先前模型测试中使用的相同数据上测试更新的机器学习算法。需要将模型与相同的数据进行比较才能正确理解对模型的更改。
这三者表格式都是通过“快照”来实现多版本数据的支持的。每个快照都包含与其关联的文件。需要定期清理旧的、不需要的快照,以防止不必要的存储成本。每种表格式都有不同的工具来维护快照。
6 如何选择用哪种表格式
不出意外的话,这三种表格式中的一种会取代 Hive,成为数据湖中表的事实标准,在事实标准形成之前,我们可以通过下面这些问题帮助我们选择
哪种格式能提供所需功能的稳定版本
如果用户常用SQL,哪种格式对 SQL 的支持更全面
哪种格式支持的引擎和自己的已有基础设施匹配
哪种格式的社区比较活跃
仔细回答好上面的问题让我们在用好前沿技术时少踩坑
参考文献:
Hello from Apache Hudi | Apache Hudi
Comparison of Data Lake Table Formats (Iceberg, Hudi and Delta Lake)
https://en.wikipedia.org/wiki/Data_lake