任务:利用城市当天的天气、温度、湿度和风速等环境信息对自行车的租借数量进行有效预测,预测每小时内租用的自行车总数。
数据字段
| 特征 | 说明 |
|---|---|
| datetime | 详细到小时的日期+时间戳 |
| season | 季节 1:春天, 2:夏天, 3:秋天, 4:冬天 |
| holiday | 是否是公共假期 |
| workingday | 是否是工作日(不是周末也不是公共假期) |
| weather | 天气情况 1:无云,少量云,部分多云 2:雾+多云,雾+云散开,雾+少云,雾 3:小雪,小雨+雷暴+散云,小雨+散云 4:暴雨+冰雹+雷暴+雾,雪+雾 |
| temp | 以摄氏度为单位的温度 |
| atemp | 以摄氏度为单位的体感温度 |
| humidity | 相对湿度 |
| windspeed | 风速 |
| casual | 未注册用户租赁数量 |
| registered | 注册用户租赁数量 |
| count | 租赁自行车总数,包括未注册和注册 |
导入工具包
import numpy as np
import pandas as pd
import seaborn as sn
import matplotlib.pyplot as plt
%matplotlib inline1. 数据集基本信息
- 读取数据集
- 打印数据集的前几行
- 检测缺失值
- 数据集的大小(维度)
- 变量类型#读取数据集
dataDaily = pd.read_csv("./input/train.csv")
# 查看数据前2行
dataDaily.head()| datetime | season | holiday | workingday | weather | temp | atemp | humidity | windspeed | casual | registered | count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-01 00:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 81 | 0.0 | 3 | 13 | 16 |
| 1 | 2011-01-01 01:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 8 | 32 | 40 |
| 2 | 2011-01-01 02:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 5 | 27 | 32 |
| 3 | 2011-01-01 03:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 3 | 10 | 13 |
| 4 | 2011-01-01 04:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 |
#检测缺失值
dataDaily.isnull().sum()
dataDaily.info()
#数据初步展示
dataDaily.describe()
#数据可视化展示
dataDaily.plot(subplots=True, figsize=(10,20))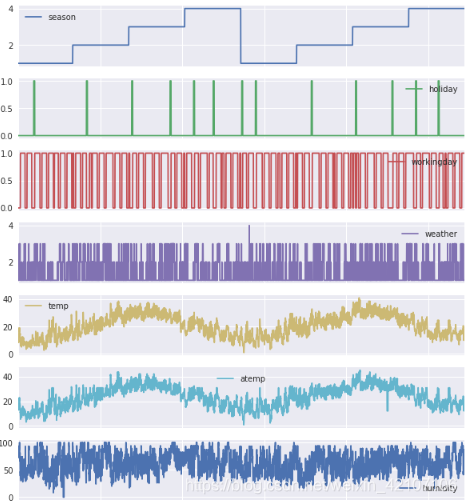
2. 相关分析
seaborn中的热力图是一个有用的描述两个特征之间关系的方法。在这里我们绘制countvs temp温度,humidity湿度,windspeed风速的相关热力图。
corrMat = dataDaily[["temp", "humidity","windspeed", "registered","casual","atemp","count"]].corr()
sn.heatmap(corrMat, annot=True, square=True)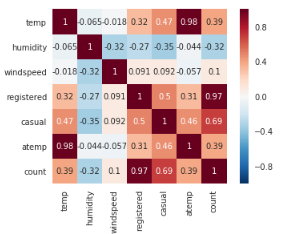
理解因变量如何受特征(数值型)影响的一个常用方法是查看它们之间的相关矩阵。让我们绘制count和数值型特征[temp,atemp,humidity,windspeed]之间的相关图。
temp温度和humidity湿度特征分别与count呈正负相关。尽管它们之间的相关性不明显,但count对temp温度和humidity湿度的依赖性仍然很小。windspeed不是真正有用的数字特征,这可以从它和count的相关值看出来。atemp将不被采纳,因为atemp和temp彼此之间具有很强的相关性。在模型构建期间,必须删除二者其中一个变量,因为它们将在数据中表现出多重共线性。casual未注册用户租赁数量和registered注册用户租赁数量也没有被考虑在内,因为它们本质上是leakage variables泄漏变量(二者相加等于count),需要在模型构建时丢弃。
确定待删除的特征
dropFeatures = ["casual","registered","atemp","datetime"]3. 直接建模
将目标与数据分离
X = dataDaily.drop(dropFeatures, axis=1).copy()
X = X.drop("count", axis=1).copy()
yLabels = dataDaily["count"]
X.describe()| season | holiday | workingday | weather | temp | humidity | windspeed | |
|---|---|---|---|---|---|---|---|
| count | 10886.000000 | 10886.000000 | 10886.000000 | 10886.000000 | 10886.00000 | 10886.000000 | 10886.000000 |
| mean | 2.506614 | 0.028569 | 0.680875 | 1.418427 | 20.23086 | 61.886460 | 12.799395 |
| std | 1.116174 | 0.166599 | 0.466159 | 0.633839 | 7.79159 | 19.245033 | 8.164537 |
| min | 1.000000 | 0.000000 | 0.000000 | 1.000000 | 0.82000 | 0.000000 | 0.000000 |
| 25% | 2.000000 | 0.000000 | 0.000000 | 1.000000 | 13.94000 | 47.000000 | 7.001500 |
| 50% | 3.000000 | 0.000000 | 1.000000 | 1.000000 | 20.50000 | 62.000000 | 12.998000 |
| 75% | 4.000000 | 0.000000 | 1.000000 | 2.000000 | 26.24000 | 77.000000 | 16.997900 |
| max | 4.000000 | 1.000000 | 1.000000 | 4.000000 | 41.00000 |
训练集-测试集划分,比例为70%(训练)--30%(测试)
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(X, yLabels, test_size = 0.3, random_state=42)
# 构建线性回归模型
from sklearn.linear_model import LinearRegression
Model = LinearRegression()
# 用训练集训练模型
Model.fit(X= train_x, y = train_y)
# 模型预测
preds = Model.predict(X= test_x)
#计算RMSE
from sklearn.metrics import mean_squared_error
print "线性回归的标准差RMSE:", mean_squared_error(test_y, preds)线性回归的标准差RMSE: 24042.932357923237
#结果可视化
plt.plot(preds)
plt.plot(np.array(test_y))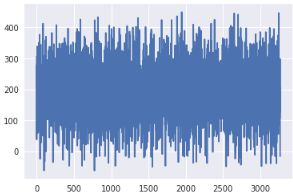
RMSLE 指标
RMSE对预测多了和预测少了的惩罚相同,而在共享自行车需求的预测中,欠预测比过预测的损失会更大,预测值应该是不少于真实值,即投放的自行车数量不应少于真实需求的数量,所以惩罚欠预测大于过预测。
Root Mean Squared Logarithmic Error (RMSLE)的公式如下:
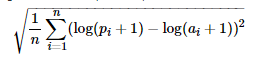
其中:
nn 是测试集中的小时数
pipi 是预测的自行车租用数量
aiai 是实际的自行车租用数量
log(x)log(x) 是自然对数
RMSLE与RMSE一样越小越好,区别在于RMSLE关注的是比例而不是绝对值,惩罚欠预测大于过预测。
![]()
#计算RMSLE
def rmsle(y, y_):
log1 = np.array([np.log1p(v) for v in y])
log2 = np.array([np.log1p(v) for v in y_])
calc = (log1 - log2) **2
return np.sqrt(np.mean(calc))
#用log1p构建新模型,log1p就是 log(x+1),可以避免出现负数结果
lModel = LinearRegression()
lModel.fit(X= train_x, y=np.log1p(train_y))
preds = lModel.predict(X=test_x)
# 回归效果RMSLE评估
print "线性回归的标准差RMSLE:", round(rmsle(test_y, np.expm1(preds)),4)线性回归的标准差RMSLE: 1.2149
#结果展示
plt.plot(np.expm1(preds))
4. 特征工程
- 特征编码
- 构造新特征正如我们从上面的结果中看到的那样,season,holiday,workingday和weather列应该是categorical分类数据类型。但是这些列的当前数据类型是int。 让我们以下列方式转换数据集,以便我们可以做后续的分析。
- 从
datetime列创建新列date,hour,weekDay,month。 - 强制转换
season,holiday,workingday和weather到category类别的数据类型。 - 将
datetime列添加到待删除的列中,因为我们已经从中提取了有用的功能。
对datetime列提取新特征,创建新列
from datetime import datetime
dataDaily["date"] = dataDaily.datetime.apply(lambda x: x.split()[0])
dataDaily["hour"] = dataDaily.datetime.apply(lambda x: x.split()[1].split(":")[0]).astype("int")
dataDaily["year"] = dataDaily.datetime.apply(lambda x: x.split()[0].split("-")[0])
dataDaily["weekday"] = dataDaily.date.apply(lambda x: datetime.strptime(x, "%Y-%m-%d").weekday())
dataDaily["month"] = dataDaily.date.apply(lambda x: datetime.strptime(x, "%Y-%m-%d").month)
dataDaily.head(2)| datetime | season | holiday | working | weather | temp | atemp | humidity | windspeed |
|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-01 00:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 81 |
| 1 | 2011-01-01 01:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 |
分类类型转换成category
categoricalFeatureNames = ["season","holiday","workingday","weather","weekday","month","year"]
for var in categoricalFeatureNames:
dataDaily[var] = dataDaily[var].astype("category")
#展示编码后的新数据列
dataDaily.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 10886 entries, 0 to 10885 Data columns (total 17 columns): datetime 10886 non-null object season 10886 non-null category holiday 10886 non-null category workingday 10886 non-null category weather 10886 non-null category temp 10886 non-null float64 atemp 10886 non-null float64 humidity 10886 non-null int64 windspeed 10886 non-null float64 casual 10886 non-null int64 registered 10886 non-null int64 count 10886 non-null int64 date 10886 non-null object hour 10886 non-null int64 year 10886 non-null category weekday 10886 non-null category month 10886 non-null category dtypes: category(7), float64(3), int64(5), object(2) memory usage: 926.4+ KB
对离散型变量season,weather 进行One-Hot编码,并替换掉原来的列。
season季节 1:春天, 2:夏天, 3:秋天, 4:冬天
weather天气情况 1:无云,少量云,部分多云 2:雾+多云,雾+云散开,雾+少云,雾 3:小雪,小雨+雷暴+散云,小雨+散云 4:暴雨+冰雹+雷暴+雾,雪+雾
dataDaily[["season_orig","weather_orig"]] = dataDaily[["season","weather"]]
dataDaily = pd.get_dummies(dataDaily, columns=["season","weather"], drop_first=True)
dataDaily.head()| datetime | holiday | workingday | temp | atemp | humidity | windspeed | casual | registered |
|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-01 00:00:00 | 0 | 0 | 9.84 | 14.395 | 81 | 0.0 | 3 |
| 1 | 2011-01-01 01:00:00 | 0 | 0 | 9.02 | 13.635 | 80 | 0.0 | 8 |
| 2 | 2011-01-01 02:00:00 | 0 | 0 | 9.02 | 13.635 | 80 | 0.0 | 5 |
| 3 | 2011-01-01 03:00:00 | 0 | 0 | 9.84 | 14.395 | 75 | 0.0 | 3 |
| 4 | 2011-01-01 04:00:00 | 0 | 0 | 9.84 | 14.395 | 75 | 0.0 | 0 |
#展示编码后的新数据列
dataDaily.info()绘制count vs temp,humidity,windspeed, hour 的回归图。
sn.jointplot(x="temp", y="count", data=dataDaily, kind="reg")
sn.jointplot(x="humidity", y="count", data=dataDaily, kind="reg")
sn.jointplot(x="windspeed", y="count", data=dataDaily, kind="reg")
sn.jointplot(x="hour", y="count", data=dataDaily, kind="reg")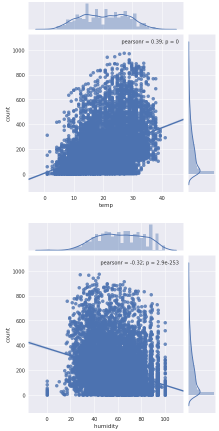
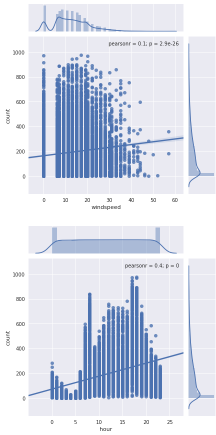
与count之间存在非线性关系,采用加log的方式来构造新特征
dataDaily["log_temp"] = np.log1p(dataDaily.temp)
dataDaily["log_windspeed"] = np.log1p(dataDaily.windspeed)
dataDaily["log_humidity"] = np.log1p(dataDaily.humidity)
dataDaily["log_hour"] = np.log1p(dataDaily.hour)
#展示编码后的新数据列
dataDaily.info()5. 异常值检测和处理
可视化变量与Count之间的关系
ig, axes = plt.subplots(2,2)
fig.set_size_inches(24,12)
sn.boxplot(data=dataDaily, y="count", ax=axes[0][0])
sn.boxplot(data=dataDaily, y="count", x="season_orig", ax=axes[0][1])
sn.boxplot(data=dataDaily, y="count", x="hour", ax=axes[1][0])
sn.boxplot(data=dataDaily, y="count", x="workingday", ax=axes[1][1])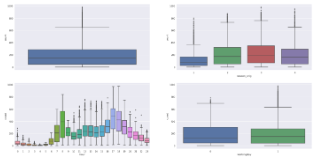
初看起来,count变量包含许多异常值数据点,这些数据点的分布右偏(因为超出外部四分位数限制的数据点更多)。除此之外,还可以从给出的下面的箱图做出以下推断:
- 1.春季用车数量相对较少,这点从箱形图中位数较低可以看出来。
- 2.
Hour Of The Day的箱线图很有意思。中位数的值在早上7点-早上8点和下午5点 - 下午6点相对较高。它可以归因于这些时间段的上学的人和上班族。 - 3.从下图中可以清楚地看出,大多数离群值主要来自
Working Day工作日而不是Non Working Day非工作日。
删除计数列count中的异常值
保留count中与平均值的偏差绝对值在3倍标准差以内的样本
#对数据集进行处理,去掉相关项与无用项
dropFeatures = ["casual","atemp", "datetime","date","registered","count", "season_orig", "weather_orig"]
X = dataDaily.copy().drop(dropFeatures, axis =1)
yLabels = dataDaily["count"]
#固定随机种子,分割数据
train_x, test_x, train_y, test_y = train_test_split(X, yLabels, test_size =0.3, random_state=42)
#得到训练数据
data = pd.concat([train_x, train_y], axis=1)
data.head()| holiday | workingday | temp | humidity | windspeed | hour | year | weekday | month | season_2 |
|---|---|---|---|---|---|---|---|---|---|
| 613 | 0 | 1 | 9.02 | 32 | 39.0007 | 17 | 2011 | 1 | 2 |
| 4030 | 0 | 0 | 22.14 | 68 | 12.9980 | 23 | 2011 | 6 | 9 |
| 3582 | 0 | 1 | 26.24 | 83 | 0.0000 | 4 | 2011 | 4 | 8 |
| 10101 | 0 | 1 | 9.02 | 69 | 8.9981 | 6 | 2012 | 1 | 11 |
| 1430 | 0 | 1 | 13.12 | 81 | 30.0026 | 11 | 2011 | 1 | 4 |
#去除训练数据中的异常值
print data.shape
mean = train_y.mean()
std = train_y.std()
data = data[np.abs(train_y-mean)<=(3*std)]
print data.shape(7620, 20) (7514, 20)
6. 数值特征标准化
要做标准化的特征
numerialFeatureNames = ["temp", "humidity", "windspeed","hour"]
#标准化之前数值型特征的描述性统计量
data.describe()| temp | humidity | windspeed | hour |
|---|---|---|---|
| count | 7514.000000 | 7514.000000 | 7514.000000 |
| mean | 20.150240 | 62.050306 | 12.805329 |
| std | 7.809803 | 19.212934 | 8.215052 |
| min | 0.820000 | 0.000000 | 0.000000 |
| 25% | 13.940000 | 47.000000 | 7.001500 |
| 50% | 20.500000 | 62.000000 | 12.998000 |
| 75% | 26.240000 | 78.000000 | 16.997900 |
| max | 41.000000 | 100.000000 | 56.996900 |
对temp,atemp,humidity,windspeed,hour做最大值最小值标准化,
xscaled=x−min(x)max(x)−min(x)xscaled=x−min(x)max(x)−min(x)
转换之后数据分布在[0,1]区间
#minmax标准化
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(data[numerialFeatureNames])
data[numerialFeatureNames] = scaler.transform(data[numerialFeatureNames])
# 标准化之后数值型特征的描述性统计量
data.describe()现在我们重新构建模型,看看经过数据预处理后模型预测的效果。
7. 重新建模
将目标与数据分离,并删除不必要的特征¶
#构造验证集
dataTest = pd.concat([test_x,test_y], axis=1)
# 用训练集拟合的scaler对验证集做标准化
dataTest[numerialFeatureNames] = scaler.transform(dataTest[numerialFeatureNames])
train_x = data.copy().drop(["count"], axis=1)
train_y = data["count"]
test_x = dataTest.copy().drop(["count"], axis=1)
test_y = dataTest["count"]重新建模预测需求的自行车数量
#重新训练模型
lModel = LinearRegression()
lModel.fit(X = train_x, y = np.log1p(train_y))
preds = lModel.predict(X=test_x)
#在验证集上验证
# 回归效果RMSLE评估
print "新的RMSLE:", round(rmsle(test_y,np.expm1(preds)),4)
新的RMSLE: 0.9734
