相信很多喜欢NBA的小伙伴们经常会关注NBA的数据统计,今天我就用虎扑NBA的得分榜为例,实现NBA数据的简单爬取。
https://nba.hupu.com/stats/players是虎扑体育的NBA球员得分榜:
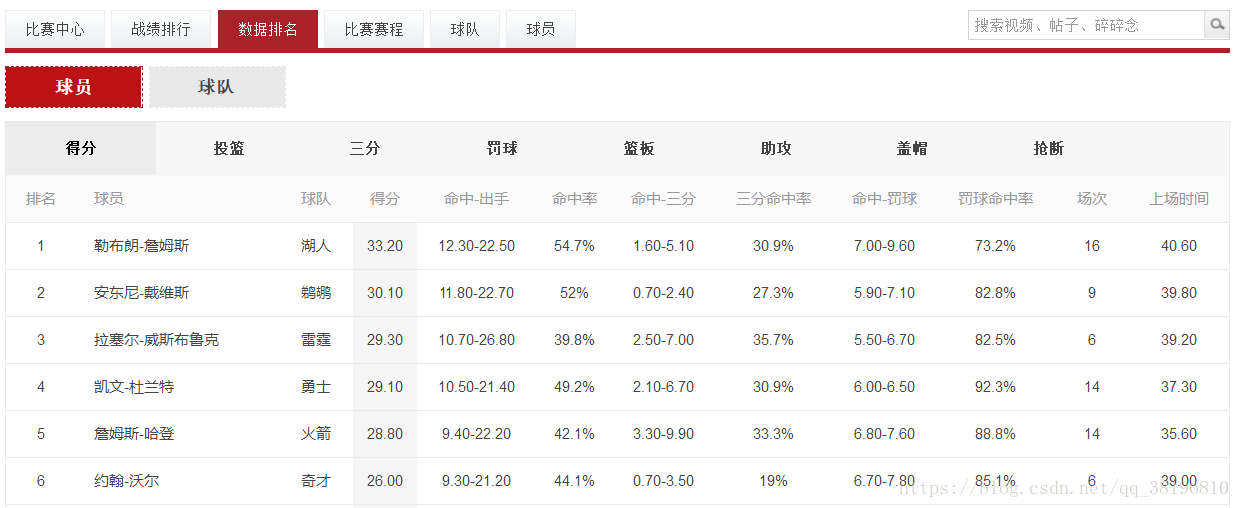
当我们右键查看该网站的源代码时,会发现所有的数据统计都存放在<tbody>的标签下,而<tbody>下的每个<tr>标签则表示每个球员的信息,第1、2、4个<td>标签分别表示球员排名、球员名字和得分。
eg.
| <tr> | |
| <td width="46">1</td> | |
| <td width="142" class="left"><a href="https://nba.hupu.com/players/lebronjames-650.html">勒布朗-詹姆斯</a></td> | |
| <td width="50"><a href="https://nba.hupu.com/teams/lakers">湖人</a></td> | |
| <td class="bg_b">33.20</td> | |
| <td>12.30-22.50</td> | |
| <td>54.7%</td> | |
| <td>1.60-5.10</td> | |
| <td>30.9%</td> | |
| <td>7.00-9.60</td> | |
| <td>73.2%</td> | |
| <td width="50">16</td> | |
| <td width="70">40.60</td> | |
| </tr> |
运用requests库和bs4库,我们可以将球员的数据爬取下来。
首先,我们编写一个getHTMLText方法,用于爬取网页的信息:
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""其次,我们编写一个fillList方法。
因为所有的数据统计都存放在<tbody>的标签下,而<tbody>下的每个<tr>标签则表示每个球员的信息,第1、2、4个<td>标签分别表示球员排名、球员名字和得分,我们采用html.parser解释器,遍历<tbody>标签的所有儿子节点,将球员数据的第1、2、4个<td>标签添加至列表中即可:
def fillList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])最后,我们编写printList方法,将列表中的数据依次输出:
def printUnivList(ulist, num):
for i in range(num):
u = ulist[i]
print("{0:<6}\t{1:{3}<10}\t{2:<6}".format(u[0],u[1],u[2],chr(12288)))将以上方法组合编写主函数如下:
def main():
uinfo = []
url = 'http://nba.hupu.com/stats/players'
html = getHTMLText(url)
fillList(uinfo, html)
printList(uinfo, 21)便将NBA得分榜的前20名球员输出了: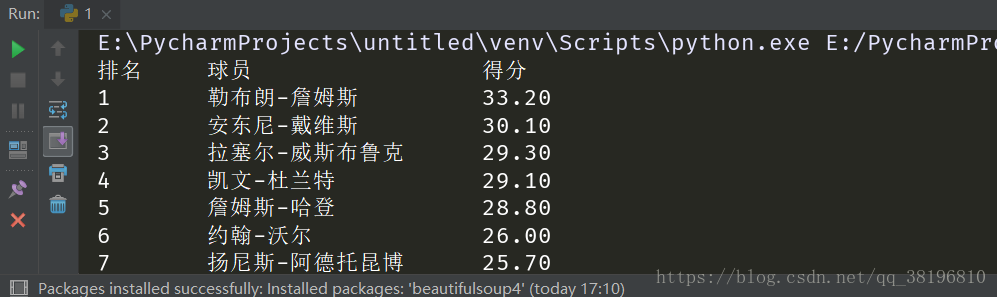
是不是很简单呢?赶紧上手尝试一下吧(手动滑稽)版权声明:本文为qq_38196810原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。