一、垃圾回收
GC是由JVM自动完成的,根据JVM系统环境而定,所以时机是不确定的。当然,我们可以手动进行垃圾回收,比如调用System.gc()方法通知JVM进行一次垃圾回收,但是具体什么时刻运行也无法控制。也就是说System.gc()只是通知要回收,什么时候回收由JVM决定。但是不建议手动调用该方法,因为GC消耗的资源比较大。
GC触发条件
GC是jvm自动完成的,是根据jvm系统环境而定的。大致上来说,满足以下四个条件之一就会触发jvm垃圾回收。
(1)当Eden区或者S区不够用了。
(2)老年代空间不够用了。
(3)方法区空间不够用了。
(4)调用System.gc(),通知jvm进行一次垃圾回收,具体执行还要看JVM,另外在代码中尽量不要用,毕竟GC一次还是很消耗资源的。
stop the world
GC线程回收垃圾时候的会暂停业务线程,之所以要暂停业务线程就是避免出现该回收的对象没有被回收不该回收的对象被回收的情况。
二、垃圾收集算法
已经能够确定一个对象为垃圾之后,接下来要考虑的就是回收,怎么回收呢?得要有对应的算法,下面介绍常见的垃圾回收算法。
2.1、标记-清除
标记-清除:Mark-Sweep。
- 标记:找出内存中需要回收的对象,并且把它们标记出来。
此时堆中所有的对象都会被扫描一遍,从而才能确定需要回收的对象,比较耗时。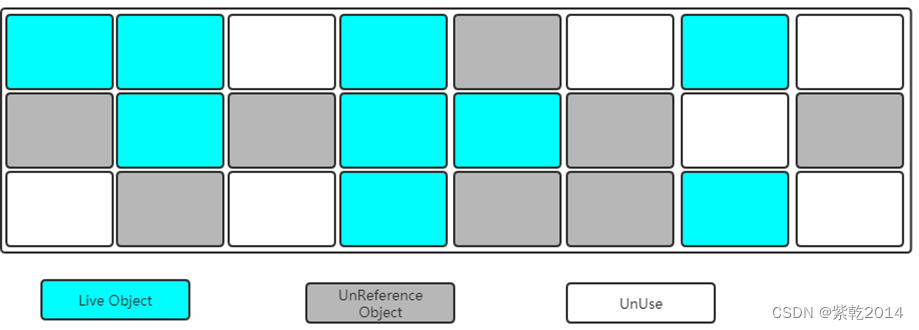
- 清除:清除掉被标记需要回收的对象,释放出对应的内存空间。
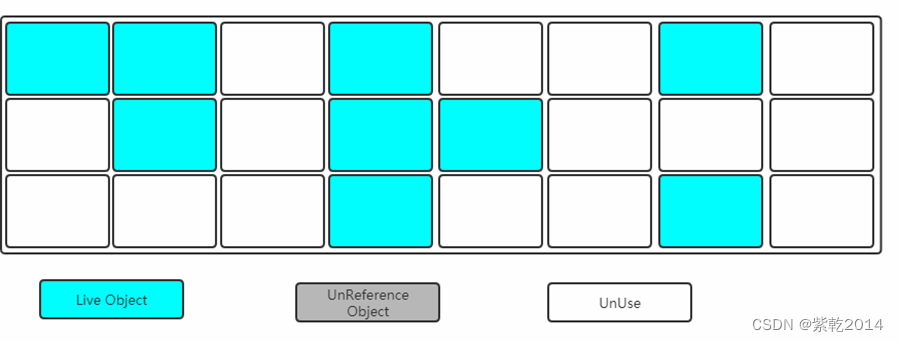
缺点:
(1)标记和清除两个过程都比较耗时,效率不高。
(2)会产生大量不连续的内存碎片。空间碎片太多可能会导致以后在程序运行过程中需要分配较大对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
2.2、标记-复制
标记-复制:Mark-Copying,完整的过程应该是标记复制清除。
将内存划分为两块相等的区域,每次只使用其中一块,如下图所示: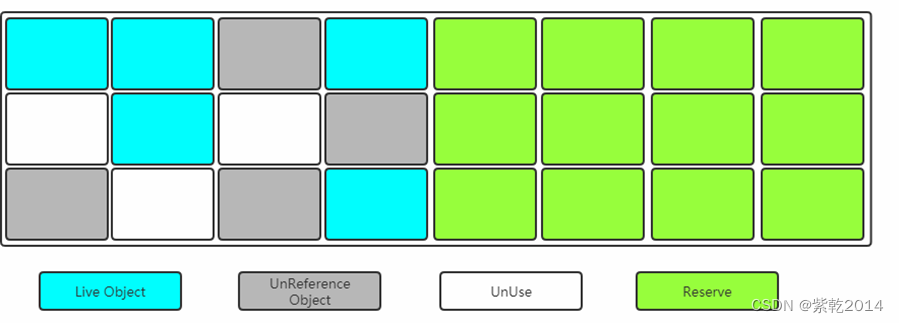
当其中一块内存使用完了,就将还存活的对象复制到另外一块上面,然后把已经使用过的内存空间一次清除掉。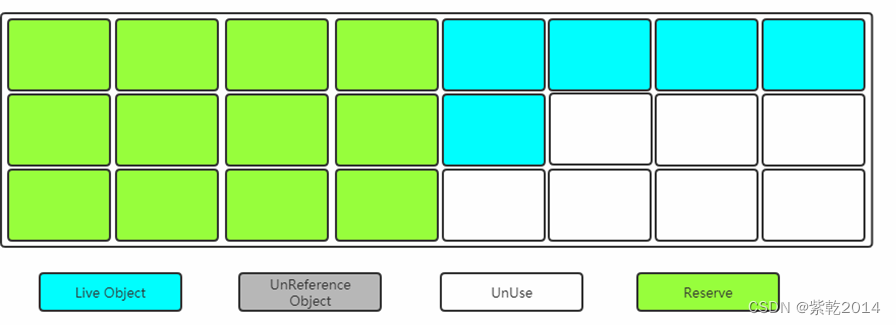
缺点:空间利用率降低。
2.3、标记-整理
标记-整理:Mark-Compact。
复制收集算法在对象存活率较高时就要进行较多的复制操作,效率将会变低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都有100%存活的极端情况,所以老年代一般不能直接选用这种算法。
标记-整理中的标记过程仍然与"标记-清除"算法一样,但是后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。标记整理完整过程是标记整理清除。
其实上述过程相对"复制算法"来讲,少了一个"保留区"。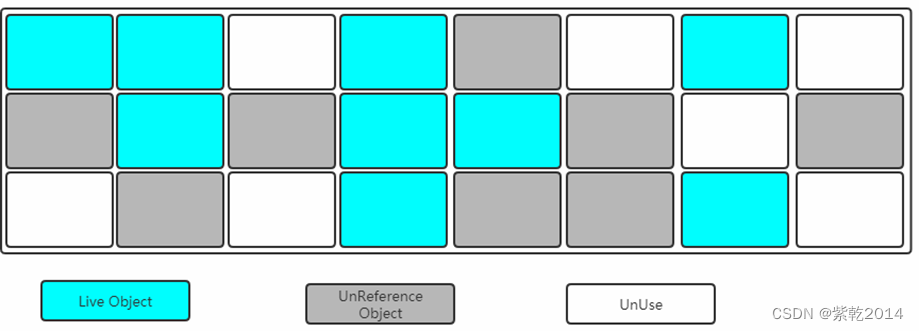
让所有存活的对象都向一端移动,清理掉边界以外的内存。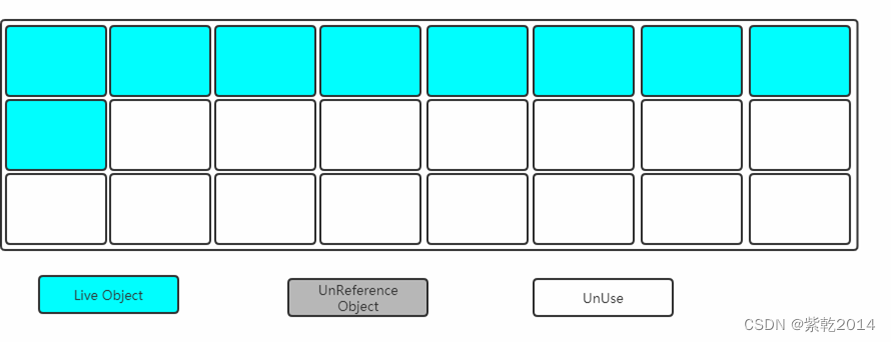
按照整理顺序可以划分为
任意顺序:将存活对象放在一起,但是不考虑存活对象之间的引用顺序,空间碎片较少。
任意顺序中的算法:双指针算法。
双指针算法的双指针同向(快慢)环和反向(对撞)链式区别:
1、适用的存储结构不同
双指针同向(快慢)环适用的是链表环结构。
双指针反向(对撞)适用的是字符串、数组等非环链表结构。
2、执行过程不同
双指针同向(快慢)执行是两根指针同向同时出发,但是一个快一个慢,因为是环形结构,执行快的指针是能追上执行慢的指针。假设执行慢的指针为A指针每次只走一格,执行快的指针为B指针每次走两格,A指针找空闲空间、B指针找可达对象,A指针找到空闲空间就会停下,B指针找到可达对象会将该对象移动到A指针的空闲空间,然后两根指针继续往前走,直到B指针追上A指针,注意当A指针没有处在空闲空间而B指针处在可达对象上,那么此时B指针是会继续往前走的。
双指针反向(对撞)执行是两根指针反向同时出发,头部指针找空闲空间,尾部指针找可达对象,头部指针找到了空闲空间就会先停下,等到尾部指针找到了可达对象,就会将可达对象复制到空闲空间,然后头部指针继续往后走,尾部指针继续找可达,直到两根指针对撞后,头部指针会再往回遍历一遍将头部指针之前的区域依次进行引用更新(针对需要进行引用更新的)然后将尾部指针后面的区域进行清空,示例图如下: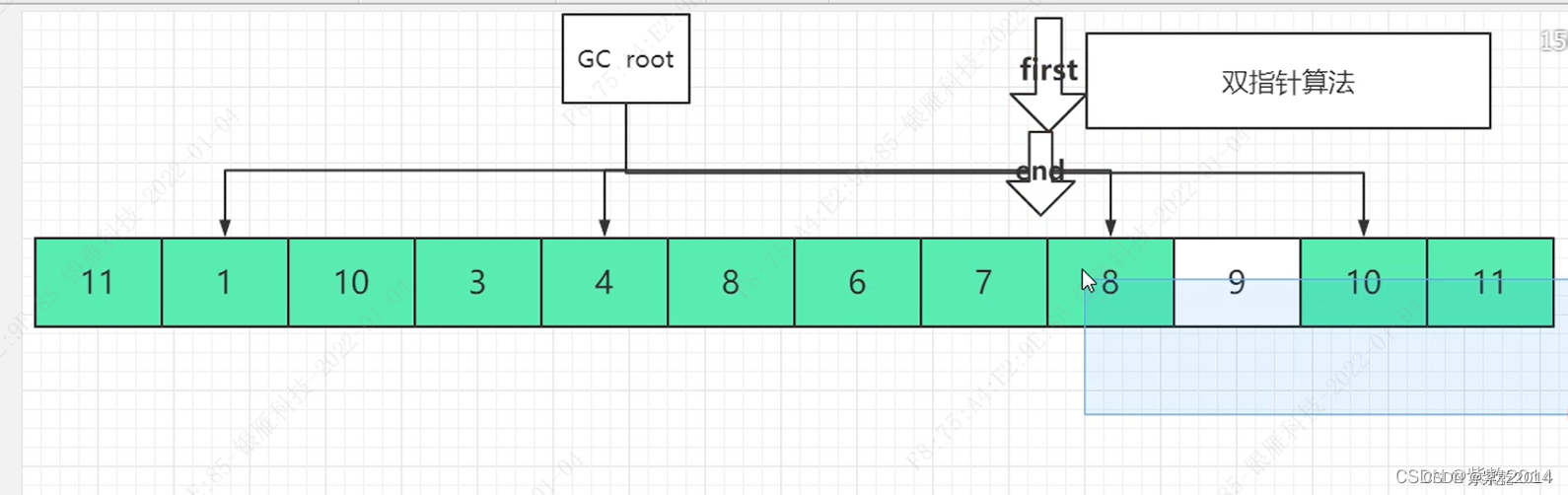
3、缺点
可能会将原本相邻的相关联对象整理成不相邻的对象,这就会导致这些对象本来在一个高速缓存区就能处理而整理后不得不分多个高速缓存区处理。
无论双指针同向(快慢)环还是双指针反向(对撞),总的来说双指针算法比较适合固定大小的对象,如果对象大小不同则会增加额外的判断逻辑。线性顺序:将有引用关系的存活对象放在一起,关联对象隔得近对象查找时间会变短,不考虑空间碎片。
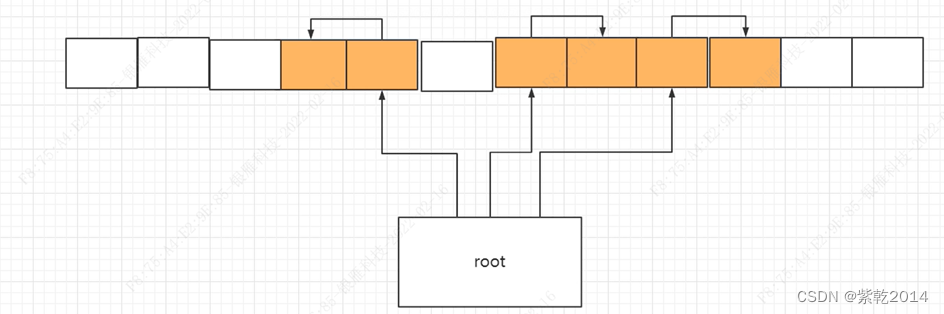
滑动顺序:将有引用关系的存活对象放在一起并滑到一侧,关联对象隔得近对象查找时间会变短,空间碎片较少。
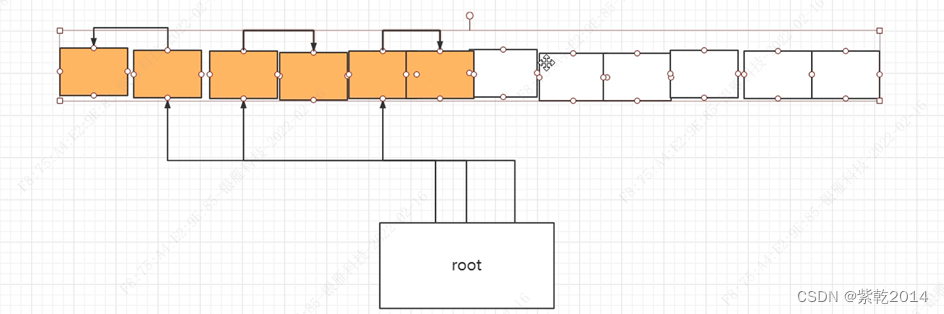
滑动顺序中的算法:
Lisp2算法: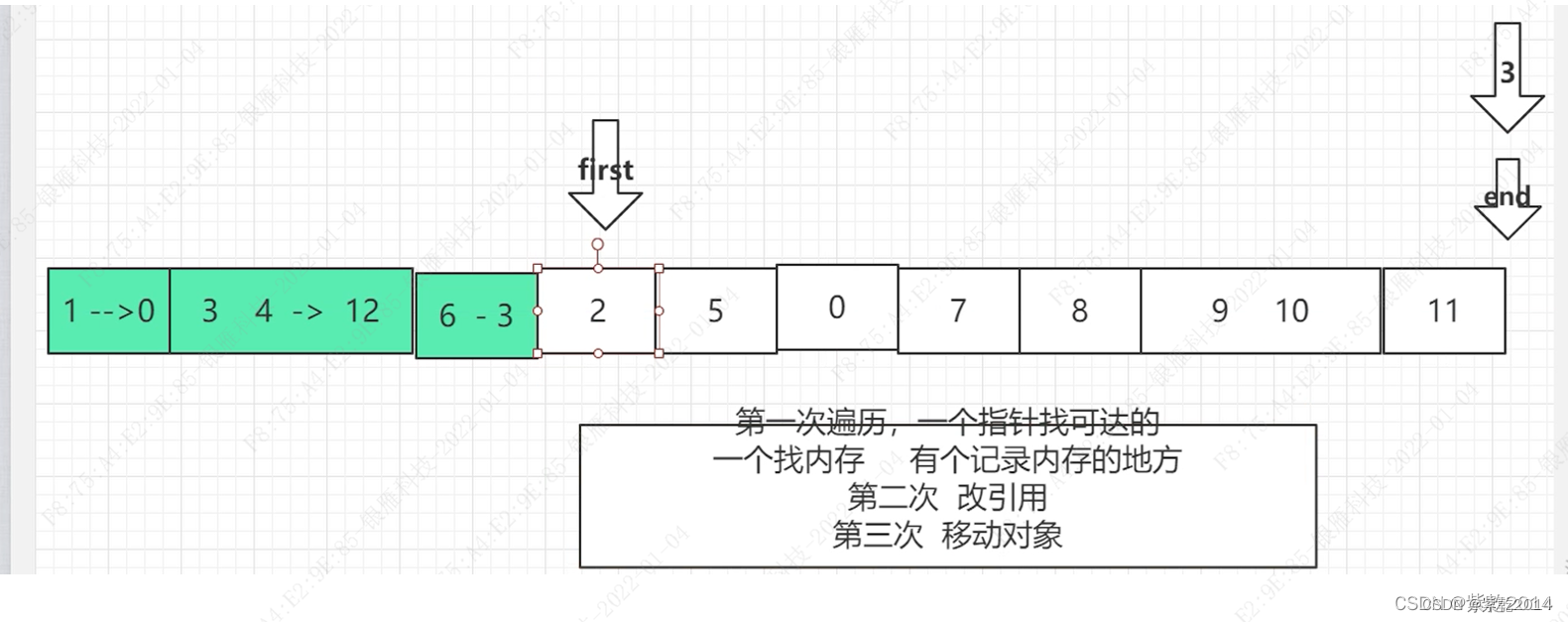
Lisp2会进行三次遍历,每次遍历内容如下:
第一次遍历,一个指针找空闲内存,一个指针找可达对象,一个指针固定在末尾处,找空闲对象的指针会在空闲处停下,找可达对象的指针会在空闲指针后面的可达对象记录该对象将要移动的位置,然后找空闲的指针和找可达对象的指针继续往后移动,直到找可达对象的指针移动到末尾处为止,该次遍历只是在可达对象中记录将要移动的位置,并不会进行对象移动。
第二次遍历,会对将要移动的可达对象的引用进行修改。
第三次遍历,移动可达对象。
优点:
Lisp2可以处理大小不同的对象
缺点:
Lisp2执行步骤较繁琐效率不高
注意:在需要移动的对象中会记录要移到的位置。
单次遍历算法: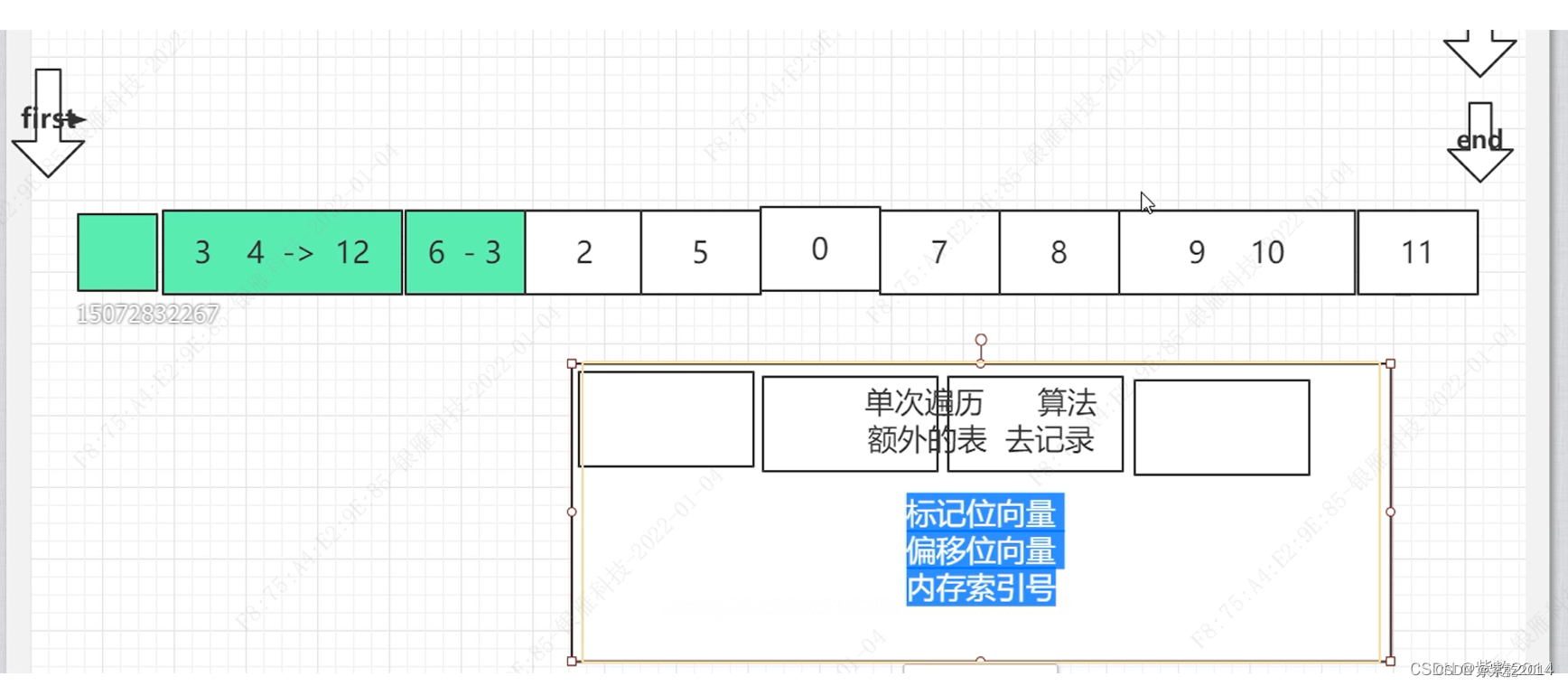
单次遍历也会用到三根指针,一根指针找空闲内存,一根指针找可达对象,一根指针固定在末尾处,找空闲对象的指针会在空闲处停下,找可达对象的指针会在空闲指针后面的可达对象停下,然后将该对象的内存索引号和该对象要移到的内存索引号、该对象的标记位向量(对象开始和结束位置)、偏移位向量(需要移到的位置只记录起始位置)等记录到额外的表中,然后找空闲的指针和找可达对象的指针继续往后移动,直到找可达对象的指针移动到末尾处为止。
遍历完成之后会根据表中的信息对可达对对象进行引用更新和移动。
2.4、分代收集算法
既然上面介绍了3中垃圾收集算法,那么在堆内存中到底用哪一个呢?
- Young区:标记复制算法。对象在被分配之后,可能生命周期比较短,Young区复制效率比较高。
- Old区:标记清除或标记整理。Old区对象存活时间比较长,复制来复制去没必要,不如做个标记再清理。
为什么要区分新生代和老年代?
当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将 java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。比如在新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。