前言
Keras序列模型建模的一般步骤:
(1)创建一个Sequential模型;
(2)根据需要,通过“add()”方法在模型中添加所需要的神经网络层, 完成模型构建;
(3)编译模型,通过“compile()”定义模型的训练模式;
(4)训练模型,通过“fit()”方法进行训练模型;
(5)评估模型,通过“evaluate()”进行模型评估;
(6)应用模型,通过“predict()”进行模型预测
1、载入数据
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
print("Tensorflow版本是:",tf.__version__)
mnist = tf.keras.datasets.mnist
(train_images,train_labels),(test_images,test_labels)=mnist.load_data()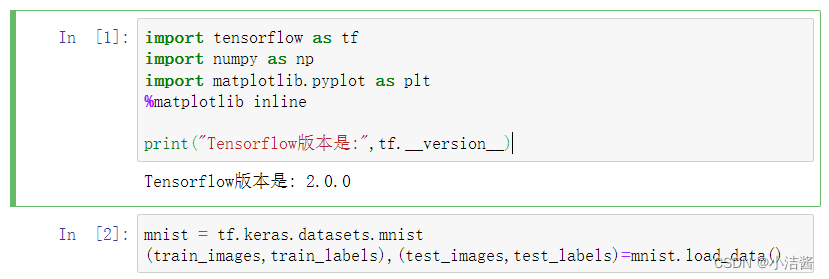
2、 特征数据归一化
train_images = train_images / 255.0
test_images = test_images / 255.03、标签数据独热编码
train_labels_ohe = tf.one_hot(train_labels,depth=10).numpy()
test_labels_ohe = tf.one_hot(test_labels,depth=10).numpy()4、新建一个序列模型

5、添加输入层 (平坦层,Flatten)

6、添加隐藏层(密集层,Dense)
model.add(tf.keras.layers.Dense(units=64,
kernel_initializer='normal',
activation='relu'))
model.add(tf.keras.layers.Dense(units=32,
kernel_initializer='normal',
activation='relu'))7、添加输出层(还是密集层)
model.add(tf.keras.layers.Dense(10,activation='softmax'))8、模型摘要
model.summary()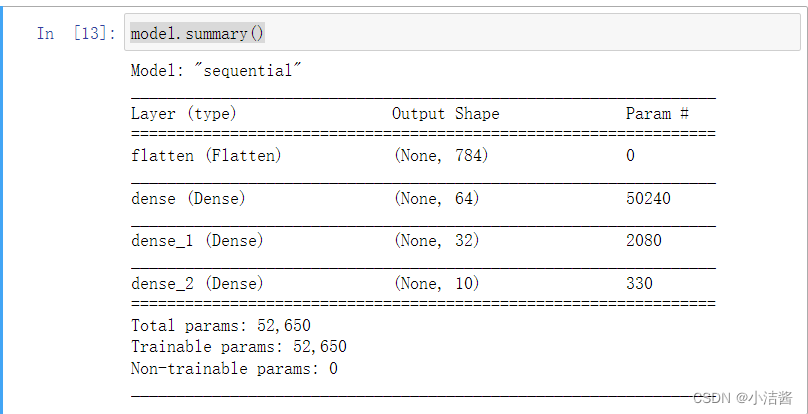
9、定义训练模式
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])tf.keras.Model.compile 接受 3 个重要的参数:
optimizer:优化器,可从 tf.keras.optimizers 中选择;
loss:损失函数,可从 tf.keras.losses 中选择;
metrics:评估指标,可从 tf.keras.metrics 中选择。
10、设置训练参数
train_epochs=10
batch_size=3011、模型训练
train_history=model.fit(train_images,train_labels_ohe,
validation_split=0.2,
epochs=train_epochs,
batch_size=batch_size,
verbose=2)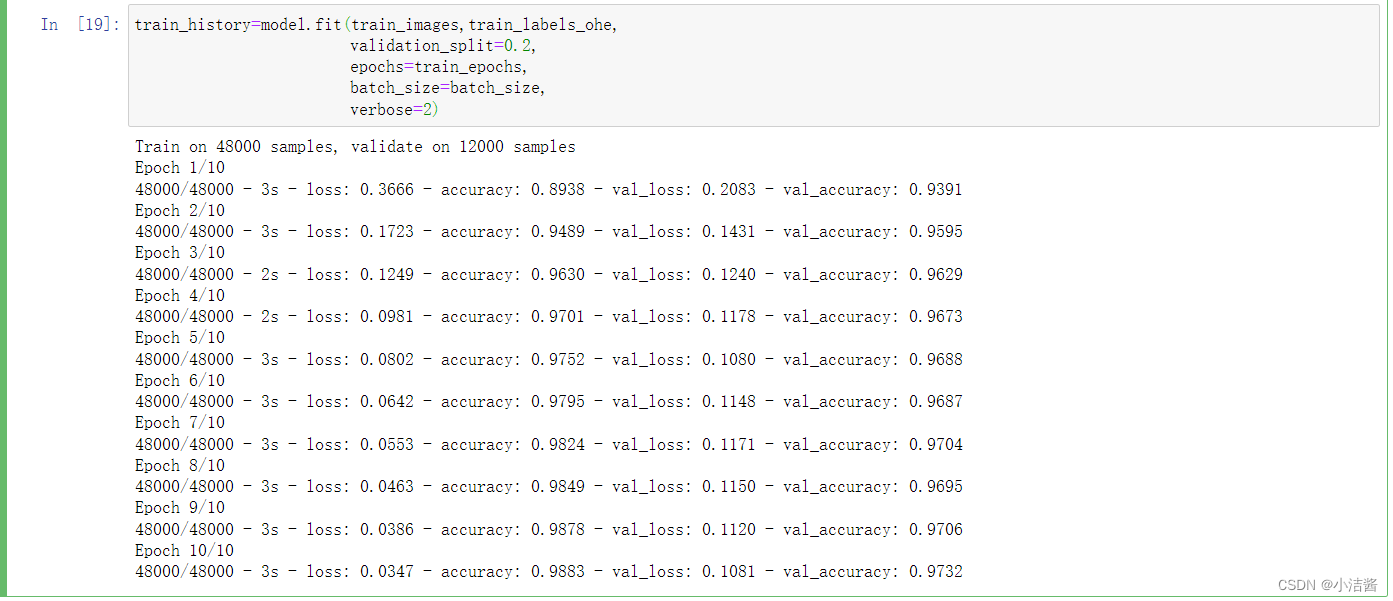
tf.keras.Model.fit()常见参数:
x:训练数据;
y:目标数据(数据标签);
epochs:将训练数据迭代多少遍;
batch_size:批次的大小;
validation_data:验证数据,可用于在训练过程中监控模型的性能。
verbose:训练过程的日志信息显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
12、训练过程指标数据
train_history.history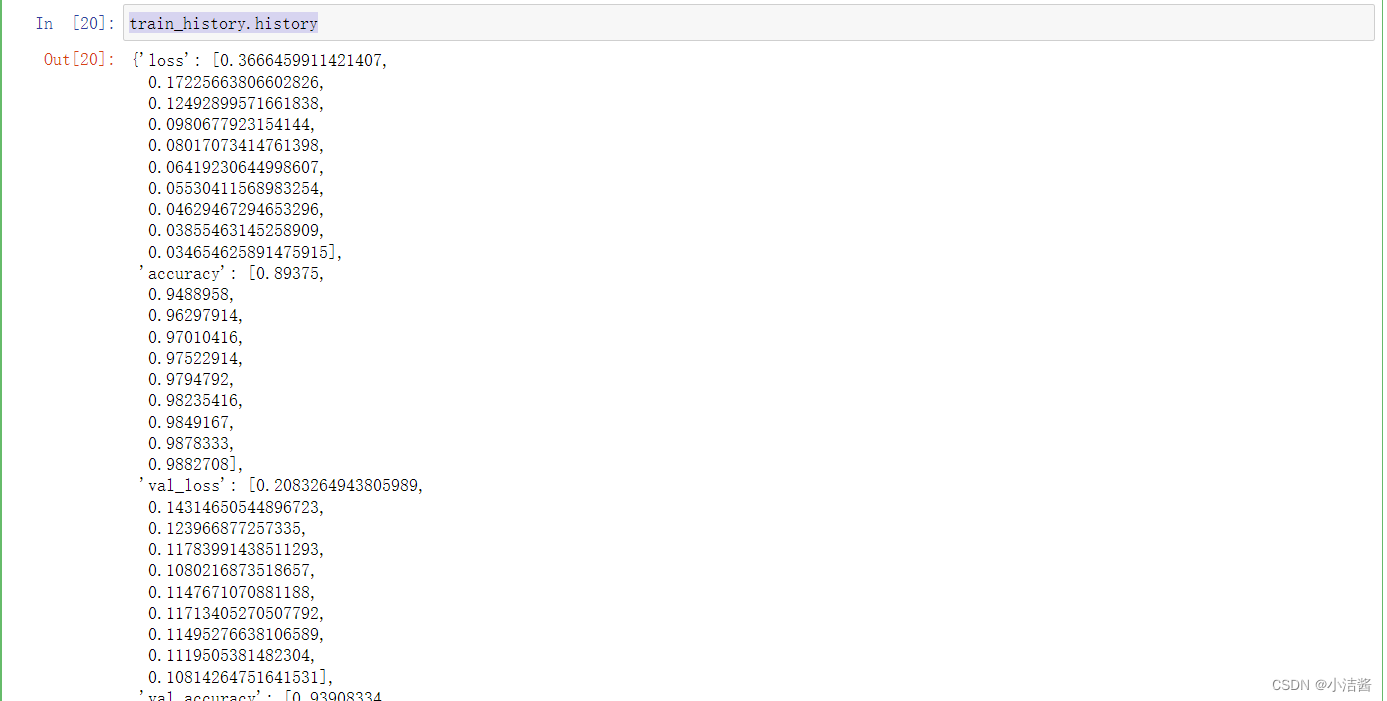
history是一个字典类型数据,包含了4个Key: loss、accuracy、val_loss和val_accuracy,分 别表示训练集上的损失、准确率和验证集上的损 失和准确率。 它们的值都是一个列表,记录了每个周期该指标 的具体数值。
13、训练过程指标可视化
import matplotlib.pyplot as plt
def show_train_history(train_history,train_metric,val_metric):
plt.plot(train_history.history[train_metric])
plt.plot(train_history.history[val_metric])
plt.title('Train History')
plt.ylabel(train_metric)
plt.xlabel('Epoch')
plt.legend(['train','validation'],loc='upper left')
plt.show()
show_train_history(train_history,'loss','val_loss')
show_train_history(train_history,'accuracy','val_accuracy')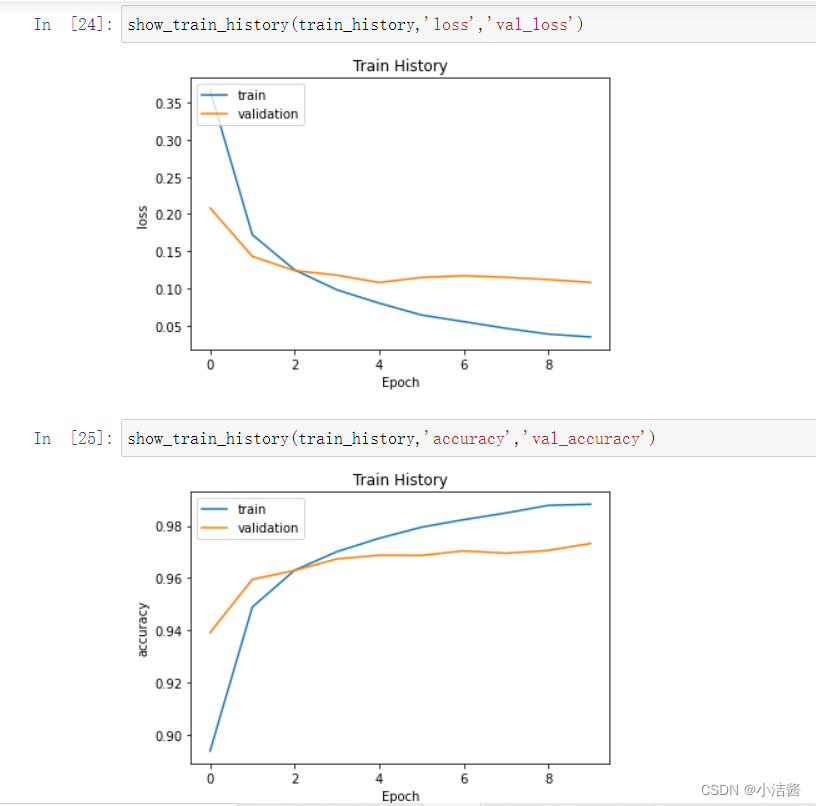
14、评估模型
test_loss,test_acc=model.evaluate(test_images,test_labels_ohe,verbose=2)

15、模型的度量指标
yy=model.evaluate(test_images,test_labels_ohe,verbose=2)
yy
model.metrics_names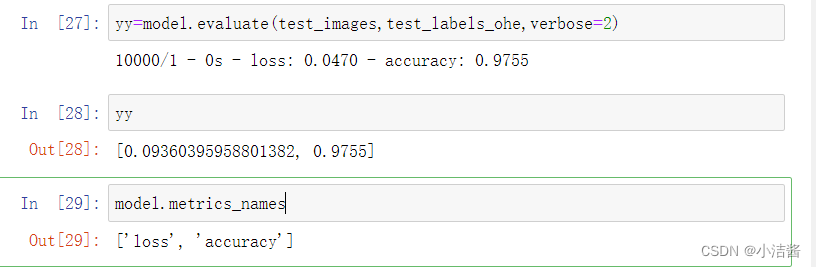
模型评估evaluate()的返回值是一个损失值的标量(如果没有指定其他度量指标), 或者是一个列表(如果指定了其他度量指标)。
16、应用模型
test_pred=model.predict(test_images)
test_pred.shape
np.argmax(test_pred[0])
test_pred=model.predict_classes(test_images)
test_pred[0]
test_labels[0]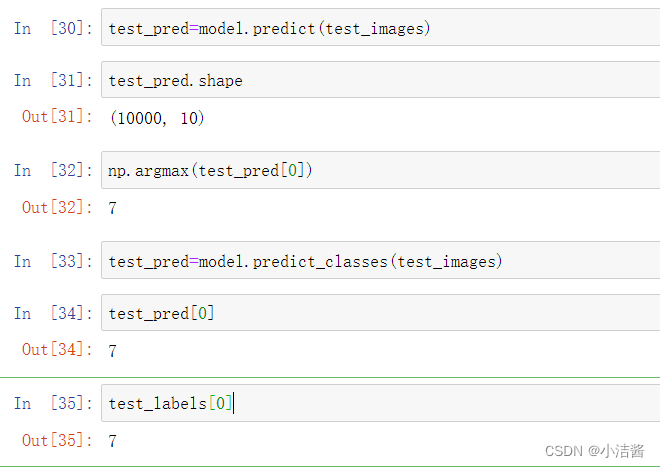
版权声明:本文为m0_59324564原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。