索引的本质:索引是帮助MySQL高效获取数据的排好序的数据结构
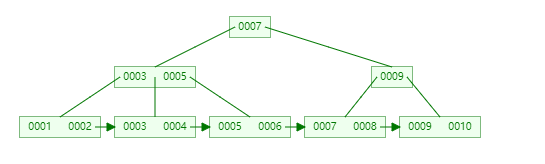
索引数据结构:B+Tree
非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
叶子节点包含所有的索引字段
叶子节点用指针连接,每个叶子节点都存储了相邻节点在磁盘中的存储位置。提高区间访问的性能
二叉树:当数据顺序排列时,会变成链表形式
红黑树:数据太多时树的高度太高,效率不一定高
Hash表:在B+树中找到索引,根据对哈希值的处理找到哈希表中对应的数据,缺点是范围查找效率低。B+树的叶子节点是已经排好序的。
mysql数据库中数据的存储位置
C:\ProgramData\MySQL\MySQL Server 5.5\Data\
或者根目录下的data文件夹中
MyISAM索引文件和数据文件是分离的(非聚集的)

先在索引文件中找到需要找的节点,这个节点中存储着数据在磁盘中的存储地址,然后定位到我们要找的数据
InnoDB索引实现(聚集)
表数据本身就是按照B+Tree组织的一个索引结构文件
聚集索引:叶节点包含了完整的数据记录(每一个叶节点中都有一条完整的数据信息)
联合索引:按照字段的创建顺序去比较索引的顺序
优化原则:索引最左前缀原理:按照索引的创建顺序来依次使用

select * from employees where name='bill' and age=30 select * from epployees where age=30 and position=''
第一个sql语句先按照name索引,再按照age索引查询
第二个sql语句索引不生效,因为直接使用第二个索引会找到很多值
为什么InnoDb表必须有主键,并且推荐使用整形的自增主键?
①为社么要有主键
因为InnoDb的索引是用B+树来维护的,如果我们没有创建主键,mysql就会自动去搜索每一列数据,看有没有重复,如果某一列没有重复数据,就用这一列的信息去维护B+树。如果每一列都有重复的数据,MYSQL就会自动生成一个列去维护B+树的结构,造成资源的浪费和性能的负担
②为什么要是整型
因为我们在找索引的时候需要比较很多次大小,整型比较起来比比较快,整型占用的空间小,节约空间
③为什么是自增
因为子节点是自增的,所以如果不按照顺序插入,可能会频繁导致树的平衡操作,会影响插入的性能
为什么非主键索引结构子节点存储的是主键值?(一致性和节省存储空间)