1.分析网站得知返回json的数据有图片的下载地址、评分和电影名
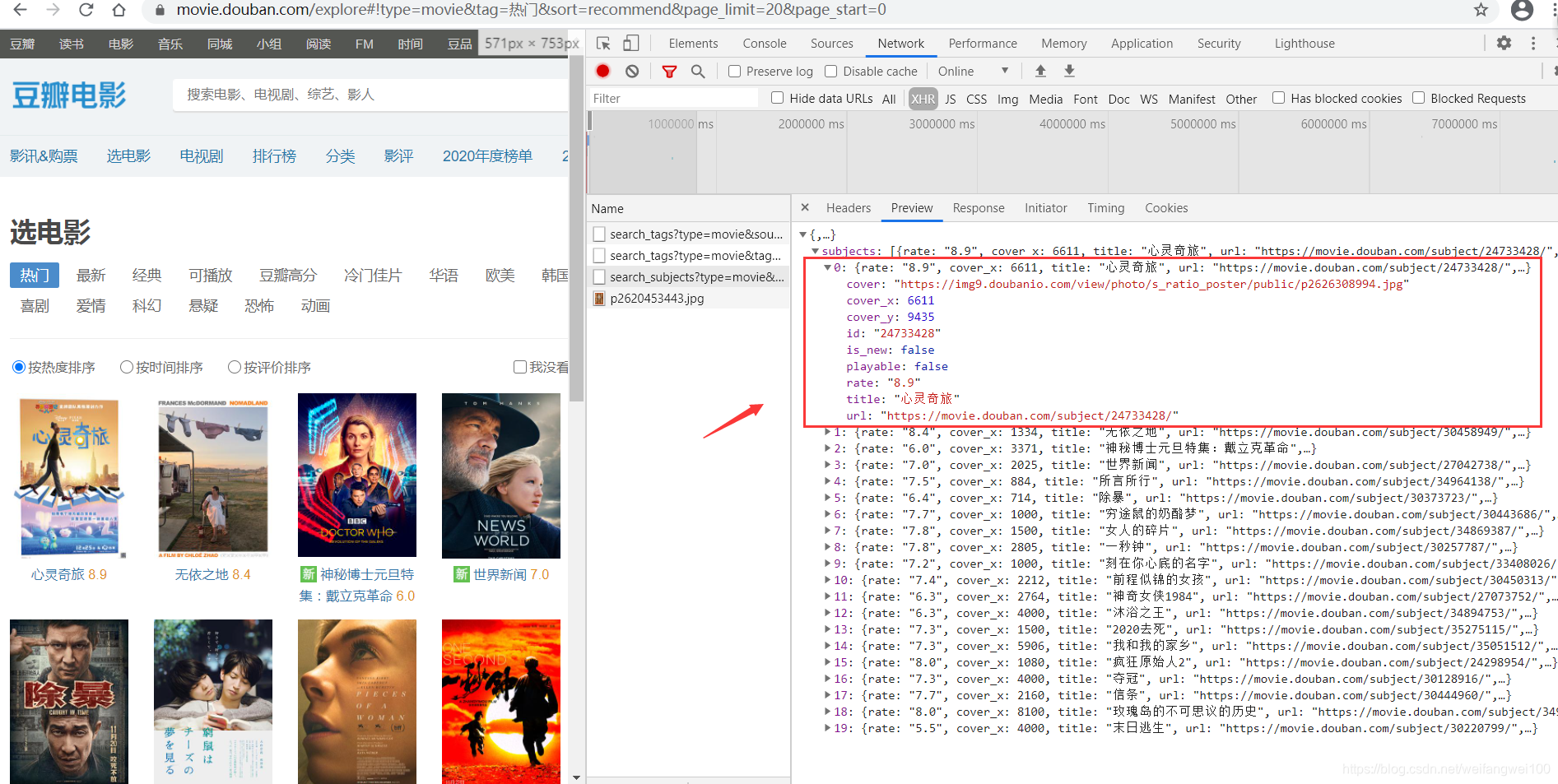
2.分析返回数据的url可以通过调整page_limit来得到更多的json数据

3.得到上面两点信息就好写爬虫了,代码如下:
#!/usr/bin/python3
#--coding:utf-8--
#@Author:nono
import requests
from fake_useragent import UserAgent
import time
from concurrent.futures import ThreadPoolExecutor,wait,ALL_COMPLETED
import os
#设置下载路径
download_path = './douban'
if os.path.exists(download_path):
pass
else:
os.mkdir(download_path)
#下载图片函数
def downloads(filename,img_url):
print(img_url, filename)
#请求获取图片
html=requests.get(img_url)
try:
#保存图片
with open(f'{download_path}/{filename}.jpg','wb') as f:
f.write(html.content)
print(f'下载{filename}图片成功')
except Exception as e:
print(e)
def main():
#设置头部信息
ua=UserAgent()
headers={
'User-Agent':ua.random
}
url='https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=200&page_start=0'
print(url)
req=requests.get(url,headers=headers,timeout=10)
#获取json数据
json_data=req.json()
# print(json_data)
#开启多线程
with ThreadPoolExecutor(max_workers=10) as executor:
futures=[]
for list in json_data['subjects']:
#每部电影的图片下载地址
img_url = list['cover']
#每部电影评分
filename = list['title'] + list['rate'] + '分'
future=executor.submit(downloads,filename,img_url)
futures.append(future)
#等待所有线程结束
wait(futures,return_when=ALL_COMPLETED)
if __name__ == '__main__':
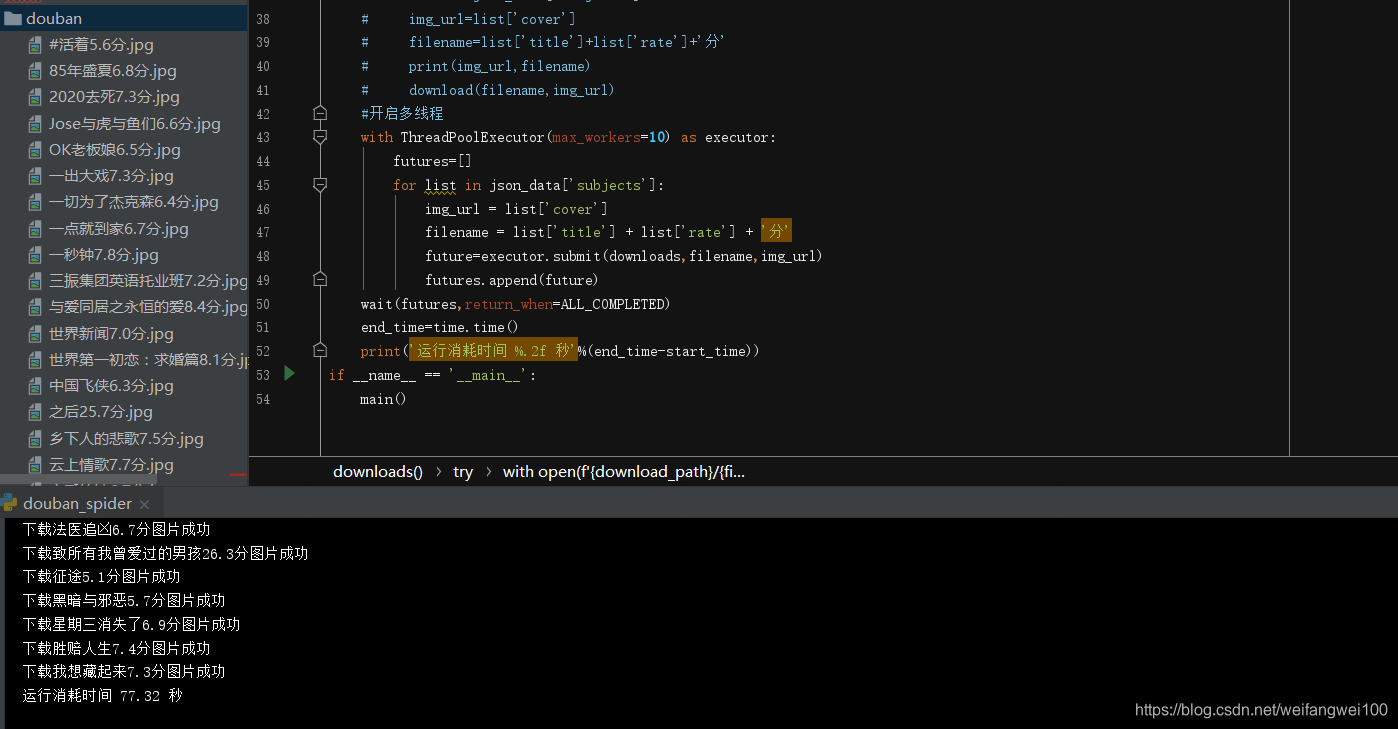
main()最后结果:
版权声明:本文为weifangwei100原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。