随机森林与Adaboost之间的区别
- 随机森林里的树为满二叉树
而Adaboost里的树为树桩(只有根节点和2个叶子节点)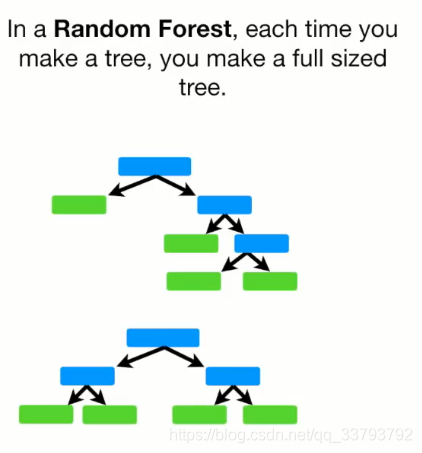
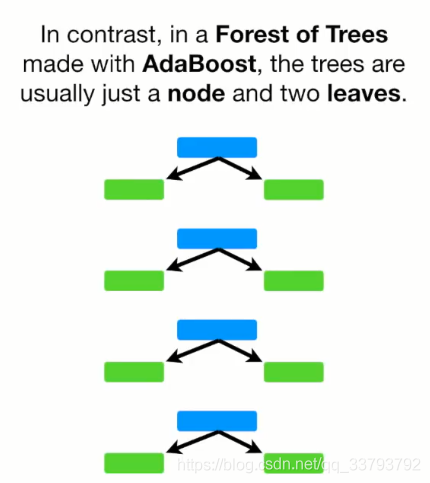
- 在进行预测时 随机森林中的每棵树拥有同样的话语权
而adaboost中每棵树的话语权都是不一样的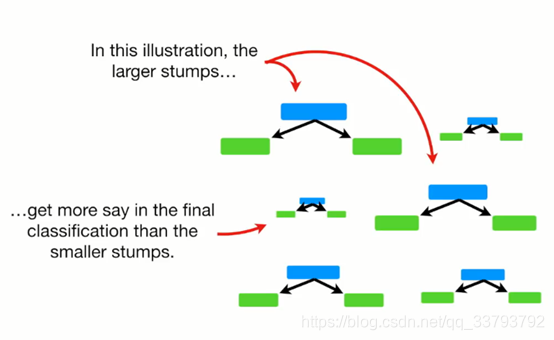
- 随机森林哪棵树先进行预测无所谓 但adaboost有影响
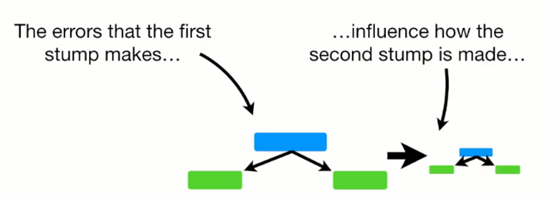
如何构造第一个弱分类器(树桩)
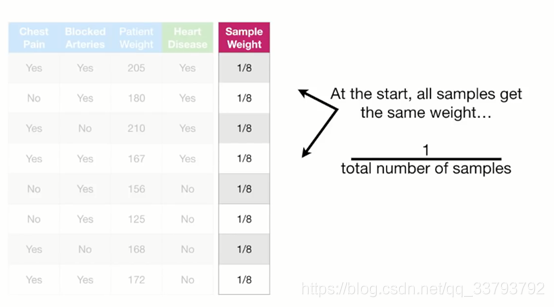
先给每个样本一个初始的权重=1/样本总数
确定选用哪个特征:Gini系数
分别计算左右两边的纯度:1-(预测正确的比例)2-(预测错误的比例)2 然后加权平均
例如Chest Pain这个特征:
左边:1-(3/5)2-(2/5)2=0.48
右边:1-(2/3)2-(1/3)2=0.44
加权平均:0.48*(5/8)+0.44*(3/8)=0.3+0.17=0.47
详情参看: 如何构建一棵决策树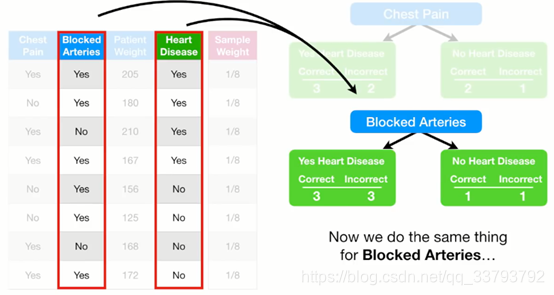

得到Gini系数 选最小的作为第一棵树桩
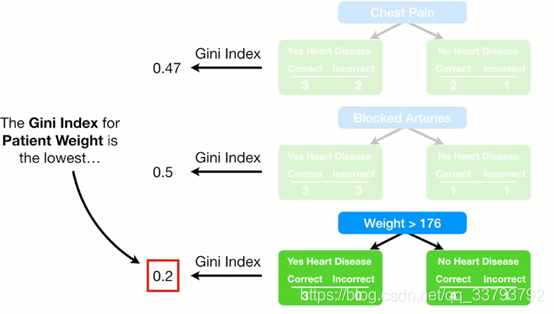
上面确定了树桩使用哪个特征 接下来要确定这个树桩(弱分类器)的话语权有多大 根据下面的公式:
那么Total Error指的是什么呢
它是错误样本权重(一开始都是一样)相加
因为 Weight>176只分错了一个 这个样本权重为1/8 所以Total Error就为1/8
带到公式 得到他的话语权为0.97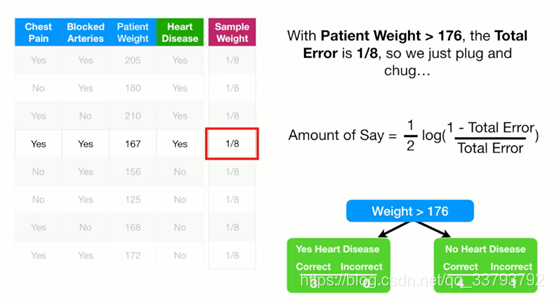
这样第一棵弱分类器就构造好了 然后我们需要更新各个样本的权重 使得分类正确的样本权重减小 错误的权重增大
我们根据下面的公式来改变错误样本的权重(amount of say = 0.97)
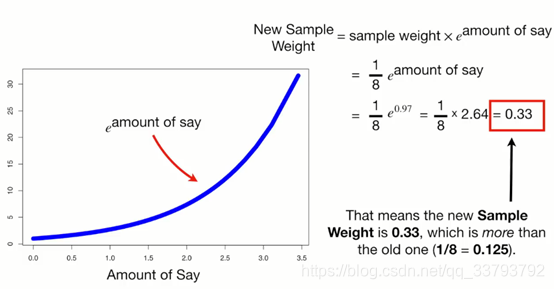
根据下面公式改变正确样本的权重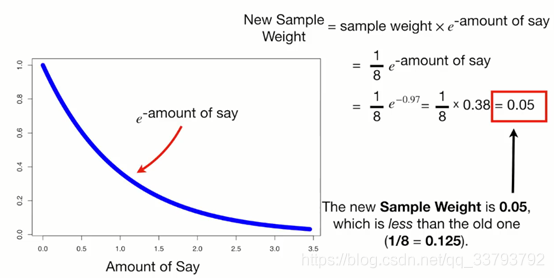
确定第一棵树桩后 样本权重更新成这样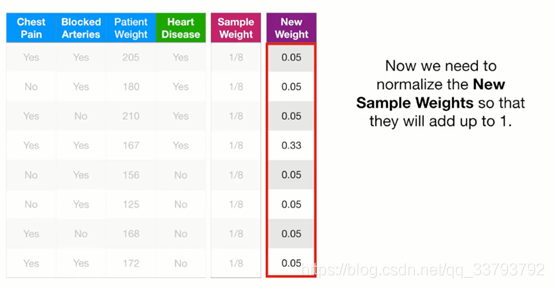
我们需要让这些权重合等于1(现在总和只为0.68) 所以我们进行归一化: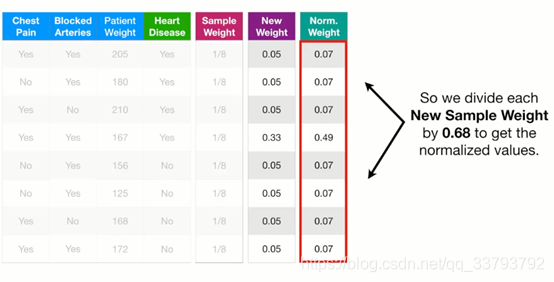
构造其他的弱分类器
- 第一个弱分类器已经构建好了
在随机森林中 我们每确认一棵树都是随机抽取样本来构造一个新的数据集 adaboost也一样 根据样本的权重和0-1之间的随机数 我们从源数据集中抽取样本 使它大小与原来的一致(可能会重复抽取):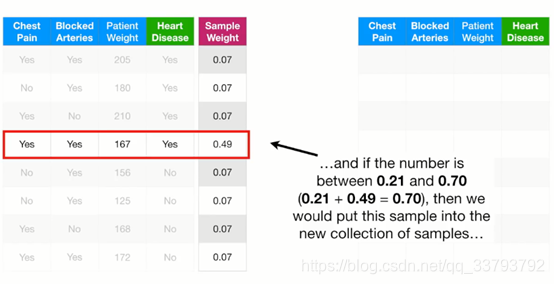
最终得到新的数据集: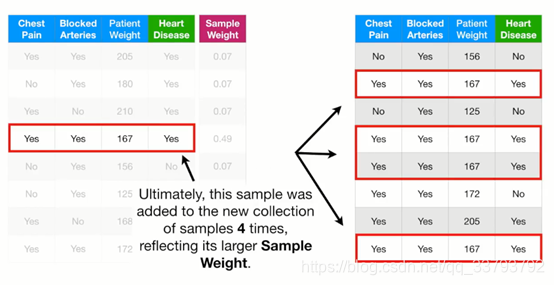
用他来做新的数据集 样本权重也要重置成初始状态:
接着按照构造第一个分类器的方法来构造剩下的分类器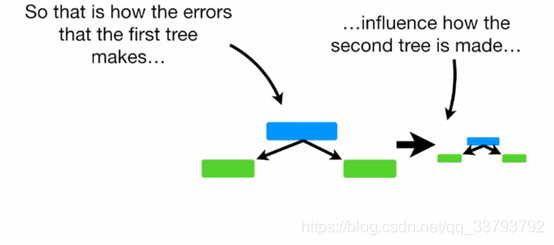
如何使用它来分类
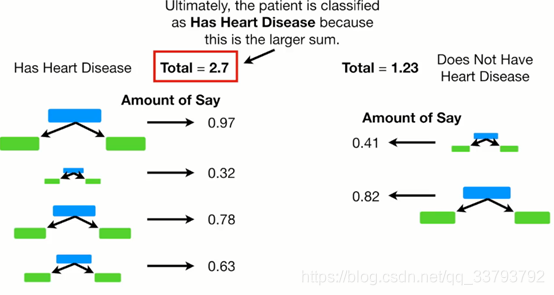
总结

版权声明:本文为qq_33793792原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。