编码问题
- 判断字符是否包含中文
\u4e00和\u9fa5是unicode编码,并且正好是中文编码的开始和结束的两个值,所以这个正则表达式可以用来判断字符串中是否包含中文。
s='版权声明:本文为CSDN博主的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。'.encode() #字符串转义
temp=s.decode('utf-8')
pattern="[\u4e00-\u9fa5]+"#中文正则表达式
reg = re.compile(pattern) #生成正则对象
results=reg.findall(temp)
for result in results:
print(result)
- 编码设为unicode
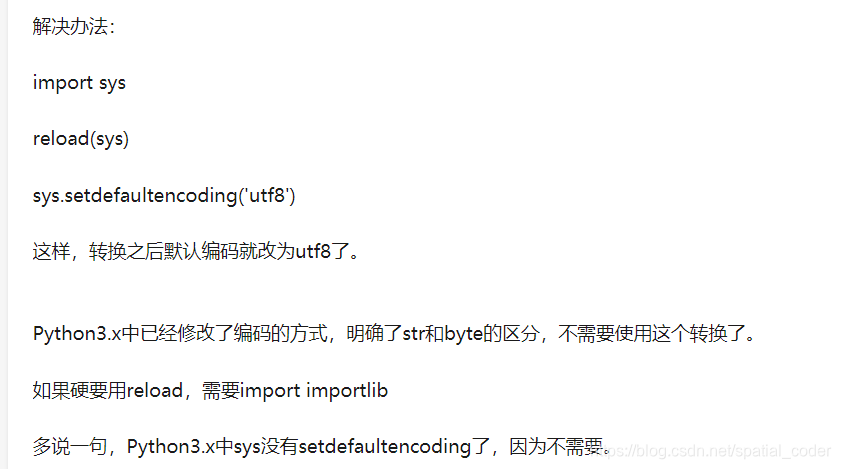
import importlib,sys
importlib.reload(sys)
分组匹配
(?P...)支持分组匹配。
s = '11022319900808666X'
res= re.search('(?P<省份>\d{3})(?P<城市>\d{3})(?P<born_year>\d{4})',s)
print(res.groupdict())#结果转为字典
输出结果为:
{‘省份’: ‘110’, ‘城市’: ‘223’, ‘born_year’: ‘1990’}
分组的回溯引用
引用之前分组的匹配,使用\N引用编号为N的分组。如匹配html标签,<\w+>.*?</\1>
相关资源
- 正则表达式在线测试网站
- tutorial网站含练习
介绍了各个正则符合的用法,配套练习题,适合零基础入门.
\.,为匹配一个句号,用\来转义.
括号的作用: 适用于只需要保留匹配到的字符串中括号内的字符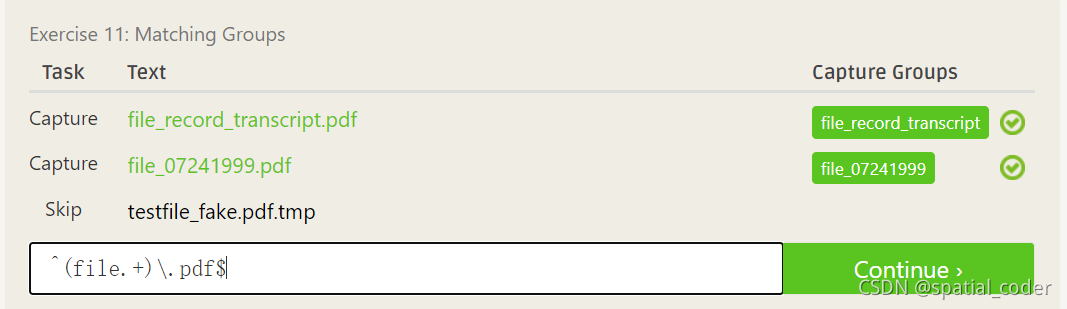
.+表示任意一个或多个字符,^表示开头,$表示结尾,\.pdf表示.pdf后缀结尾的文件,加斜杠对句号进行转义.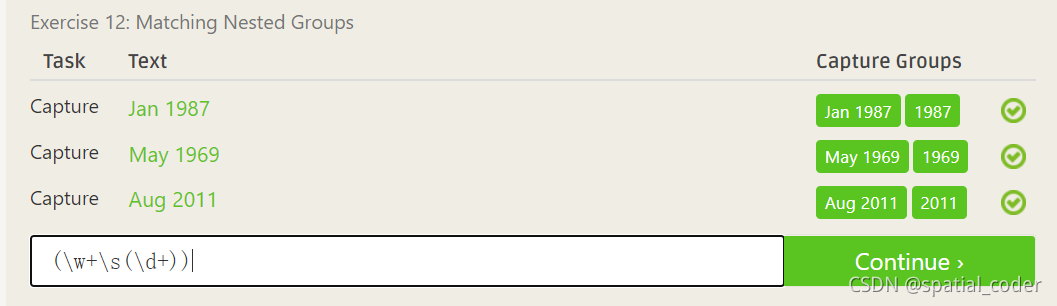
提取子组中的字符串,可以在括号组中添加括号.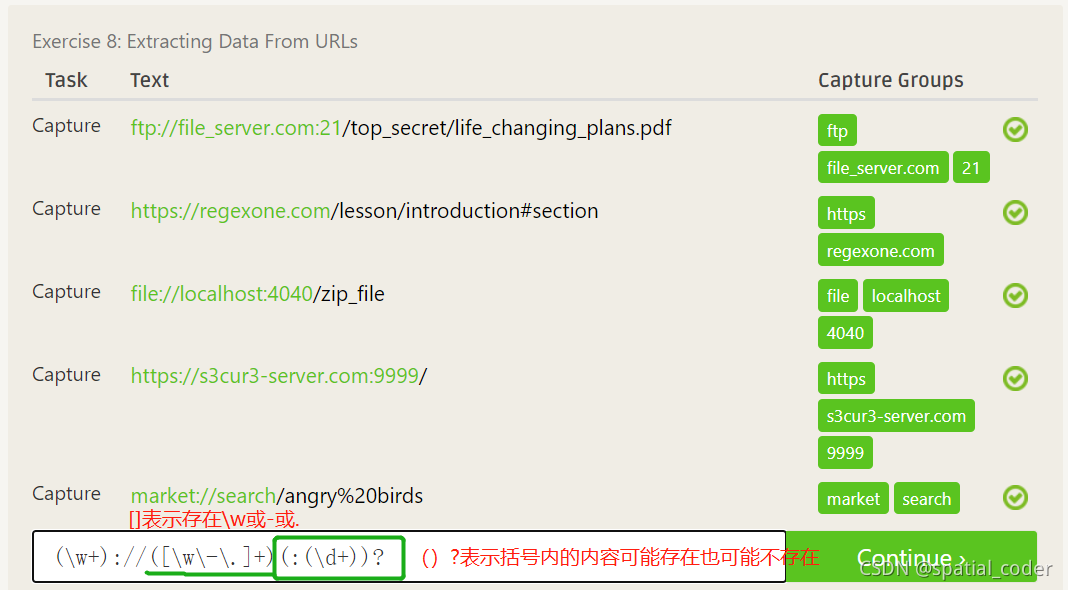
- 菜鸟教程
- 正则表达式30分钟入门
- regexlearn
- 编程胶囊
版权声明:本文为spatial_coder原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。